Proposal Details
This is a formal proposal for the addition of "encoding/json/v2" and "encoding/json/jsontext" packages that has previously been discussed in #63397.
This focuses on just the newly added API. An argument justifying the need for a v2 package can be found in prior discussion. Alternatively, you can watch the GopherCon talk entitled "The Future of JSON in Go".
Most of the API proposal below is copied from the discussion. If you've already read the discussion and only want to know what changed relative to the discussion, skip over to the "Changes from discussion" section.
This is the largest major revision of a standard Go package to date, so there will be many reasonable threads of further discussion. Before commenting, please check the list of sub-issues to see if your comment is better suited in a particular sub-issue. We'll be using sub-issues to isolate and focus discussion on particular topics.
Thank you to everyone who has been involved with the discussion, design review, code review, etc. This proposal is better off because of all your feedback.
This proposal was written with feedback from @mvdan, @johanbrandhorst, @rogpeppe, @chrishines, @neild, and @rsc.
Overview
In general, we propose the addition of the following: * Package "encoding/json/jsontext", which handles processing of JSON purely at a syntactic layer (with no dependencies on Go reflection). This is a lower-level package that most users will not use, but still sufficiently useful to expose as a standalone package. * Package "encoding/json/v2", which will serve as the second major version of the v1 "encoding/json" package. It is implemented in terms of "jsontext". * Options in v1 "encoding/json" to provide inter-operability with v2. The v1 package will be implemented entirely in terms of "json/v2".
JSON serialization can be broken down into two primary components:
- syntactic functionality that is concerned with processing JSON based on its grammar, and
- semantic functionality that determines the meaning of JSON values as Go values and vice-versa.
We use the terms "encode" and "decode" to describe syntactic functionality and the terms "marshal" and "unmarshal" to describe semantic functionality.
We aim to provide a clear distinction between functionality that is purely concerned with encoding versus that of marshaling. For example, it should be possible to encode a stream of JSON tokens without needing to marshal a concrete Go value representing them. Similarly, it should be possible to decode a stream of JSON tokens without needing to unmarshal them into a concrete Go value.
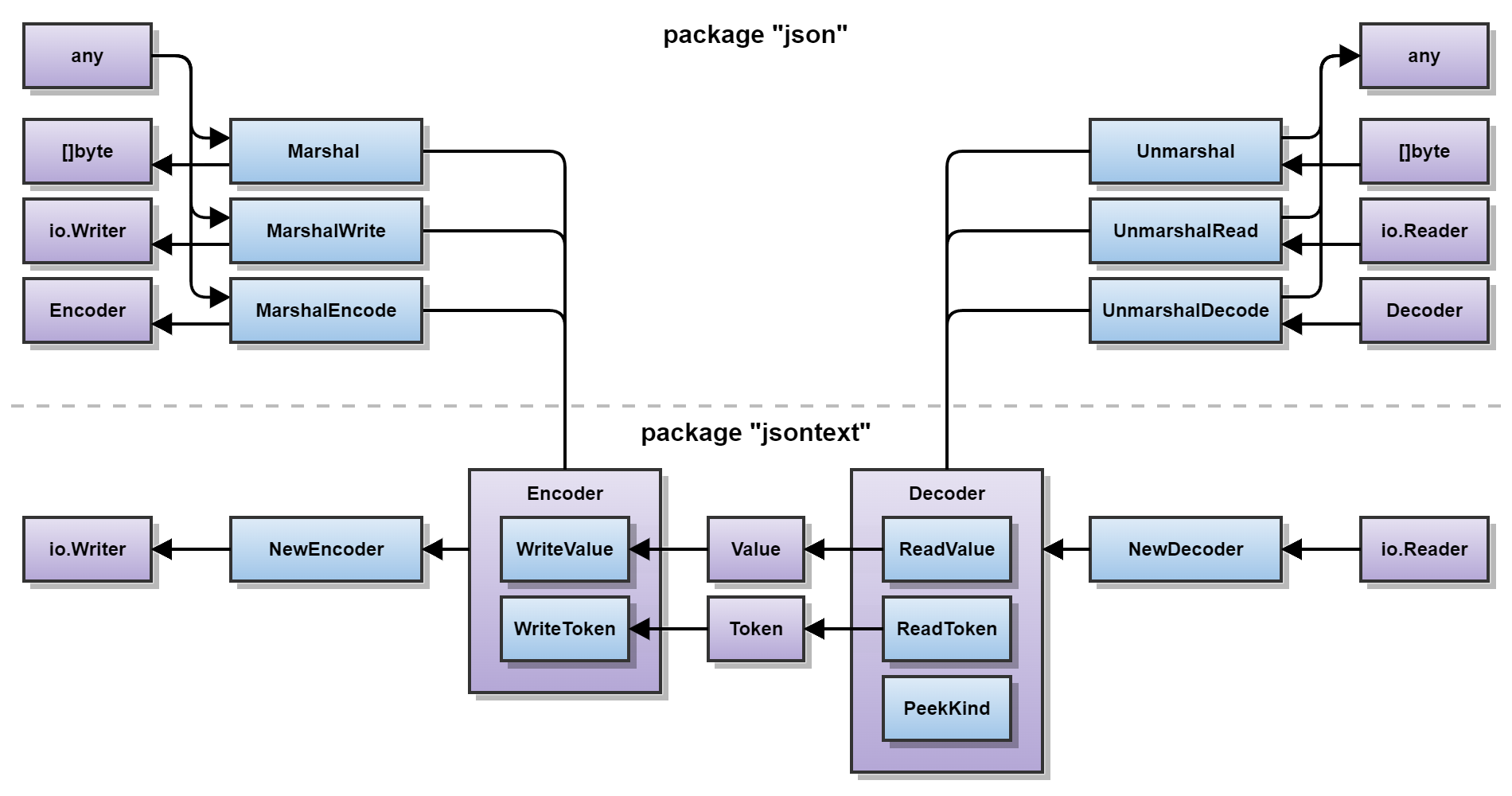
This diagram provides a high-level overview of the v2 API. Purple blocks represent types, while blue blocks represent functions or methods. The direction of the arrows represent the approximate flow of data. The bottom half (as implemented by the "jsontext" package) of the diagram contains functionality that is only concerned with syntax, while the upper half (as implemented by the "json" package) contains functionality that assigns semantic meaning to syntactic data handled by the bottom half.
Package "encoding/json/jsontext"
The jsontext package provides functionality to process JSON purely according to the grammar.
Overview
The basic API consists of the following:
package jsontext // "encoding/json/jsontext"
type Encoder struct { /* no exported fields */ }
func NewEncoder(io.Writer, ...Options) *Encoder
func (*Encoder) WriteToken(Token) error
func (*Encoder) WriteValue(Value) error
type Decoder struct { /* no exported fields */ }
func NewDecoder(io.Reader, ...Options) *Decoder
func (*Decoder) PeekKind() Kind
func (*Decoder) ReadToken() (Token, error)
func (*Decoder) ReadValue() (Value, error)
func (*Decoder) SkipValue() error
type Kind byte
type Token struct { /* no exported fields */ }
func (Token) Kind() Kind
type Value []byte
func (Value) Kind() Kind
Tokens and Values
The primary data types for interacting with JSON are Kind, Token, and Value.
The Kind is an enumeration that describes the kind of a token or value.
// Kind represents each possible JSON token kind with a single byte,
// which is the first byte of that kind's grammar:
// - 'n': null
// - 'f': false
// - 't': true
// - '"': string
// - '0': number
// - '{': object start
// - '}': object end
// - '[': array start
// - ']': array end
type Kind byte
func (k Kind) String() string
At present, there are no constants declared for individual kinds since each value is humanly readable. Declaring constants will lead to inconsistent usage where some users use the 'n' byte literal, while other users reference the jsontext.KindNull constant. This is a similar problem to the introduction of the http.MethodGet constant, which has led to inconsistency in codebases where the "GET" literal is more frequently used (~75% of the time).
A Token represents a lexical JSON token, which cannot represent entire array or object values. It is analogous to the v1 Token type, but is designed to be allocation-free by being an opaque struct type.
type Token struct { /* no exported fields */ }
var (
Null Token = rawToken("null")
False Token = rawToken("false")
True Token = rawToken("true")
ObjectStart Token = rawToken("{")
ObjectEnd Token = rawToken("}")
ArrayStart Token = rawToken("[")
ArrayEnd Token = rawToken("]")
)
func Bool(b bool) Token
func Int(n int64) Token
func Uint(n uint64) Token
func Float(n float64) Token
func String(s string) Token
func (t Token) Clone() Token
func (t Token) Bool() bool
func (t Token) Int() int64
func (t Token) Uint() uint64
func (t Token) Float() float64
func (t Token) String() string
func (t Token) Kind() Kind
A Value is the raw representation of a single JSON value so, unlike Token, can also represent entire array or object values. It is analogous to the v1 RawMessage type.
type Value []byte
func (v Value) Clone() Value
func (v Value) String() string
func (v Value) IsValid(opts ...Options) bool
func (v *Value) Format(opts ...Options) error
func (v *Value) Compact(opts ...Options) error
func (v *Value) Indent(opts ...Options) error
func (v *Value) Canonicalize(opts ...Options) error
func (v Value) MarshalJSON() ([]byte, error)
func (v *Value) UnmarshalJSON(b []byte) error
func (v Value) Kind() Kind // never ']' or '}' if valid
By default, IsValid validates according to RFC 7493, but accepts options to validate according to looser guarantees (such as allowing duplicate names or invalid UTF-8).
The Format method formats the value according to the specified encoder options.
The Compact and Indent methods operate similar to the v1 Compact and Indent functions.
The Canonicalize method canonicalizes the JSON value according to the JSON Canonicalization Scheme as defined in RFC 8785.
The Compact, Indent, and Canonicalize each call Format with a default list of options. The caller may provide additional options to override the defaults.
Formatting
Some top-level functions are provided for formatting JSON values and strings.
// AppendFormat formats the JSON value in src and appends it to dst
// according to the specified options.
// See [Value.Format] for more details about the formatting behavior.
func AppendFormat(dst, src []byte, opts ...Options) ([]byte, error)
// AppendQuote appends a double-quoted JSON string literal representing src
// to dst and returns the extended buffer.
func AppendQuote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)
// AppendUnquote appends the decoded interpretation of src as a
// double-quoted JSON string literal to dst and returns the extended buffer.
// The input src must be a JSON string without any surrounding whitespace.
func AppendUnquote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)
Encoder and Decoder
The Encoder and Decoder types provide the functionality for encoding to or decoding from an io.Writer or an io.Reader. An Encoder or Decoder can be constructed with NewEncoder or NewDecoder using default options.
The Encoder is a streaming encoder from raw JSON tokens and values. It is used to write a stream of top-level JSON values, each terminated with a newline character.
type Encoder struct { /* no exported fields */ }
func NewEncoder(w io.Writer, opts ...Options) *Encoder
func (e *Encoder) Reset(w io.Writer, opts ...Options)
// WriteToken writes the next token and advances the internal write offset.
// The provided token must be consistent with the JSON grammar.
func (e *Encoder) WriteToken(t Token) error
// WriteValue writes the next raw value and advances the internal write offset.
// The provided value must be consistent with the JSON grammar.
func (e *Encoder) WriteValue(v Value) error
// UnusedBuffer returns a zero-length buffer with a possible non-zero capacity.
// This buffer is intended to be used to populate a Value
// being passed to an immediately succeeding WriteValue call.
//
// Example usage:
//
// b := d.UnusedBuffer()
// b = append(b, '"')
// b = appendString(b, v) // append the string formatting of v
// b = append(b, '"')
// ... := d.WriteValue(b)
func (e *Encoder) UnusedBuffer() []byte
// OutputOffset returns the current output byte offset, which is the location
// of the next byte immediately after the most recently written token or value.
func (e *Encoder) OutputOffset() int64
The Decoder is a streaming decoder for raw JSON tokens and values. It is used to read a stream of top-level JSON values, each separated by optional whitespace characters.
type Decoder struct { /* no exported fields */ }
func NewDecoder(r io.Reader, opts ...Options) *Decoder
func (d *Decoder) Reset(r io.Reader, opts ...Options)
// PeekKind returns the kind of the token that would be returned by ReadToken.
// It does not advance the read offset.
func (d *Decoder) PeekKind() Kind
// ReadToken reads the next Token, advancing the read offset.
// The returned token is only valid until the next Peek, Read, or Skip call.
// It returns io.EOF if there are no more tokens.
func (d *Decoder) ReadToken() (Token, error)
// ReadValue returns the next raw JSON value, advancing the read offset.
// The returned value is only valid until the next Peek, Read, or Skip call
// and may not be mutated while the Decoder remains in use.
// It returns io.EOF if there are no more values.
func (d *Decoder) ReadValue() (Value, error)
// SkipValue is equivalent to calling ReadValue and discarding the result except
// that memory is not wasted trying to hold the entire value.
func (d *Decoder) SkipValue() error
// UnreadBuffer returns the data remaining in the unread buffer.
// The returned buffer must not be mutated while Decoder continues to be used.
// The buffer contents are valid until the next Peek, Read, or Skip call.
func (d *Decoder) UnreadBuffer() []byte
// InputOffset returns the current input byte offset, which is the location
// of the next byte immediately after the most recently returned token or value.
func (d *Decoder) InputOffset() int64
Some methods common to both Encoder and Decoder report information about the current automaton state.
// StackDepth returns the depth of the state machine.
// Each level on the stack represents a nested JSON object or array.
// It is incremented whenever an ObjectStart or ArrayStart token is encountered
// and decremented whenever an ObjectEnd or ArrayEnd token is encountered.
// The depth is zero-indexed, where zero represents the top-level JSON value.
func (e *Encoder) StackDepth() int
func (d *Decoder) StackDepth() int
// StackIndex returns information about the specified stack level.
// It must be a number between 0 and StackDepth, inclusive.
// For each level, it reports the kind:
//
// - 0 for a level of zero,
// - '{' for a level representing a JSON object, and
// - '[' for a level representing a JSON array.
//
// It also reports the length so far of that JSON object or array.
// Each name and value in a JSON object is counted separately,
// so the effective number of members would be half the length.
// A complete JSON object must have an even length.
func (e *Encoder) StackIndex(i int) (Kind, int64)
func (d *Decoder) StackIndex(i int) (Kind, int64)
// StackPointer returns a JSON Pointer (RFC 6901) to the most recently handled value.
func (e *Encoder) StackPointer() Pointer
func (d *Decoder) StackPointer() Pointer
Options
The behavior of Encoder and Decoder may be altered by passing options to NewEncoder and NewDecoder, which take in a variadic list of options.
type Options = jsonopts.Options
// AllowDuplicateNames specifies that JSON objects may contain
// duplicate member names.
func AllowDuplicateNames(v bool) Options // affects encode and decode
// AllowInvalidUTF8 specifies that JSON strings may contain invalid UTF-8,
// which will be mangled as the Unicode replacement character, U+FFFD.
func AllowInvalidUTF8(v bool) Options // affects encode and decode
// CanonicalizeRawFloats specifies that when encoding a raw JSON floating-point number
// (i.e., a number with a fraction or exponent) in a [Token] or [Value],
// the number is canonicalized according to RFC 8785, section 3.2.2.3.
func CanonicalizeRawFloats(v bool) Options // affects encode only
// CanonicalizeRawInts specifies that when encoding a raw JSON integer number
// (i.e., a number without a fraction and exponent) in a [Token] or [Value],
// the number is canonicalized according to RFC 8785, section 3.2.2.3.
func CanonicalizeRawInts(v bool) Options // affects encode only
// PreserveRawStrings specifies that when encoding a raw JSON string
// in a [Token] or [Value], pre-escaped sequences in a JSON string
// are preserved to the output.
func PreserveRawStrings(v bool) Options // affects encode only
// ReorderRawObjects specifies that when encoding a raw JSON object in a [Value],
// the object members are reordered according to RFC 8785, section 3.2.3.
func ReorderRawObjects(v bool) Options // affects encode only
// EscapeForHTML specifies that '<', '>', and '&' characters within JSON strings
// should be escaped as a hexadecimal Unicode codepoint (e.g., \u003c)
// so that the output is safe to embed within HTML.
func EscapeForHTML(v bool) Options // affects encode only
// EscapeForJS specifies that U+2028 and U+2029 characters within JSON strings
// should be escaped as a hexadecimal Unicode codepoint (e.g., \u2028)
// so that the output is valid to embed within JavaScript.
// See RFC 8259, section 12.
func EscapeForJS(v bool) Options // affects encode only
// Multiline specifies that the JSON output should be expanded, where
// every JSON object member or JSON array element appears on a new, indented line
// according to the nesting depth.
// If an indent is not already specified, then it defaults to using "\t".
func Multiline(v bool) Options // affects encode only
// WithIndent specifies that the encoder should emit multiline output
// where each element in a JSON object or array begins on a new, indented line
// beginning with the indent prefix (see WithIndentPrefix) followed by
// one or more copies of indent according to the nesting depth.
func WithIndent(indent string) Options // affects encode only
// WithIndentPrefix specifies that the encoder should emit multiline output
// where each element in a JSON object or array begins on a new, indented line
// beginning with the indent prefix followed by
// one or more copies of indent (see WithIndent) according to the nesting depth.
func WithIndentPrefix(prefix string) Options // affects encode only
// SpaceAfterColon specifies that the JSON output should emit a space character
// after each colon separator following a JSON object name.
func SpaceAfterColon(v bool) Options // affects encode only
// SpaceAfterComma specifies that the JSON output should emit a space character
// after each comma separator following a JSON object value or array element.
func SpaceAfterComma(v bool) Options // affects encode only
The Options type is a type alias to an internal type that is an interface type with no exported methods. It is used simply as a marker type for options declared in the "json" and "jsontext" packages.
Latter options specified in the variadic list passed to NewEncoder and NewDecoder take precedence over prior option values. For example, NewEncoder(AllowInvalidUTF8(false), AllowInvalidUTF8(true)) results in AllowInvalidUTF8(true) taking precedence.
Options that do not affect the operation in question are ignored. For example, passing Multiline to NewDecoder does nothing.
The WithIndent and WithIndentPrefix flags configure the appearance of whitespace in the output. Their semantics are identical to the v1 Encoder.SetIndent method.
Errors
Errors due to non-compliance with the JSON grammar are reported as a SyntacticError.
type SyntacticError struct {
// ByteOffset indicates that an error occurred after this byte offset.
ByteOffset int64
// JSONPointer indicates that an error occurred within this JSON value
// as indicated using the JSON Pointer notation (see RFC 6901).
JSONPointer Pointer
// Err is the underlying error.
Err error // always non-nil
}
func (e *SyntacticError) Error() string
func (e *SyntacticError) Unwrap() error
Errors due to I/O are returned as an opaque error that unwrap to the original error returned by the failing io.Reader.Read or io.Writer.Write call.
// ErrDuplicateName indicates that a JSON token could not be
// encoded or decoded because it results in a duplicate JSON object name.
var ErrDuplicateName = errors.New("duplicate object member name")
// ErrNonStringName indicates that a JSON token could not be
// encoded or decoded because it is not a string,
// as required for JSON object names according to RFC 8259, section 4.
var ErrNonStringName = errors.New("object member name must be a string")
ErrDuplicateName and ErrNonStringName are sentinel errors that are
returned while being wrapped within a SyntacticError.
// Pointer is a JSON Pointer (RFC 6901) that references a particular JSON value
// relative to the root of the top-level JSON value.
//
// A Pointer is a slash-separated list of tokens, where each token is
// either a JSON object name or an index to a JSON array element
// encoded as a base-10 integer value.
type Pointer string
// IsValid reports whether p is a valid JSON Pointer according to RFC 6901.
func (p Pointer) IsValid() bool
// AppendToken appends a token to the end of p and returns the full pointer.
func (p Pointer) AppendToken(tok string) Pointer
// Parent strips off the last token and returns the remaining pointer.
func (p Pointer) Parent() Pointer
// Contains reports whether the JSON value that p points to
// is equal to or contains the JSON value that pc points to.
func (p Pointer) Contains(pc Pointer) bool
// LastToken returns the last token in the pointer.
func (p Pointer) LastToken() string
// Tokens returns an iterator over the reference tokens in the JSON pointer.
func (p Pointer) Tokens() iter.Seq[string]
Pointer is a named type representing a JSON Pointer (RFC 6901) and references a particular JSON value relative to a top-level JSON value. It is primarily used for error reporting, but its utility could be expanded in the future (e.g. extracting or modifying a portion of a Value by Pointer reference alone).
Package "encoding/json/v2"
The v2 "json" package provides functionality to marshal or unmarshal JSON data from or into Go value types. This package depends on "jsontext" to process JSON text and the "reflect" package to dynamically introspect Go values at runtime.
Most users will interact directly with the "json" package without ever needing to interact with the lower-level "jsontext package.
Overview
The basic API consists of the following:
package json // "encoding/json/v2"
func Marshal(in any, opts ...Options) (out []byte, err error)
func MarshalWrite(out io.Writer, in any, opts ...Options) error
func MarshalEncode(out *jsontext.Encoder, in any, opts ...Options) error
func Unmarshal(in []byte, out any, opts ...Options) error
func UnmarshalRead(in io.Reader, out any, opts ...Options) error
func UnmarshalDecode(in *jsontext.Decoder, out any, opts ...Options) error
The Marshal and Unmarshal functions mostly match the signature of the same functions in v1, however their behavior differs.
The MarshalWrite and UnmarshalRead functions are equivalent functionality that operate on an io.Writer and io.Reader instead of []byte. The UnmarshalRead function consumes the entire input until io.EOF and reports an error if any invalid tokens appear after the end of the JSON value (#36225).
The MarshalEncode and UnmarshalDecode functions are equivalent functionality that operate on an *jsontext.Encoder and *jsontext.Decoder instead of []byte. Unlike UnmarshalRead, UnmarshalDecode does not read until io.EOF, allowing successive calls to process each JSON value as a stream.
All marshal and unmarshal functions accept a variadic list of options that configure the behavior of serialization.
Default behavior
The marshal and unmarshal logic in v2 is mostly identical to v1 with following changes:
-
In v1, JSON object members are unmarshaled into a Go struct using a case-insensitive name match with the JSON name of the fields. In contrast, v2 matches fields using an exact, case-sensitive match. The
MatchCaseInsensitiveNamesandjsonv1.MatchCaseSensitiveDelimiteroptions control this behavior difference. To explicitly specify a Go struct field to use a particular name matching scheme, either thenocaseor thestrictcasefield option can be specified. Field-specified options take precedence over caller-specified options. -
In v1, when marshaling a Go struct, a field marked as
omitemptyis omitted if the field value is an "empty" Go value, which is defined as false, 0, a nil pointer, a nil interface value, and any empty array, slice, map, or string. In contrast, v2 redefinesomitemptyto omit a field if it encodes as an "empty" JSON value, which is defined as a JSON null, or an empty JSON string, object, or array. Thejsonv1.OmitEmptyWithLegacyDefinitionoption controls this behavior difference. Note thatomitemptybehaves identically in both v1 and v2 for a Go array, slice, map, or string (assuming no user-definedMarshalJSONmethod overrides the default representation). Existing usages ofomitemptyon a Go bool, number, pointer, or interface value should migrate to specifyingomitzeroinstead (which is identically supported in both v1 and v2). See prior discussion for more information. -
In v1, a Go struct field marked as
stringcan be used to quote a Go string, bool, or number as a JSON string. It does not recursively take effect on composite Go types. In contrast, v2 restricts thestringoption to only quote a Go number as a JSON string. It does recursively take effect on Go numbers within a composite Go type. Thejsonv1.StringifyWithLegacySemanticsoption controls this behavior difference. -
In v1, a nil Go slice or Go map is marshaled as a JSON null. In contrast, v2 marshals a nil Go slice or Go map as an empty JSON array or JSON object, respectively. The
FormatNilSliceAsNullandFormatNilMapAsNulloptions control this behavior difference. To explicitly specify a Go struct field to use a particular representation for nil, either theformat:emitemptyorformat:emitnullfield option can be specified. Field-specified options take precedence over caller-specified options. See prior discussion for more information. -
In v1, a Go array may be unmarshaled from a JSON array of any length. In contrast, in v2 a Go array must be unmarshaled from a JSON array of the same length, otherwise it results in an error. The
jsonv1.UnmarshalArrayFromAnyLengthoption controls this behavior difference. -
In v1, a Go byte array (i.e.,
~[N]byte) is represented as a JSON array of JSON numbers. In contrast, in v2 a Go byte array is represented as a Base64-encoded JSON string. Thejsonv1.FormatBytesWithLegacySemanticsoption controls this behavior difference. To explicitly specify a Go struct field to use a particular representation, either theformat:arrayorformat:base64field option can be specified. Field-specified options take precedence over caller-specified options. -
In v1,
MarshalJSONmethods declared on a pointer receiver are only called if the Go value is addressable. In contrast, in v2 aMarshalJSONmethod is always callable regardless of addressability. Thejsonv1.CallMethodsWithLegacySemanticsoption controls this behavior difference. -
In v1,
MarshalJSONandUnmarshalJSONmethods are never called for Go map keys. In contrast, in v2 aMarshalJSONorUnmarshalJSONmethod is eligible for being called for Go map keys. Thejsonv1.CallMethodsWithLegacySemanticsoption controls this behavior difference. -
In v1, a Go map is marshaled in a deterministic order. In contrast, in v2 a Go map is marshaled in a non-deterministic order. The
Deterministicoption controls this behavior difference. See prior discussion for more information. -
In v1, JSON strings are encoded with HTML-specific or JavaScript-specific characters being escaped. In contrast, in v2 JSON strings use the minimal encoding and only escape if required by the JSON grammar. The
jsontext.EscapeForHTMLandjsontext.EscapeForJSoptions control this behavior difference. -
In v1, bytes of invalid UTF-8 within a string are silently replaced with the Unicode replacement character. In contrast, in v2 the presence of invalid UTF-8 results in an error. The
jsontext.AllowInvalidUTF8option controls this behavior difference. -
In v1, a JSON object with duplicate names is permitted. In contrast, in v2 a JSON object with duplicate names results in an error. The
jsontext.AllowDuplicateNamesoption controls this behavior difference. -
In v1, when unmarshaling a JSON null into a non-empty Go value it will inconsistently either zero out the value or do nothing. In contrast, in v2 unmarshaling a JSON null will consistently and always zero out the underlying Go value. The
jsonv1.MergeWithLegacySemanticsoption controls this behavior difference. -
In v1, when unmarshaling a JSON value into a non-zero Go value, it merges into the original Go value for array elements, slice elements, struct fields (but not map values), pointer values, and interface values (only if a non-nil pointer). In contrast, in v2 unmarshal merges into the Go value for struct fields, map values, pointer values, and interface values. In general, the v2 semantic merges when unmarshaling a JSON object, otherwise it replaces the value. The
jsonv1.MergeWithLegacySemanticsoption controls this behavior difference. -
In v1, a
time.Durationis represented as a JSON number containing the decimal number of nanoseconds. In contrast, in v2 atime.Durationis represented as a JSON string containing the formatted duration (e.g., "1h2m3.456s") according totime.Duration.String. Thejsonv1.FormatTimeWithLegacySemanticsoption controls this behavior difference. To explicitly specify a Go struct field to use a particular representation, either theformat:nanoorformat:unitsfield option can be specified. Field-specified options take precedence over caller-specified options. -
In v1, errors are never reported at runtime for Go struct types that have some form of structural error (e.g., a malformed tag option). In contrast, v2 reports a runtime error for Go types that are invalid as they relate to JSON serialization. For example, a Go struct with only unexported fields cannot be serialized. The
jsonv1.ReportErrorsWithLegacySemanticsoption controls this behavior difference.
While the behavior of Marshal and Unmarshal in "json/v2" is changing relative to v1 "json", note that the behavior of v1 "json" remains as is.
Struct tag options
Similar to v1, v2 also supports customized representation of Go struct fields through the use of struct tags. As before, the json tag will be used. The following tag options are supported:
-
omitzero: When marshaling, the "omitzero" option specifies that the struct field should be omitted if the field value is zero, as determined by the "IsZero() bool" method, if present, otherwise based on whether the field is the zero Go value (per
reflect.Value.IsZero). This option has no effect when unmarshaling. (example)- New in v2, but has already been backported to v1 (see #45669) in Go 1.24.
-
omitempty: When marshaling, the "omitempty" option specifies that the struct field should be omitted if the field value would have been encoded as a JSON null, empty string, empty object, or empty array. This option has no effect when unmarshaling. (example)
- Changed in v2. In v1, the "omitempty" option was narrowly defined as only omitting a field if it is a Go false, 0, a nil pointer, a nil interface value, and any empty array, slice, map, or string. In v2, it has been redefined in terms of the JSON type system, rather than the Go type system. They are practically equivalent except for Go bools, numbers, pointers, and interfaces for which the "omitzero" option can be used instead.
-
string: The "string" option specifies that
StringifyNumbersbe set when marshaling or unmarshaling a struct field value. This causes numeric types to be encoded as a JSON number within a JSON string, and to be decoded from a JSON string containing a JSON number. This extra level of encoding is often necessary since many JSON parsers cannot precisely represent 64-bit integers.- Changed in v2. In v1, the "string" option applied to certain types where use of a JSON string did not make sense (e.g., a bool) and could not be applied recursively (e.g., a slice of integers). In v2, this feature only applies to numeric types and applies recursively.
-
nocase: When unmarshaling, the "nocase" option specifies that if the JSON object name does not exactly match the JSON name for any of the struct fields, then it attempts to match the struct field using a case-insensitive match that also ignores dashes and underscores. (example)
- New in v2. Since v2 no longer performs a case-insensitive match of JSON object names, this option provides a means to opt-into the v1-like behavior. However, the case-insensitive match is altered relative to v1 in that it also ignores dashes and underscores. This makes the feature more broadly useful for JSON objects with different naming conventions to be unmarshaled. For example, "fooBar", "FOO_BAR", or "foo-bar" will all match with a field named "FooBar".
-
strictcase: When unmarshaling, the "strictcase" option specifies that the JSON object name must exactly match the JSON name for the struct field. This takes precedence even if MatchCaseInsensitiveNames is set to true. This cannot be specified together with the "nocase" option.
- New in v2 to provide an explicit author-specified way to prevent
MatchCaseInsensitiveNamesfrom taking effect on a particular field. This option provides a means to opt-into the v2-like behavior.
- New in v2 to provide an explicit author-specified way to prevent
-
inline: The "inline" option specifies that the JSON object representation of this field is to be promoted as if it were specified in the parent struct. It is the JSON equivalent of Go struct embedding. A Go embedded field is implicitly inlined unless an explicit JSON name is specified. The inlined field must be a Go struct that does not implement
MarshalerorUnmarshaler. Inlined fields of typejsontext.Valueandmap[~string]Tare called “inlined fallbacks”, as they can represent all possible JSON object members not directly handled by the parent struct. Only one inlined fallback field may be specified in a struct, while many non-fallback fields may be specified. This option must not be specified with any other tag option. (example)- New in v2. Inlining is an explicit way to embed a JSON object within another JSON object without relying on Go struct embedding. The feature is capable of inlining Go maps and
jsontext.Value(#6213).
- New in v2. Inlining is an explicit way to embed a JSON object within another JSON object without relying on Go struct embedding. The feature is capable of inlining Go maps and
-
unknown: The "unknown" option is a specialized variant of the inlined fallback to indicate that this Go struct field contains any number of “unknown” JSON object members. The field type must be a
jsontext.Valueor amap[~string]T. IfDiscardUnknownMembersis specified when marshaling, the contents of this field are ignored. IfRejectUnknownMembersis specified when unmarshaling, any unknown object members are rejected even if a field exists with the "unknown" option. This option must not be specified with any other tag option. (example)- New in v2. The "inline" feature technically provides a way to preserve unknown member (#22533). However, the "inline" feature alone does not semantically tell us whether this field is meant to store unknown members. The "unknown" option gives us this extra bit of information so that we can cooperate with options that affect unknown membership.
-
format: The "format" option specifies a format flag used to specialize the formatting of the field value. The option is a key-value pair specified as "format:value" where the value must be either a literal consisting of letters and numbers (e.g., "format:RFC3339") or a single-quoted string literal (e.g., "format:'2006-01-02'"). The interpretation of the format flag is determined by the struct field type. (example)
-
New in v2. The "format" option provides a general way to customize formatting of arbitrary types.
-
[]byteand[N]bytetypes accept "format" values of either "base64", "base64url", "base32", "base32hex", "base16", or "hex", where it represents the binary bytes as a JSON string encoded using the specified format in RFC 4648. It may also be "array" to treat the slice or array as a JSON array of numbers. The "array" format exists for backwards compatibility since the default representation of an array of bytes now uses Base-64. -
float32andfloat64types accept a "format" value of "nonfinite", where NaN and infinity are represented as JSON strings. -
Slice types accept a "format" value of "emitnull" to marshal a nil slice as a JSON null instead of an empty JSON array. (more discussion).
-
Map types accept a "format" value of "emitnull" to marshal a nil map as a JSON null instead of an empty JSON object. (more discussion).
-
The
time.Timetype accepts a "format" value which may either be a Go identifier for one of the format constants (e.g., "RFC3339") or the format string itself to use withtime.Time.Formatortime.Parse(#21990). It can also be "unix", "unixmilli", "unixmicro", or "unixnano" to be represented as a decimal number reporting the number of seconds (or milliseconds, etc.) since the Unix epoch. -
The
time.Durationtype accepts a "format" value of "sec", "milli", "micro", or "nano" to represent it as the number of seconds (or milliseconds, etc.) formatted as a JSON number. This exists for backwards compatibility since the default representation now uses a string representation (e.g., "53.241s"). If the format is "base60", it is encoded as a JSON string using the "H:MM:SS.SSSSSSSSS" representation.
-
The "omitzero" and "omitempty" options are similar. The former is defined in terms of the Go type system, while the latter in terms of the JSON type system. Consequently they behave differently in some circumstances. For example, only a nil slice or map is omitted under "omitzero", while an empty slice or map is omitted under "omitempty" regardless of nilness. The "omitzero" option is useful for types with a well-defined zero value (e.g., netip.Addr) or have an IsZero method (e.g., time.Time).
Note that all tag options labeled with "Changed in v2" will behave as it has always historically behaved when using v1 "json". However, all tag options labeled with "New in v2" will be implicitly and retroactively supported in v1 "json" because v1 will be implemented under-the-hood using "json/v2".
Type-specified customization
Go types may customize their own JSON representation by implementing certain interfaces that the "json" package knows to look for:
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
type MarshalerTo interface {
MarshalJSONTo(*jsontext.Encoder, Options) error
}
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
type UnmarshalerFrom interface {
UnmarshalJSONFrom(*jsontext.Decoder, Options) error
}
The v1 Marshaler and Unmarshaler interfaces are supported in v2 to provide greater degrees of backward compatibility.
The MarshalerTo and UnmarshalerFrom interfaces operate in a purely streaming manner and provide a means for plumbing down options. This API can provide dramatic performance improvements (see "Performance").
If a type implements both sets of marshaling or unmarshaling interfaces, then the streaming variant takes precedence.
Just like v1, encoding.TextMarshaler and encoding.TextUnmarshaler interfaces remain supported in v2, where these interfaces are treated with lower precedence than JSON-specific serialization interfaces.
Caller-specified customization
In addition to Go types being able to specify their own JSON representation, the caller of the marshal or unmarshal functionality can also specify their own JSON representation for specific Go types (#5901). Caller-specified customization takes precedence over type-specified customization.
// SkipFunc may be returned by MarshalToFunc and UnmarshalFromFunc functions.
// Any function that returns SkipFunc must not cause observable side effects
// on the provided Encoder or Decoder.
const SkipFunc = jsonError("skip function")
// Marshalers holds a list of functions that may override the marshal behavior
// of specific types. Populate WithMarshalers to use it.
// A nil *Marshalers is equivalent to an empty list.
type Marshalers struct { /* no exported fields */ }
// JoinMarshalers constructs a flattened list of marshal functions.
// If multiple functions in the list are applicable for a value of a given type,
// then those earlier in the list take precedence over those that come later.
// If a function returns SkipFunc, then the next applicable function is called,
// otherwise the default marshaling behavior is used.
//
// For example:
//
// m1 := JoinMarshalers(f1, f2)
// m2 := JoinMarshalers(f0, m1, f3) // equivalent to m3
// m3 := JoinMarshalers(f0, f1, f2, f3) // equivalent to m2
func JoinMarshalers(ms ...*Marshalers) *Marshalers
// MarshalFunc constructs a type-specific marshaler that
// specifies how to marshal values of type T.
func MarshalFunc[T any](fn func(T) ([]byte, error)) *Marshalers
// MarshalToFunc constructs a type-specific marshaler that
// specifies how to marshal values of type T.
// The function is always provided with a non-nil pointer value
// if T is an interface or pointer type.
func MarshalToFunc[T any](fn func(*jsontext.Encoder, T, Options) error) *Marshalers
// Unmarshalers holds a list of functions that may override the unmarshal behavior
// of specific types. Populate WithUnmarshalers to use it.
// A nil *Unmarshalers is equivalent to an empty list.
type Unmarshalers struct { /* no exported fields */ }
// JoinUnmarshalers constructs a flattened list of unmarshal functions.
// It operates in a similar manner as [JoinMarshalers].
func JoinUnmarshalers(us ...*Unmarshalers) *Unmarshalers
// UnmarshalFunc constructs a type-specific unmarshaler that
// specifies how to unmarshal values of type T.
func UnmarshalFunc[T any](fn func([]byte, T) error) *Unmarshalers
// UnmarshalFromFunc constructs a type-specific unmarshaler that
// specifies how to unmarshal values of type T.
// T must be an unnamed pointer or an interface type.
// The function is always provided with a non-nil pointer value.
func UnmarshalFromFunc[T any](fn func(*jsontext.Decoder, T, Options) error) *Unmarshalers
Caller-specified customization is a powerful feature. For example:
- It can be used to marshal Go errors (example).
- It can be used to preserve the raw representation of JSON numbers (example). Note that v2 does not have the v1 RawNumber type.
- It can be used to preserve the input offset of JSON values for error reporting purposes (example).
Options
Options may be specified that configure how marshal and unmarshal operates:
// Options configure Marshal, MarshalWrite, MarshalEncode,
// Unmarshal, UnmarshalRead, and UnmarshalDecode with specific features.
// Each function takes in a variadic list of options, where properties set
// in latter options override the value of previously set properties.
//
// Options represent either a singular option or a set of options.
// It can be functionally thought of as a Go map of option properties
// (even though the underlying implementation avoids Go maps for performance).
//
// The constructors (e.g., Deterministic) return a singular option value:
// opt := Deterministic(true)
// which is analogous to creating a single entry map:
// opt := Options{"Deterministic": true}
//
// JoinOptions composes multiple options values to together:
// out := JoinOptions(opts...)
// which is analogous to making a new map and copying the options over:
// out := make(Options)
// for _, m := range opts {
// for k, v := range m {
// out[k] = v
// }
// }
//
// GetOption looks up the value of options parameter:
// v, ok := GetOption(opts, Deterministic)
// which is analogous to a Go map lookup:
// v, ok := opts["Deterministic"]
//
// There is a single Options type, which is used with both marshal and unmarshal.
// Options that do not affect a particular operation are ignored.
type Options = jsonopts.Options
// DefaultOptionsV2 is the full set of all options that define v2 semantics.
// It is equivalent to all options under [Options], [encoding/json.Options],
// and [encoding/json/jsontext.Options] being set to false or the zero value,
// except for the options related to whitespace formatting.
func DefaultOptionsV2() Options
// StringifyNumbers specifies that numeric Go types should be marshaled as
// a JSON string containing the equivalent JSON number value.
// When unmarshaling, numeric Go types are parsed from a JSON string
// containing the JSON number without any surrounding whitespace.
func StringifyNumbers(v bool) Options // affects marshal and unmarshal
// Deterministic specifies that the same input value will be serialized
// as the exact same output bytes. Different processes of
// the same program will serialize equal values to the same bytes,
// but different versions of the same program are not guaranteed
// to produce the exact same sequence of bytes.
func Deterministic(v bool) Options // affects marshal only
// FormatNilMapAsNull specifies that a nil Go map should marshal as a
// JSON null instead of the default representation as an empty JSON object.
func FormatNilMapAsNull(v bool) Options // affects marshal only
// FormatNilSliceAsNull specifies that a nil Go slice should marshal as a
// JSON null instead of the default representation as an empty JSON array
// (or an empty JSON string in the case of ~[]byte).
func FormatNilSliceAsNull(v bool) Options // affects marshal only
// MatchCaseInsensitiveNames specifies that JSON object members are matched
// against Go struct fields using a case-insensitive match of the name.
func MatchCaseInsensitiveNames(v bool) Options // affects marshal and unmarshal
// DiscardUnknownMembers specifies that marshaling should ignore any
// JSON object members stored in Go struct fields dedicated to storing
// unknown JSON object members.
func DiscardUnknownMembers(v bool) Options // affects marshal only
// RejectUnknownMembers specifies that unknown members should be rejected
// when unmarshaling a JSON object, regardless of whether there is a field
// to store unknown members.
func RejectUnknownMembers(v bool) Options // affects unmarshal only
// OmitZeroStructFields specifies that a Go struct should marshal in such a way
// that all struct fields that are zero are omitted from the marshaled output
// if the value is zero as determined by the "IsZero() bool" method if present,
// otherwise based on whether the field is the zero Go value.
func OmitZeroStructFields(v bool) Options // affects marshal only
// NonFatalSemanticErrors specifies that [SemanticErrors] encountered
// while marshaling or unmarshaling should not immediately terminate
// the procedure, but that processing should continue and that all
// errors be returned as a multi-error.
func NonFatalSemanticErrors(v bool) Options // affects marshal and unmarshal
// WithMarshalers specifies a list of type-specific marshalers to use,
// which can be used to override the default marshal behavior
// for values of particular types.
func WithMarshalers(v *Marshalers) Options // affects marshal only
// WithUnmarshalers specifies a list of type-specific unmarshalers to use,
// which can be used to override the default unmarshal behavior
// for values of particular types.
func WithUnmarshalers(v *Unmarshalers) Options // affects unmarshal only
// JoinOptions coalesces the provided list of options into a single Options.
// Properties set in latter options override the value of previously set properties.
func JoinOptions(srcs ...Options) Options
// GetOption returns the value stored in opts with the provided constructor,
// reporting whether the value is present.
func GetOption[T any](opts Options, constructor func(T) Options) (T, bool)
The Options type is a type alias to an internal type that is an interface type with no exported methods. It is used simply as a marker type for options declared in the "json" and "jsontext" package. This is exactly the same Options type as the one in the "jsontext" package.
The same Options type is used for both Marshal and Unmarshal as some options affect both operations.
The MarshalJSONTo, UnmarshalJSONFrom, MarshalToFunc, and UnmarshalFromFunc methods and functions take in a singular Options value instead of a variadic list because the Options type can represent a set of options. The caller (which is the "json" package) can coalesce a list of options before calling the user-specified method or function. Being given a single Options value is more ergonomic for the user as there is only one options value to introspect with GetOption.
Errors
Errors due to the inability to correlate JSON data with Go data are reported as SemanticError.
type SemanticError struct {
// ByteOffset indicates that an error occurred after this byte offset.
ByteOffset int64
// JSONPointer indicates that an error occurred within this JSON value
// as indicated using the JSON Pointer notation (see RFC 6901).
JSONPointer jsontext.Pointer
// JSONKind is the JSON kind that could not be handled.
JSONKind Kind // may be zero if unknown
// JSONValue is the JSON number or string that could not be unmarshaled.
JSONValue jsontext.Value // may be nil if irrelevant or unknown
// GoType is the Go type that could not be handled.
GoType reflect.Type // may be nil if unknown
// Err is the underlying error.
Err error // may be nil
}
func (e *SemanticError) Error() string
func (e *SemanticError) Unwrap() error
// ErrUnknownName indicates that a JSON object member could not be
// unmarshaled because the name is not known to the target Go struct.
// This error is directly wrapped within a [SemanticError] when produced.
var ErrUnknownName = errors.New("unknown object member name")
ErrUnknownName is a sentinel error that is returned while being wrapped within a SemanticError.
Package "encoding/json"
The API and behavior for v1 "json" remains unchanged except for the addition of new options to configure v2 to operate with legacy v1 behavior.
Options
Options may be specified that configures v2 "json" to operate with legacy v1 behavior:
type Options = jsonopts.Options
// DefaultOptionsV1 is the full set of all options that define v1 semantics.
// It is equivalent to the following boolean options being set to true:
//
// - [CallMethodsWithLegacySemantics]
// - [EscapeInvalidUTF8]
// - [FormatBytesWithLegacySemantics]
// - [FormatTimeWithLegacySemantics]
// - [MatchCaseSensitiveDelimiter]
// - [MergeWithLegacySemantics]
// - [OmitEmptyWithLegacyDefinition]
// - [ReportErrorsWithLegacySemantics]
// - [StringifyWithLegacySemantics]
// - [UnmarshalArrayFromAnyLength]
// - [jsonv2.Deterministic]
// - [jsonv2.FormatNilMapAsNull]
// - [jsonv2.FormatNilSliceAsNull]
// - [jsonv2.MatchCaseInsensitiveNames]
// - [jsontext.AllowDuplicateNames]
// - [jsontext.AllowInvalidUTF8]
// - [jsontext.EscapeForHTML]
// - [jsontext.EscapeForJS]
// - [jsontext.PreserveRawString]
//
// The [Marshal] and [Unmarshal] functions in this package are
// semantically identical to calling the v2 equivalents with this option:
//
// jsonv2.Marshal(v, jsonv1.DefaultOptionsV1())
// jsonv2.Unmarshal(b, v, jsonv1.DefaultOptionsV1())
func DefaultOptionsV1() jsonopts.Options
// CallMethodsWithLegacySemantics specifies that calling of type-provided
// marshal and unmarshal methods follow legacy semantics:
//
// - When marshaling, a marshal method declared on a pointer receiver
// is only called if the Go value is addressable.
// Values obtained from an interface or map element are not addressable.
// Values obtained from a pointer or slice element are addressable.
// Values obtained from an array element or struct field inherit
// the addressability of the parent. In contrast, the v2 semantic
// is to always call marshal methods regardless of addressability.
//
// - When marshaling or unmarshaling, the [Marshaler] or [Unmarshaler]
// methods are ignored for map keys. However, [encoding.TextMarshaler]
// or [encoding.TextUnmarshaler] are still callable.
// In contrast, the v2 semantic is to serialize map keys
// like any other value (with regard to calling methods),
// which may include calling [Marshaler] or [Unmarshaler] methods,
// where it is the implementation's responsibility to represent the
// Go value as a JSON string (as required for JSON object names).
//
// - When marshaling, if a map key value implements a marshal method
// and is a nil pointer, then it is serialized as an empty JSON string.
// In contrast, the v2 semantic is to report an error.
//
// - When marshaling, if an interface type implements a marshal method
// and the interface value is a nil pointer to a concrete type,
// then the marshal method is always called.
// In contrast, the v2 semantic is to never directly call methods
// on interface values and to instead defer evaluation based upon
// the underlying concrete value. Similar to non-interface values,
// marshal methods are not called on nil pointers and
// are instead serialized as a JSON null.
//
// This affects either marshaling or unmarshaling.
func CallMethodsWithLegacySemantics(bool) jsonopts.Options // affects marshal and unmarshal
// EscapeInvalidUTF8 specifies that when encoding a [jsontext.String]
// with bytes of invalid UTF-8, such bytes are escaped as
// a hexadecimal Unicode codepoint (i.e., \ufffd).
// In contrast, the v2 default is to use the minimal representation,
// which is to encode invalid UTF-8 as the Unicode replacement rune itself
// (without any form of escaping).
func EscapeInvalidUTF8(bool) jsonopts.Options // affects encoding only
// FormatBytesWithLegacySemantics specifies that handling of
// []~byte and [N]~byte types follow legacy semantics:
//
// - A Go [N]~byte is always treated as as a normal Go array
// in contrast to the v2 default of treating [N]byte as
// using some form of binary data encoding (RFC 4648).
//
// - A Go []~byte is to be treated as using some form of
// binary data encoding (RFC 4648) in contrast to the v2 default
// of only treating []byte as such. In particular, v2 does not
// treat slices of named byte types as representing binary data.
//
// - When marshaling, if a named byte implements a marshal method,
// then the slice is serialized as a JSON array of elements,
// each of which call the marshal method.
//
// - When unmarshaling, if the input is a JSON array,
// then unmarshal into the []~byte as if it were a normal Go slice.
// In contrast, the v2 default is to report an error unmarshaling
// a JSON array when expecting some form of binary data encoding.
//
// - When unmarshaling, '\r' and '\n' characters are ignored
// within the encoded "base32" and "base64" data.
// In contrast, the v2 default is to report an error in order to be
// strictly compliant with RFC 4648, section 3.3,
// which specifies that non-alphabet characters must be rejected.
func FormatBytesWithLegacySemantics(bool) jsonopts.Options // affects marshal and unmarshal
// FormatTimeWithLegacySemantics specifies that [time] types are formatted
// with legacy semantics:
//
// - When marshaling or unmarshaling, a [time.Duration] is formatted as
// a JSON number representing the number of nanoseconds.
// In contrast, the default v2 behavior uses a JSON string
// with the duration formatted with [time.Duration.String].
// If a duration field has a `format` tag option,
// then the specified formatting takes precedence.
//
// - When unmarshaling, a [time.Time] follows loose adherence to RFC 3339.
// In particular, it permits historically incorrect representations,
// allowing for deviations in hour format, sub-second separator,
// and timezone representation. In contrast, the default v2 behavior
// is to strictly comply with the grammar specified in RFC 3339.
func FormatTimeWithLegacySemantics(bool) jsonopts.Options // affects marshal and unmarshal
// MatchCaseSensitiveDelimiter specifies that underscores and dashes are
// not to be ignored when performing case-insensitive name matching which
// occurs under [jsonv2.MatchCaseInsensitiveNames] or the `nocase` tag option.
// Thus, case-insensitive name matching is identical to [strings.EqualFold].
// Use of this option diminishes the ability of case-insensitive matching
// to be able to match common case variants (e.g, "foo_bar" with "fooBar").
func MatchCaseSensitiveDelimiter(bool) jsonopts.Options // affects marshal and unmarshal
// MergeWithLegacySemantics specifies that unmarshaling into a non-zero
// Go value follows legacy semantics:
//
// - When unmarshaling a JSON null, this preserves the original Go value
// if the kind is a bool, int, uint, float, string, array, or struct.
// Otherwise, it zeros the Go value.
// In contrast, the default v2 behavior is to consistently and always
// zero the Go value when unmarshaling a JSON null into it.
//
// - When unmarshaling a JSON value other than null, this merges into
// the original Go value for array elements, slice elements,
// struct fields (but not map values),
// pointer values, and interface values (only if a non-nil pointer).
// In contrast, the default v2 behavior is to merge into the Go value
// for struct fields, map values, pointer values, and interface values.
// In general, the v2 semantic merges when unmarshaling a JSON object,
// otherwise it replaces the original value.
func MergeWithLegacySemantics(bool) jsonopts.Options // affects unmarshal only
// OmitEmptyWithLegacyDefinition specifies that the `omitempty` tag option
// follows a definition of empty where a field is omitted if the Go value is
// false, 0, a nil pointer, a nil interface value,
// or any empty array, slice, map, or string.
// This overrides the v2 semantic where a field is empty if the value
// marshals as a JSON null or an empty JSON string, object, or array.
//
// The v1 and v2 definitions of `omitempty` are practically the same for
// Go strings, slices, arrays, and maps. Usages of `omitempty` on
// Go bools, ints, uints floats, pointers, and interfaces should migrate to use
// the `omitzero` tag option, which omits a field if it is the zero Go value.
func OmitEmptyWithLegacyDefinition(bool) jsonopts.Options // affects marshal only
// ReportErrorsWithLegacySemantics specifies that Marshal and Unmarshal
// should report errors with legacy semantics:
//
// - When marshaling or unmarshaling, the returned error values are
// usually of types such as [SyntaxError], [MarshalerError],
// [UnsupportedTypeError], [UnsupportedValueError],
// [InvalidUnmarshalError], or [UnmarshalTypeError].
// In contrast, the v2 semantic is to always return errors as either
// [jsonv2.SemanticError] or [jsontext.SyntacticError].
//
// - When marshaling, if a user-defined marshal method reports an error,
// it is always wrapped in a [MarshalerError], even if the error itself
// is already a [MarshalerError], which may lead to multiple redundant
// layers of wrapping. In contrast, the v2 semantic is to
// always wrap an error within [jsonv2.SemanticError]
// unless it is already a semantic error.
//
// - When unmarshaling, if a user-defined unmarshal method reports an error,
// it is never wrapped and reported verbatim. In contrast, the v2 semantic
// is to always wrap an error within [jsonv2.SemanticError]
// unless it is already a semantic error.
//
// - When marshaling or unmarshaling, if a Go struct contains type errors
// (e.g., conflicting names or malformed field tags), then such errors
// are ignored and the Go struct uses a best-effort representation.
// In contrast, the v2 semantic is to report a runtime error.
//
// - When unmarshaling, the syntactic structure of the JSON input
// is fully validated before performing the semantic unmarshaling
// of the JSON data into the Go value. Practically speaking,
// this means that JSON input with syntactic errors do not result
// in any mutations of the target Go value. In contrast, the v2 semantic
// is to perform a streaming decode and gradually unmarshal the JSON input
// into the target Go value, which means that the Go value may be
// partially mutated when a syntactic error is encountered.
//
// - When unmarshaling, a semantic error does not immediately terminate the
// unmarshal procedure, but rather evaluation continues.
// When unmarshal returns, only the first semantic error is reported.
// In contrast, the v2 semantic is to terminate unmarshal the moment
// an error is encountered.
func ReportErrorsWithLegacySemantics(bool) jsonopts.Options // affects marshal and unmarshal
// StringifyWithLegacySemantics specifies that the `string` tag option
// may stringify bools and string values. It only takes effect on fields
// where the top-level type is a bool, string, numeric kind, or a pointer to
// such a kind. Specifically, `string` will not stringify bool, string,
// or numeric kinds within a composite data type
// (e.g., array, slice, struct, map, or interface).
//
// When marshaling, such Go values are serialized as their usual
// JSON representation, but quoted within a JSON string.
// When unmarshaling, such Go values must be deserialized from
// a JSON string containing their usual JSON representation.
// A JSON null quoted in a JSON string is a valid substitute for JSON null
// while unmarshaling into a Go value that `string` takes effect on.
func StringifyWithLegacySemantics(bool) jsonopts.Options // affects marshal only
// UnmarshalArrayFromAnyLength specifies that Go arrays can be unmarshaled
// from input JSON arrays of any length. If the JSON array is too short,
// then the remaining Go array elements are zeroed. If the JSON array
// is too long, then the excess JSON array elements are skipped over.
func UnmarshalArrayFromAnyLength(bool) jsonopts.Options // affects unmarshal only
Many of the options configure fairly obscure behavior. Unfortunately, many of the behaviors cannot be changed in order to maintain backwards compatibility. This is a major justification for a v2 "json" package.
Let jsonv1 be v1 "encoding/json" and jsonv2 be "encoding/json/v2", then the v1 and v2 options can be composed together to obtain behavior that is identical to v1, identical to v2, or anywhere in between. For example:
jsonv1.Marshal(v)- uses default v1 semantics
jsonv2.Marshal(in, jsonv1.DefaultOptionsV1())- semantically equivalent to
jsonv1.Marshal jsonv2.Marshal(in, jsonv1.DefaultOptionsV1(), jsontext.AllowDuplicateNames(false))- uses mostly v1 semantics, but opts into one v2-specific behavior
jsonv2.Marshal(in, jsonv1.StringifyWithLegacySemantics(true), jsonv1.ReportErrorsWithLegacySemantics(true))- uses mostly v2 semantics, but opts into two v1-specific behaviors
jsonv2.Marshal(v, ..., jsonv2.DefaultOptionsV2())- semantically equivalent to
jsonv2.Marshalsincejsonv2.DefaultOptionsV2overrides any options specified earlier in the... jsonv2.Marshal(v)- uses default v2 semantics
Types aliases
The following types are moved to v2 "json":
type Marshaler = jsonv2.Marshaler
type Unmarshaler = jsonv2.Unmarshaler
type RawMessage = jsontext.Value
Number methods
The Number type no longer has special-case support in the "json" implementation itself.
func (Number) MarshalJSONTo(*jsontext.Encoder, jsonopts.Options) error
func (*Number) UnmarshalJSONFrom(*jsontext.Decoder, jsonopts.Options) error
So methods are added to have it implement the v2 MarshalerTo and UnmarshalerFrom methods to preserve equivalent behavior.
Errors
The UnmarshalTypeError type is extended to wrap an underlying error:
type UnmarshalTypeError struct {
...
Err error
}
func (*UnmarshalTypeError) Unwrap() error
Errors returned by v2 "json" are much richer, so the wrapped error provides a way for v1 "json" to preserve some of that context, while still using the UnmarshalTypeError type, which many programs may still be expecting.
The UnmarshalTypeError.Field now reports a dot-delimited path to the error value where each path segment is either a JSON array and map index operation. This is a divergence from prior behavior which was always inconsistent about whether the position was reported according to the Go namespace or the JSON namespace (see #43126).
Comment From: dsnet
Changes from discussion
If you have already read the discussion in #63397, then much of the API presented above may be familiar. This section records the differences made relative to the discussion.
Package "encoding/json/jsontext"
The following Value methods were altered to accept options.
- func (v Value) IsValid() bool
+ func (v Value) IsValid(opts ...Options) bool
- func (v *Value) Compact() error
+ func (v *Value) Compact(opts ...Options) error
- func (v *Value) Indent(prefix, indent string) error
+ func (v *Value) Indent(opts ...Options) error
- func (v *Value) Canonicalize() error
+ func (v *Value) Canonicalize(opts ...Options) error
+ func (v *Value) Format(opts ...Options) error
Accepting options allows the default behavior of these methods to be overridden, providing greater flexibility in usage.
The removal of the prefix and indent argument from Indent improves the ergonomics of the method as most users just want indented output without thinking about the particular indent string used. These can still be specified using the WithIndentPrefix and WithIndent options.
One major criticism of Canonicalize (per RFC 8785) is that it mangles the precision of wide integers. By accepting options, users can additionally specify CanonicalizeRawInts(false) to prevent this behavior, while still having canonicalization for all other JSON artifacts.
The Format method was newly added as the primary implementation backing Compact, Indent, and Canonicalize.
The following options were added to provide greater flexibility to formatting:
+ func CanonicalizeRawFloats(v bool) Options
+ func CanonicalizeRawInts(v bool) Options
+ func PreserveRawStrings(v bool) Options
+ func ReorderRawObjects(v bool) Options
+ func SpaceAfterComma(v bool) Options
+ func SpaceAfterColon(v bool) Options
- func Expand(v bool) Options
+ func Multiline(v bool) Options
The Expand option was renamed as Multiline to be more clear and to distinguish it from SpaceAfterComma and SpaceAfterColon (which both technically "expand" the output).
The following formatting API has been added:
+ func AppendFormat(dst, src []byte, opts ...Options) ([]byte, error)
+ func AppendQuote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)
+ func AppendUnquote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)
The length returned by StackIndex is now a int64 instead of int since the length of a JSON array or object could theoretically exceed int when handling JSON in a purely streaming manner. The stack depth, however, remains fundamentally limited by the amount of system memory, so an int is still an appropriate type.
-func (e *Encoder) StackIndex(i int) (Kind, int)
+func (e *Encoder) StackIndex(i int) (Kind, int64)
-func (d *Decoder) StackIndex(i int) (Kind, int)
+func (d *Decoder) StackIndex(i int) (Kind, int64)
The pointer returned by StackPointer is now the named Pointer type.
- func (e *Encoder) StackPointer() string
+ func (e *Encoder) StackPointer() Pointer
- func (d *Decoder) StackPointer() string
+ func (d *Decoder) StackPointer() Pointer
An explicit Pointer type was added to represent a JSON Pointer (RFC 6901) as a means to identify exactly where an error occurred. Convenience methods are defined for interacting with a pointer.
+ type Pointer string
+ func (p Pointer) IsValid() bool
+ func (p Pointer) AppendToken(tok string) Pointer
+ func (p Pointer) Parent() Pointer
+ func (p Pointer) Contains(pc Pointer) bool
+ func (p Pointer) LastToken() string
+ func (p Pointer) Tokens() iter.Seq[string]
Handling of errors was improved:
type SyntacticError struct {
...
- JSONPointer string
+ JSONPointer Pointer
}
+ var ErrDuplicateName = errors.New("duplicate object member name")
+ var ErrNonStringName = errors.New("object member name must be a string")
The ErrDuplicateName and ErrNonStringName errors were added to support common error conditions users may want to distinguish upon through the use of errors.Is.
Package "encoding/json/v2"
Interface types and methods were renamed to avoid the V1 and V2 suffixes, which were aesthetically unpleasant. Instead, the V2 declarations now generally use the To and From suffixes to indicate that they support streaming. This follows after the convention established by io.WriterTo and io.ReaderFrom.
- type MarshalerV1 interface { MarshalJSON() ([]byte, error) }
+ type Marshaler interface { MarshalJSON() ([]byte, error)}
- type MarshalerV2 interface { MarshalJSONV2(*jsontext.Encoder, Options) error }
+ type MarshalerTo interface { MarshalJSONTo(*jsontext.Encoder, Options) error}
- type UnmarshalerV1 interface { UnmarshalJSON([]byte) error }
+ type Unmarshaler interface { UnmarshalJSON([]byte) error}
- type UnmarshalerV2 interface { UnmarshalJSONV2(*jsontext.Decoder, Options) error }
+ type UnmarshalerFrom interface { UnmarshalJSONFrom(*jsontext.Decoder, Options) error}
- func MarshalFuncV1[T any](fn func(T) ([]byte, error)) *Marshalers
+ func MarshalFunc[T any](fn func(T) ([]byte, error)) *Marshalers
- func MarshalFuncV2[T any](fn func(*jsontext.Encoder, T, Options) error) *Marshalers
+ func MarshalToFunc[T any](fn func(*jsontext.Encoder, T, Options) error) *Marshalers
- func UnmarshalFuncV1[T any](fn func([]byte, T) error) *Unmarshalers
+ func UnmarshalFunc[T any](fn func([]byte, T) error) *Unmarshalers
- func UnmarshalFuncV2[T any](fn func(*jsontext.Decoder, T, Options) error) *Unmarshalers
+ func UnmarshalFromFunc[T any](fn func(*jsontext.Decoder, T, Options) error) *Unmarshalers
The constructor for Marshalers and Unmarshalers were renamed using the Join prefix to be more consistent with the existing JoinOptions constructor. It also more clearly matches exactly what the constructor does.
- func NewMarshalers(ms ...*Marshalers) *Marshalers
+ func JoinMarshalers(ms ...*Marshalers) *Marshalers
- func NewUnmarshalers(us ...*Unmarshalers) *Unmarshalers
+ func JoinUnmarshalers(us ...*Unmarshalers) *Unmarshalers
The following options were added:
+ func OmitZeroStructFields(v bool) Options
+ func NonFatalSemanticErrors(v bool) Options
The OmitZeroStructFields is a caller-specified option that mirrors the addition of the omitzero struct tag option.
Implementing v1 in terms of v2 required the latter to support non-fatal errors. The NonFatalSemanticErrors option exposes that functionality in a more consistent (i.e., handling both marshal and unmarshal) and in a more modern way (i.e., returning a multi error).
type SemanticError struct {
...
- JSONPointer string
+ JSONPointer jsontext.Pointer
+ JSONValue jsontext.Value
}
+ var ErrUnknownName = errors.New("unknown object member name")
The ErrUnknownName error was added to support common use-cases wanting to distinguish this particular condition (see #29035).
The following behavior changes were made to marshal and unmarshal:
-
There is newly added support for the
strictcaseoption to provide a better migration path between users of both v1 and v2. -
Specifying the
stringtag option now rejects unmarshaling from a JSON number and only permits unmarshaling from a JSON string. This exactly matches the behavior of v1. -
When unmarshaling, a floating-point overflow results in an error. This exactly matches the behavior of v1.
-
Serialization now supports embedded fields of unexported struct types with exported fields. This exactly matches the behavior of v1.
Package "encoding/json"
Some options for legacy v1 support were renamed or had similar options folded together.
- func RejectFloatOverflow(v bool) Options
- func IgnoreStructErrors(v bool) Options
- func ReportLegacyErrorValues(v bool) Options
+ func ReportErrorsWithLegacySemantics(bool)
- func SkipUnaddressableMethods(v bool) Options
+ func CallMethodsWithLegacySemantics(bool)
- func FormatByteArrayAsArray(v bool) Options
+ func FormatBytesWithLegacySemantics(bool)
- func FormatTimeDurationAsNanosecond(v bool) Options
+ func FormatTimeWithLegacySemantics(bool)
+ func EscapeInvalidUTF8(bool)
In general, many options were renamed with a WithLegacySemantics suffix because they convered a multitude of behavior differences that could not be adequently described with a concise name.
The RejectFloatOverflow option was removed because v2 now rejects floating-point overflows just like v1.
The EscapeInvalidUTF8 option was added in order to support a behavior difference that was discovered while implementing v1 support in terms of v2. We may avoid adding this as it controls fairly esoteric and undocumented behavior.
The Number type implements MarshalerTo and UnmarshalerFrom for better compatibility with v2.
+ func (Number) MarshalJSONTo(*jsontext.Encoder, jsonopts.Options) error
+ func (*Number) UnmarshalJSONFrom(*jsontext.Decoder, jsonopts.Options) error
The UnmarshalTypeError type now supports error wrapping.
type UnmarshalTypeError struct {
...
+ Err error
}
+ func (*UnmarshalTypeError) Unwrap() error
Changes not made from discussion
There were many ideas discussed in #63397 that did not result in changes to the current proposal. Some ideas are still worth pursuing, while others were declined for various reasons. In general, ideas that could later be built on top of the initial release of v2 were deferred so that we could focus on the current API. We prioritized ideas that could not be explored after the initial API was finalized.
The following is a non-exhaustive list of such considerations:
-
Option structs instead of variadic options: An older prototype of the v2 implementation used option structs, but was refactored to use variadic options once work began implementing v1 in terms of v2. In general, options operate upon several dimensions: v1 versus v2, marshal versus unmarshal, and encode versus decode. Some options are valid in multiple dimensions (e.g., marshal and unmarshal). Some call sites accept options from multiple dimensions (e.g., marshal and encode). A singular options type is more ergonomic, but loses type safety. We deem the wins of the former stronger than the losses of the latter.
-
User-defined option values:
json.Optionsshould support user-provided values. One possible future proposal could be aWithOption[T any](v T)constructor to convert a user-provided value into an option. See #71664 for a separate proposal. -
User-defined format values:
json.Optionsshould support specifying format values (e.g., that alltime.Timetypes use the "unix" format). One possible future proposal could be aWithFormat[T any](s string)constructor to declare arbitrary formats for custom use. See #71664 for a separate proposal. -
context.Contextplumbing:json.MarshalerToandjson.UnmarshalerFromcould accept acontext.Context. A context serves two purposes: 1) cancelation of an operation, 2) plumbing of user-defined options. Cancelation does not make sense in "json" since theio.Readerandio.Writerinterfaces provide no direct way to cancel a read or write operation. Plumbing of options should be done by extending the existingjson.Optionstype to support user-defined options (see above ideas). Thus, there is little utility to plumbing acontext.Context. -
Treat
[]byteas just strings:~[]byteand~[N]bytetypes should support aformat:stringoption that treats such types as if they were Go strings. This can be a future proposal. -
Use ISO 8601 for
time.Duration: While JavaScript in TC39 recently defined a grammar for durations based on a particular profile of ISO 8601, the specification does not define the meaning of "years", "months", "weeks", etc., so we cannot convert ISO 8601 into a specifictime.Durationvalue. Any value chosen for each unit will inevitably lead to interoperability issues when other systems use different definitions of such units. See #71631 for further discussion about the right default fortime.Duration. -
First-class support for ternary values: Some usages of JSON expect the Go value to distinguish between whether an object member was present, is null, or an explicit value. It is out of scope of v2 to directly support this use case, but the
omitzerotag option does make this easier to implement externally. -
First-class support for ordered maps: While JSON specifies that objects are unordered, many usages of JSON rely on the ordering and expect Go to provide first-class support for handling ordered objects. However, a native Go type that preserves ordering does not exist, so support for this is deferred for now.
-
First-class support for union types: It is common for the type of a particular JSON value to be dynamically changed based on context. This is difficult to support in Go as the equivalent of a dynamic value is a Go interface. When unmarshaling, there is no way in Go reflection to enumerate the set of possible Go types that can be stored in a Go interface in order to choose the right type to automatically unmarshal a dynamic JSON value. Support for such use cases is deferred until better Go language support exists.
-
Split marshal/unmarshal into separate packages: We already split JSON functionality apart based on whether it dealt with JSON at a syntactic (i.e., "jsontext") or semantic (i.e., "json/v2") level. This particular split is justified by the fact that syntactic processing should not depend on Go reflection (which is a relatively heavy dependency). The benefits of splitting marshal and unmarshal apart is less clear. This seems like the job of the Go compiler/linker to perform better dead-code elimination (DCE) of unused functionality.
-
jsontext.Decoder.PeekKindshould return an error:PeekKindis often called in a loop to decode all elements of a JSON array or object. There is both an ergonomic and performance reason to avoid reporting an error. While returning an error may signal an error earlier, properly validating the JSON input fundamentally requires calling aReadTokenorReadValuemethod untilio.EOF. Thus, ifReadis always eventually called, then an error during an intermediatePeekKindcall is guaranteed to eventually be surfaced. -
jsontext.Tokenaccessors should return errors: TheInt,Uint, andFloataccessors are intended to be symmetric accessors to theInt,Uint, andFloatconstructors. So long as the kind is a JSON number, there is a reasonable way to coerce the JSON number to the closest representation for anint64,uint64, orfloat64. Users that desire stricter conversion can callstrconv.ParseInt,strconv.ParseUint, orstrconv.ParseFloatwith theStringaccessor (e.g.,strconv.ParseInt(tok.String(), 10, 16)). -
Remove
jsontext.Value.Canonicalize: The primary objection to supporting RFC 8785 for canonicalizing a JSON value is that it mangles the precision of 64-bit integers. This is due to JSON's heritage in JavaScript, which uses floating-point numbers. Rather than removingCanonicalize, we modified it to accept options, so that users could explicitly avoid the integer mangling behavior by specifyingjsontext.CanonicalizeRawInts(false). -
Enforce a max depth or max bytes: The initial v2 release will not implement this, but proposal #56733 has already been accepted. An implementation for this may happen soon after v2 lands in the standard library.
-
Immutable
jsontext.Tokenvariables: TheNull,False,True,ObjectStart,ObjectEnd,ArrayStart,ArrayEndglobal variables injsontextcould use constructor functions to be immutable. However, much of the Go standard library already exposes mutable globals and this does not seem to be a problem. -
Declare
jsontext.Kindconstants: Using the HTTP method names as prior precedence shows that a vast majority of Go code use a string literal (e.g., "GET") over referencing the constant (e.g.,http.MethodGet). It is unclear whetherKindconstants will actually provide value or serve to cause greater inconsistency. The addition of constants can be separately proposed in the future. -
Support JSON5 or JWCC: This is out of scope for v2 and can be a future proposal if those related JSON formats become sufficiently popular.
-
Make
EncoderandDecoderan interface: Thejson.MarshalerToandjson.UnmarshalerFrominterfaces reference a concretejsontext.Encoderandjsontext.Decoderimplementation, which prevents use of a customer encoder or decoder. We considered making these an interface, but the performance cost of constantly calling a virtual method was expensive when a vast majority of usages are for the standard implementation.
Changes since proposal
Since the filing of this proposal, some changes were made in response to feedback:
- #153 The
nocaseandstrictcasetag options were renamed tocase:ignoreandcase:strict. - #159 The
ArrayStart,ArrayEnd,ObjectStart, andObjectEndvariables in the "jsontext" package were renamed asBeginArray,EndArray,BeginObject, andEndObjectto match the formal names of these tokens in RFC 8259, section 2. - #163 The
Optionsargument was dropped from theMarshalerToandUnmarshalerFrominterfaces and theMarshalToFuncandUnmarshalFromFuncfunctions in the "json/v2" package. Instead, anOptionsmethod is added tojsontext.Encoderandjsontext.Decoder. - #166 Support for the
base60format was dropped fortime.Durationdue to lack of popular demand. - CL 683175 Always reject an unquoted
-as the JSON field name since empirical evidence shows it to be a common footgun where users expect it to always ignore a field, when it sometimes does not. - CL 682403 Add support for ISO 8601 durations using the exact same grammar as the
Temporal.Durationtype being added to JavaScript. - CL 682455 Report an error on
time.Durationwithout an explicit format. The default JSON representation for a duration is hotly contested, so requiring an explicit format for now keeps the future open for a final decision. - CL 683897 The
jsontext.Encoder.UnusedBuffermethod is renamed asAvailableBufferto better match the pre-existingbufio.Writer.AvailableBufferandbytes.Buffer.AvailableBuffermethods. - CL 687116 The legacy
EscapeInvalidUTF8option has been removed. - CL 685395 The legacy
FormatBytesWithLegacySemanticsoption has been decomposed asFormatBytesWithLegacySemantics,FormatByteArrayAsArray, andParseBytesWithLooseRFC4648. The legacyFormatTimeWithLegacySemanticsoption has been decomposed asFormatDurationAsNanoandParseTimeWithLooseRFC3339. The legacyOmitEmptyWithLegacyDefinitionoption has been renamed asOmitEmptyWithLegacySemantics.
Comment From: dsnet
Proposed implementation
This proposal has been implemented by the github.com/go-json-experiment/json module.
If this proposal is accepted, the implementation in github.com/go-json-experiment/json will be moved into the standard library.
We may also provide a golang.org/x/json module that contains an identical copy of the implementation so that users on older Go releases can make use of v2. This module will use type-aliases to the Go standard library if the user is compiling with a sufficiently new version of the Go toolchain.
Performance
For more information, see the github.com/go-json-experiment/jsonbench module.
The following benchmarks compares performance across several different JSON implementations:
JSONv1isencoding/jsonatv1.23.5JSONv1in2isgithub.com/go-json-experiment/json/v1atv0.0.0-20250127181117-bbe7ee0d7d2cJSONv2isgithub.com/go-json-experiment/jsonatv0.0.0-20250127181117-bbe7ee0d7d2c
The JSONv1in2 implementation replicates the JSONv1 API and behavior purely in terms of the JSONv2 implementation by setting the appropriate set of options to reproduce legacy v1 behavior.
Benchmarks were run across various datasets:
CanadaGeometryis a GeoJSON (RFC 7946) representation of Canada. It contains many JSON arrays of arrays of two-element arrays of numbers.CITMCatalogcontains many JSON objects using numeric names.SyntheaFHIRis sample JSON data from the healthcare industry. It contains many nested JSON objects with mostly string values, where the set of unique string values is relatively small.TwitterStatusis the JSON response from the Twitter API. It contains a mix of all different JSON kinds, where string values are a mix of both single-byte ASCII and multi-byte Unicode.GolangSourceis a simple tree representing the Go source code. It contains many nested JSON objects, each with the same schema.StringUnicodecontains many strings with multi-byte Unicode runes.
JSONv2 has several semantic changes relative to JSONv1 that impact performance:
-
When marshaling,
JSONv2no longer sorts the keys of a Go map. This will improve performance. -
When marshaling or unmarshaling,
JSONv2always checks to make sure JSON object names are unique. This will hurt performance, but is more correct. -
When unmarshaling,
JSONv2always performs a case-sensitive match for JSON object names. This will improve performance and is generally more correct. -
When marshaling or unmarshaling,
JSONv2always shallow copies the underlying value for a Go interface and shallow copies the key and value for entries in a Go map. This is done to keep the value as addressable so thatJSONv2can call methods and functions that operate on a pointer receiver. This will hurt performance, but is more correct. -
When marshaling or unmarshaling,
JSONv2supports calling type-defined methods or caller-defined functions with the currentjsontext.Encoderorjsontext.Decoder. TheEncoderorDecodermust contain a state machine to validate calls according to the JSON grammar. Maintaining this state will hurt performance. TheJSONv1API provides no means for obtaining theEncoderorDecoderso it never needed to explicitly maintain a state machine. Conformance to the JSON grammar is implicitly accomplished by matching against the structure of the call stack.
All of the charts are unit-less since the values are normalized relative to JSONv1, which is why JSONv1 always has a value of 1. A lower value is better (i.e., runs faster).
When marshaling, JSONv1in2 and JSONv2 is roughly at parity in performance with JSONv1. It is faster for some datasets, yet slower in others.
Compared to high-performance third-party alternatives, the proposed "encoding/json/v2" implementation performs within the same order of magnitude, indicating near-optimal efficiency.
When unmarshaling, JSONv2 is 2.7x to 10.2x faster than JSONv1. Most of the performance gained is due to a faster syntactic parser. JSONv1 takes a lexical scanning approach, which performs a virtual function call for every byte of input. In contrast, JSONv2 makes heavy use of iterative and linear parsing logic (with extra complexity to resume parsing when encountering segmented buffers).
Compared to high-performance third-party alternatives, the proposed "encoding/json/v2" implementation performs within the same order of magnitude, indicating near-optimal efficiency.
While maintaining a JSON state machine hurts the v2 implementation in terms of performance, it provides the ability to marshal or unmarshal in a purely streaming manner. This feature is necessary to convert certain pathological O(N²) runtime scenarios into O(N). For example, switching from UnmarshalJSON to UnmarshalJSONFrom for spec.Swagger resulted in an ~40x performance improvement. These performance gains are not unique to streaming unmarshal, but also apply to streaming marshal. The benchmark charts above do not exercise recursive MarshalJSON or UnmarshalJSON calls, and thus do not demonstrate the significant gains of a pure streaming API.
Comment From: mitar
Thanks! This really looks great.
Does MarshalJSONTo allow custom implementation to skip marshaling the value? What happens if it does not call any method of Encoder while encoding the value of an object? Does this produce invalid JSON or does this skip the value then?
It seems to me there is no way to provide custom (i.e., non-standard) options?
Comment From: dsnet
Does
MarshalJSONToallow custom implementation to skip marshaling the value?
The current behavior is that MarshalJSONTo and UnmarshalJSONFrom methods are not allowed to return SkipFunc, which will result in an error. We could support this, but there are benefits and detriments. The detriment of allowing methods to return SkipFunc is that directly calling a MarshalJSONTo does not always do what you expect, and the caller is now responsible for checking the error value to perform some fallback. Also, the equivalent behavior of SkipFunc could be accomplished in the implementation of MarshalJSONTo itself:
func (v T) MarshalJSONTo(enc *jsontext.Encoder, opts json.Options) error {
type TNoMethods T
return json.MarshalEncode(enc, TNoMethods(v), opts)
}
It seems to me there is no way to provide custom (i.e., non-standard) options?
We're going to withhold this for the initial release of v2, but propose something as a follow-up. I still believe it's an important feature, but we're making a conscious decision to limit the scope of v2, which is already large.
If you're interested, there's a prototype API for user-defined options in https://github.com/go-json-experiment/json/pull/138. One of my comments also scopes out a possible API for specifying format flags for particular types.
Comment From: a-pav
Thank you for this great work.
Will json/v2 also include string format for unmarshaling into []byte and [N]byte types with no translation as it was discussed here?
Comment From: mitar
@dsnet Thanks for the response. Seems reasonable.
and the caller is now responsible for checking the error value to perform some fallback
Yes, and this is why I worry that in the future we will never be able to add this in backwards compatible way, unless this is added from the beginning. The rest can be extended easier.
My design goal is really that MarshalJSONTo should be able to reimplement everything struct tags can achieve. Currently you cannot replicate omitempty for example.
(Oh, are all struct tags for a given field even available through json.Options? I guess this can be added in the future? But being able to have custom MarshalJSONTo on your struct and being able to know if the user of your struct used omitempty for a field with your struct as a type is really a useful feature.)
the equivalent behavior of
SkipFunccould be accomplished in the implementation ofMarshalJSONToitself:
I must say I do not get how your example can simulate behavior of, for example, omitempty. It just does the default implementation of JSON marshal for the value, but it does not allow one to signal that the value should be omitted or not. Maybe I am missing something?
Comment From: duckbrain
At present, there are no constants declared for individual kinds since each value is humanly readable. Declaring constants will lead to inconsistent usage where some users use the 'n' byte literal, while other users reference the
jsontext.KindNullconstant. This is similar problem to the introduction of thehttp.MethodGetconstant, which has led to inconsistency in codebases where the "GET" literal is more frequently used (~75% of the time).
I don't feel like this comparison is fair since:
net/httpdoesn't define atype Method string;http.MethodGetisn't a typed constant- The enumerated values are literally the value of the HTTP method vs a single-character representation used here.
I don't think it's difficult to learn/understand, but I'd prefer constants. I tend to prefer them so gopls recommends correct values and to avoid accidental misspellings that the compiler can catch.
Comment From: prattmic
Apologies in advance for getting into bikeshedding territory:
We have format:array, format:base64, etc, but nocase and strictcase. Should these be more consistent by using naming like case:ignore, case:strict?
Since nocase and strictcase are mutually exclusive, the key:value form might make this a bit more clear at a glance.
Comment From: timbray
The design seems sound, although I'd have hoped for fewer options.
On the performance front, what do the benchmarks show about memory consumption and gc behavior? I found v1 to use unreasonable amounts of memory, and this included the streaming interface.
Comment From: davecb
Yay , you implemented v1 in terms of v2 !!!
In case you think that's minor, updaters and downdaters are much-reinvented improvements, used in Multics, Solaris and GNU libc. All too many other folks don't and suffer from "flag days" when everything has to change at once (:-))
For more detail on why this is cool, see Paul Stachour's "Jack" article , https://cacm.acm.org/practice/you-dont-know-jack-about-software-maintenance/
Comment From: nemith
While I agree with the reasoning of the WithLegacySemantics suffix on options I have concerns over it use
- The options are now much more ambiguous in what they do. If the more specific option names were nonoptimal cause they didn't cover all behaviors the new ones are the opposite and now loose a lost of semantic meaning.
- Many options have this suffix which means that at a cursory glance it may be easy to mix them up or look over them.
Given the options I would rather have a more specific name that may include other behaviors than a bunch of similarly named ambiguous options that really require historical context to fully understand.
However given these are mostly used for transitional and discourages for general use maybe that is ok?
Comment From: dsnet
@prattmic, great suggestion. nocase and strictcase were added at different points in time, so it wasn't obvious when each of them were implemented that we should just combine them.
Comment From: dsnet
what do the benchmarks show about memory consumption and gc behavior?
@timbray: The v2 implementation allocates less than most alternatives:
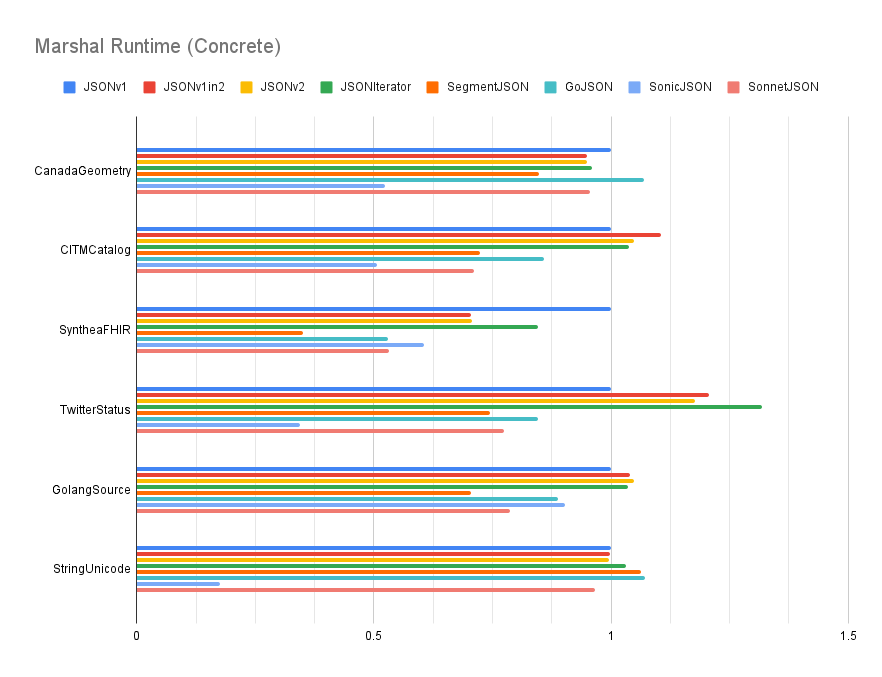{kind=link}
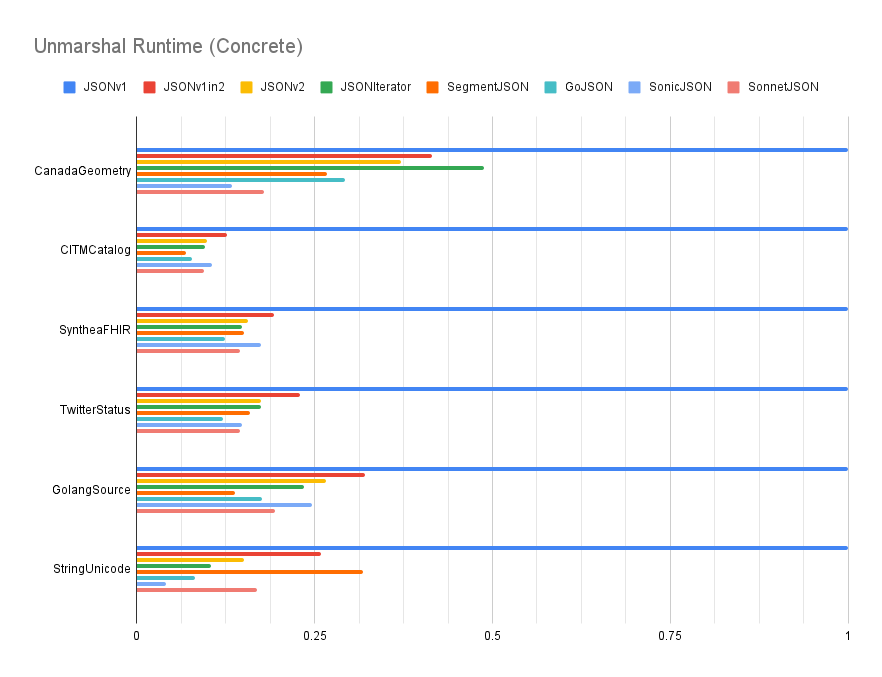{kind=link}
This is most likely due to v2's use of a string intern cache.
Aside from strings, unfortunately most other data structures fundamentally have to be allocated. The memory regions discussion #70257 could provide a way to batch allocations together in a single region, which is freed all together.
Comment From: dsnet
@nemith, the number of legacy options makes me sad as well. When we first started to implement v1 in terms of v2, we thought we could have just a few targeted options with clear names, but it became increasingly clear that there were too many odd behaviors of v1 to have individual options for. Many of these behaviors are arguably bugs, but have practically become stable behavior in v1 as a result of Hyrum's Law.
Of all the options to achieve 100% known compatibility, they roughly fell into three categories:
-
Features that were reasonable for someone to want, but not as the default behavior (e.g.,
jsonv2.Deterministic,jsonv2.FormatNilMapAsNull,jsonv2.FormatNilSliceAsNull,jsonv2.MatchCaseInsensitiveNames,jsontext.AllowDuplicateNames,jsontext.AllowInvalidUTF8,jsontext.EscapeForHTML, andjsontext.EscapeForJS). These were all given specific names and are declared in the "json/v2" or "jsontext" packages for easy accessibility. -
Behavior that are arguably bugs, unspecified, or mostly backwards compatible (e.g.,
jsonv1.CallMethodsWithLegacySemantics,jsonv1.EscapeInvalidUTF8,jsonv1.MatchCaseSensitiveDelimiter,jsonv1.MergeWithLegacySemantics,jsonv1.ReportErrorsWithLegacySemantics,jsonv1.StringifyWithLegacySemantics,jsonv1.UnmarshalArrayFromAnyLength). I suspect that 99% of use cases will not be affected by these options. -
Functionality that notably changed in v2, but there is some backwards compatible change that type authors can make to make the representation identical under both v1 or v2:
-
OmitEmptyWithLegacyDefinitioncontrols the behavior ofomitempty, where v1 and v2 diverge for Go bools, numbers, pointers, and interfaces. These can be migrated to useomitzero, which will behave the same way as legacyomitempty. -
FormatBytesWithLegacySemanticscontrols several buggy behavior with binary encoding and also controls how[N]byteare serialized. Using theformat:arrayoption, type authors could make byte arrays serialize as they do in v1. -
FormatTimeWithLegacySemanticscontrols a parsing bug with RFC 3339 and also controls howtime.Durationis serialized. Using theformat:nanooption, type authors could make durations serialize as they do in v1.
-
Options in category 3 could use further refinement. For example, it might make sense to split:
* FormatByteArraysAsArrays out from FormatBytesWithLegacySemantics
* FormatDurationAsNanos out from FormatTimeWithLegacySemantics
Comment From: dsnet
Will json/v2 also include string format for unmarshaling into []byte and [N]byte types with no translation
@a-pav In the end we decided to focus on what's blocking v2 from getting the stdlib, so we made a conscious decision not to include that for the initial release. Supporting format:string for []byte and [N]byte types is worth proposing soon after as a follow-up.
I'll update the "Changed from discussion" to include a sub-section on changes that we did not end making.
Comment From: willfaught
It seems odd for Encoder method names to use "Write" instead of "Encode", and for Decoder method names to use "Read" instead of "Decode":
func (*Encoder) WriteToken(Token) error
func (*Encoder) WriteValue(Value) error
func (*Decoder) ReadToken() (Token, error)
func (*Decoder) ReadValue() (Value, error)
because encoding/json uses "Encode" and "Decode":
func (enc *Encoder) Encode(v any) error
func (dec *Decoder) Decode(v any) error
and encoding/xml does too:
func (enc *Encoder) Encode(v any) error
func (enc *Encoder) EncodeToken(t Token) error
func (d *Decoder) Decode(v any) error
Instead, the V2 declarations now generally use the To and From suffixes to indicate that they support streaming. This follows after the convention established by io.WriterTo and io.ReaderFrom.
WriterTo and ReaderFrom push to, or pull from, entire byte streams. That seems useful for JSON marshaling too. Users have already written MarshalJSON/UnmarshalJSON methods, and enabling users to add a byte stream version of those methods alongside would be an nice way to opt into better performance with little effort. The MarshalJSON/UnmarshalJSON implementations could just be calls to the stream version with a bytes.Buffer.
Perhaps something like:
MarshalJSONToWriter(io.Writer, Options) error
UnmarshalJSONFromReader(io.Reader, Options) error
Then we'd have:
MarshalJSONToEncoder(*jsontext.Encoder, Options) error
UnmarshalJSONFromDecoder(*jsontext.Decoder, Options) error
This is a similar problem to the introduction of the http.MethodGet constant, which has led to inconsistency in codebases where the "GET" literal is more frequently used (~75% of the time).
I would guess that had more to do with enabling custom or future standard HTTP methods.
Having to remember " is for strings and 0 is for numbers seems error-prone. Having declared constants seems safer. I suspect most users won't write kind values by hand. Personally, I would end up declaring my own constants just to be safe. The library should save me the trouble. If someone wants to take their chances with literals, they can still do that.
There appears to be a misspelling in the name jsonflags.WithinArshalCall at https://github.com/go-json-experiment/json/blob/4e0381018ad6/jsontext/encode.go#L105C21-L105C47.
Comment From: willfaught
The MarshalJSONTo, UnmarshalJSONFrom, MarshalToFunc, and UnmarshalFromFunc methods and functions take in a singular Options value instead of a variadic list because the Options type can represent a set of options.
Why do these take an Options? Is it just in case they invoke the JSON library themselves? If so, what is an example of when that would be useful? And if so, why not have Encoder.Options() Options and Decoder.Options() Options instead to avoid the Options parameter?
// DefaultOptionsV2 is the full set of all options that define v2 semantics. // It is equivalent to all options under [Options], [encoding/json.Options], // and [encoding/json/jsontext.Options] being set to false or the zero value, // except for the options related to whitespace formatting.
Does this mean the whitespace formatting options are all true by default?
Which options are related to whitespace formatting? I see comments like // affects marshal and unmarshal and // affects encode only, but none flagging whitespace behavior. In order to understand what this behavior is, I have to read the documentation for every option, and even then, perhaps have to guess.
Is it possible to have all default values be zero values? If so, then we wouldn't need this declaration.
// JoinOptions composes multiple options values to together: // out := JoinOptions(opts...) // which is analogous to making a new map and copying the options over: // out := make(Options)
Apparently Options is a map? Or is that just for illustrative purposes? What is the underlying type of Options?
func NewEncoder(io.Writer, ...Options) Encoder [...] func UnmarshalDecode(in jsontext.Decoder, out any, opts ...Options) error
There are a lot of functions that take variadic Options. Why not a single Options, since multiple Options can be combined with JoinOptions, like for MarshalJSONTo, UnmarshalJSONFrom, MarshalToFunc, and UnmarshalFromFunc? Conversely, why not just deal with []Option everywhere, like functional options?
Comment From: willfaught
jsontext.SyntacticError.JSONPointer and json.SemanticError.{JSONPointer,JSONKind,JSONValue} seem to stutter. Dropping the "JSON" wouldn't be confusing.
type Options = jsonopts.Options
This declaration in jsonv1 doesn't seem to be used.
// Options configure Marshal, MarshalWrite, MarshalEncode, // Unmarshal, UnmarshalRead, and UnmarshalDecode with specific features. // Each function takes in a variadic list of options, where properties set // in latter options override the value of previously set properties.
Missing square brackets around declaration names.
"Options configure" seems like a number disagreement between subject and verb. Options is a singular type, so it should be "Options configures".
func MarshalToFuncT any Marshalers func UnmarshalFromFuncT any Unmarshalers
It seems odd for Options to not be the second param in fn, like in MarshalJSONTo and UnmarshalJSONFrom.
Comment From: willfaught
func DefaultOptionsV2() Options
I don't see a DefaultOptionsV1 in jsonv2, so I don't see a need for the V2 suffix in jsonv2. Users could use qualified imports to distinguish between the two declarations in jsonv1 and jsonv2.
func DefaultOptionsV1() jsonopts.Options
Exporting this perpetuates bad JSON and bad behavior with jsonv2, and complicates the public options API. In my opinion, there shouldn't be a way to enable this behavior in jsonv2 unless it's coming from jsonv1 under the hood. Options like jsontext.AllowInvalidUTF8 should be moved to an internal package shared by jsonv1, jsonv2, and jsontext to hide them. That way, jsonv1 gets the improved performance of jsonv2, the jsonv1 and jsonv2 public API isn't cluttered by compatibility concerns, and jsonv1 users are motivated to upgrade to jsonv2 for better behavior and features.
Comment From: willfaught
func AllowDuplicateNames(v bool) Options // affects encode and decode
How would this affect encoding?
Comment From: willfaught
Why aren't https://github.com/go-json-experiment/json/blob/master/arshal*.go files spelled marshal*.go?
Perhaps GitHub IntelliSense is failing me, but I don't see that the Value methods that take Options are used in the implementation, so I assume they're meant for users only. jsonv1.RawMessage is changed to alias jsontext.Value, so they seem to be analogous. I've never used RawMessage myself, but its documentation says it's for delaying a JSON decoding, or precomputing a JSON encoding, in the context of being a Marshaler/Unmarshaler value. I don't see how the above-mentioned Value methods relate to those use cases; they seem to only be for encoding. When would we want to use them instead of using the Value with an Encoder or Decoder?
Comment From: willfaught
The names in encoding/json/jsontext stutter, and don't seem to conform to the stdlib pattern of using directories as namespaces, even three directories deep:
- crypto/tls/fipsonly
- crypto/x509/pkix
- database/sql/driver
- go/build/constraint
- go/doc/comment
- image/color/palette
- net/http/cgi
- net/http/cookiejar
- net/http/fcgi
- net/http/pprof
- net/rpc/jsonrpc
- text/template/parse
The only exceptions to this pattern I could find are HTTP-related, which were probably authored at around the same time:
- net/http/httptest
- net/http/httptrace
- net/http/httputil
Yet even those names are the minority of HTTP sub-package names. No "http" prefixes here:
- net/http/cgi
- net/http/cookiejar
- net/http/fcgi
- net/http/pprof
I don't see why encoding/json/jsontext is idiomatic, or qualifies for an exception. What is the reasoning for using encoding/json/jsontext that would not also require encoding/json to be encoding/encodingjson, or encoding/json/jsontext to be encoding/encodingjson/encodingjsontext? What would justify it being an exception to the stdlib pattern that would not also apply to text/template or go/doc/comment? The one exception would seem to be net/rpc/jsonrpc (except for the parent name "rpc" being at the end instead of the beginning), but it's not an exception because it implements something actually called "JSON-RPC".
encoding/json/text doesn't stutter, it fits the stdlib pattern, and imports of it can be qualified to avoid conflicts with other identifiers.
Comment From: willfaught
It seems like jsontext belongs under encoding/json/v2. It seems strange for v1 to have both encoding and marshaling, but for v2 to have only marshaling. If encoding compatibility needs to be broken in the future, we would end up with encoding/json/jsontext/v2 and encoding/json/v3, and it would be unclear that they both go together. It seems better to version the encoding and marshaling together with encoding/json/v2/jsontext.
Comment From: willfaught
The package name "jsontext" doesn't seem right to me. JSON is text. It would be like naming a package "jpegbinary". Perhaps "syntax" or "jsonsyntax" would be better than "text" or "jsontext".
encoding/json/jsontext having the encoding code breaks the stdlib pattern of encoders being in an encoding (possibly versioned) child package. It seems wrong to reach for an encoding/foo package for marshaling, and an encoding/foo/bar package for encoding. If anything, to match the stdlib pattern, it seems like we should have encoding/json/v2 be the encoding code and encoding/json/marshaling be the marshaling code, but then the marshaling import path is the longer one, which is what 99.999999% of users will use, so that doesn't make sense either.
Why are we splitting the encoding and marshaling code into separate packages, again? What I mean is, where is the concrete evidence that justifies the split in terms of who asked for it, the scenarios they need it for, the min/avg/max space savings in those scenarios, how important those savings are in those scenarios, etc. @dsnet said in the GitHub discussion for this that his employer Tailscale needs it to avoid the slightly larger binary size that using reflection causes, but one employer saving a few megabytes of memory is alone hardly justification for the cost of splitting the encoding and marshaling code. Having all the code together is easy to use and fits the stdlib pattern, so it seems to me there needs to be a very compelling reason for the interests of the majority of the Go Community to be served by doing this split. As shown above, this design isn't all upside, it's striking a trade-off, and for us to judge whether it's the right trade-off, we need that concrete evidence. (Apologies if I missed it.)
Where is the line drawn for using reflection? Is reflect a poison pill? Is reflect code to be avoided as much as possible? It appears that net/http uses reflect; was that a mistake? Was it a mistake to not put all marshaling code into separate marshaling/* packages from the outset? If the Go Team really does go for this split, what is their guidance for best practices regarding designing APIs and package boundaries around the impact that reflection has on surrounding code? I'd never heard of wanting to avoid the size cost of reflection until the GitHub discussion for this (but perhaps that's just me).
Comment From: josharian
Love it.
I’ve painted myself into naming corners using the word Legacy. I’d suggest s/Legacy/V1/g. Shorter and more precise.
Comment From: dsnet
Hi @willfaught, I appreciate your great enthusiasm in providing feedback. I believe it be more productive to condense your thoughts down to the most significant ideas so that we don’t overwhelm the discussion. 20+ thoughts spread throughout 9 distinct posts is challenging for others to follow and engage with even they are worth discussing. We appreciate your thoughts, but not all thoughts are equally fruitful to discuss.
This particular proposal is paired with a working prototype, so some of the questions could be answered on your own by running some code in a playground. Suggestions about spelling errors or nuances of documentation are better filed at github.com/go-json-experiment/json. Some of the points you raised have already been addressed in the prior discussion (#63397). While ideas may have merit, engineering is about tradeoffs and so we sometimes still choose to go down a different path even when presented with valid counter-arguments.
For the sake of this proposal, we should focus on API that cannot be changed once this has been proposed and merged. I recommend choosing a small set of issues that you believe are the most significant and bring the most value. You’re welcome to re-raise a concern already discussed, but let’s aim to keep it a singular issue or two that you believe is most important.
In general, it’s most effective to keep a single comment to a single cohesive thought. GitHub supports emojis, which allows others to signal whether they agree (or disagree) with the idea. Multiple thoughts per comment confuses this reaction mechanism. For example, @prattmic’s comment on naming of nocase and strictcase was a concise and singular idea, making it possible for people to :+1: the comment signaling support for the suggestion. If someone has already made a similar argument to what you’re about to make, then it’s best to upvote the earlier argument rather than to reiterate the same thing.
Comment From: dsnet
The package name "jsontext" doesn't seem right to me.
The term "jsontext" comes from RFC 8259, section 2, where "JSON text" is defined as "a sequence of tokens" or "a serialized value". This matches the Token and Value constructs in the package.
Comment From: dsnet
Why do [MarshalerTo] and [UnmarshalerFrom] take an Options? ... why not have Encoder.Options() Options and Decoder.Options() Options instead to avoid the Options parameter?
This a question of whether jsontext.Encoder and jsontext.Decoder are supposed purely concerned with syntax or can it also store semantic options even if they have no impact on the operation of the encoder or decoder. The fact that we have a single Options type makes it technically possible for the coders to store semantic options. This was formerly impossible when the prototype API used to use option structs. Given that we have now embraced the variadic Options type, your suggestion is worth considering.
Comment From: dsnet
jsontext.SyntacticError.JSONPointerandjson.SemanticError.{JSONPointer,JSONKind,JSONValue}seem to stutter.
A SemanticError describes an error bridging two different type systems (i.e., Go and JSON). The Go or JSON prefix in the field name is to be explicit about which type system some error context is stemming from. Given that SemanticError already uses the JSON prefix, we made SyntacticError be consistent in it's naming of fields.
Comment From: liggitt
- In v1, a Go byte array is represented as a JSON array of JSON numbers. In contrast, in v2 a Go byte array is represented as a Base64-encoded JSON string.
Is this description backwards? v1 serializes []byte to base64 string... https://go.dev/play/p/E-yrM133WyP
The jsonv1.FormatBytesWithLegacySemantics option controls this behavior difference. To explicitly specify a Go struct field to use a particular representation, either the format:array or format:base64 field option can be specified.
Is this proposing that json/v2 (when used directly) will serialize []byte to a JSON array of JSON numbers by default, but can be modified to marshal to base64 via format:base64?
Comment From: dsnet
I suspect the confusion arises from "Go byte array", which would be a [N]byte, rather than a []byte. I modified the proposal to make this more clear. https://go.dev/play/p/95mlEXaaeNA
In v2, we switched the default behavior since static analysis of Go code seemed to indicate that [N]byte arrays almost universally contained binary data of some kind (e.g., encryption keys, hashes, etc.). There were less common exceptions to the norm such as [4]byte, which would probably be more naturally represented as a JSON array (e.g., [192, 168, 0, 1]).
Comment From: puellanivis
An interesting corner case:
For example, a Go struct with only unexported fields cannot be serialized.
How does this handle struct{} types? Since technically it both contains only unexported fields, and also only exported fields, due to them both being vacuously true statements.
Comment From: dsnet
@puellanivis, unfortunately we needed to leave out some details in the proposal keep it more concise. The package docs of the prototype says:
Marshaling or unmarshaling a non-empty struct without any JSON representable fields results in a
SemanticError. Unexported fields must not have anyjsontags except forjson:"-".
If that's not clear, we can improve the documentation or change the behavior. The motivation for this change is seeing how often a new Go programmer is surprised when trying to marshal certain struct types result in {} because exported-ness based on casing is a novel idea unique to Go.
Comment From: mateusz834
Marshaling or unmarshaling a non-empty struct
What a non-empty struct means? non-zero?
Comment From: dsnet
In the preceding paragraph, which wasn't quoted, it starts with:
Every Go struct corresponds to a list of JSON representable fields which is constructed by performing a breadth-first search over all struct fields (excluding unexported or ignored fields) ...
Thus, when the next paragraph says "non-empty struct", it's referring to the preceding definition such that a "non-empty struct" is a struct that corresponds to an empty "list of JSON representable fields ...".
Comment From: dsnet
I just filed #71611 as a sub-issue to further explore one of @willfaught's earlier ideas. We can use GitHub's new sub-issue feature to have more targeted discussion on specific topics.
Comment From: mateusz834
How does this handle struct{} types? Since technically it both contains only unexported fields, and also only exported fields, due to them both being vacuously true statements.
type Sth struct {
Sth struct{}
}
v, err := json.Marshal(Sth{})
if err != nil {
panic(err)
}
fmt.Printf("v: %s\n", v) // v: {"Sth":{}}
Thus, when the next paragraph says "non-empty struct", it's referring to the preceding definition such that a "non-empty struct" is a struct that corresponds to an empty "list of JSON representable fields ...".
The example above has a struct{} field, which has "an empty "list of JSON representable fields"" and does not return an error. So it seems to be except struct{}.
Comment From: dsnet
@mateusz834, I apologize. I think I confused myself in my earlier comment.
a non-empty struct without any JSON representable fields
A "non-empty struct" should be defined as whether reflect.Type.NumFields > 0 and "any JSON representable fields" should be defined according to the preceding paragraph. We can make that more clear in the docs.
Comment From: mateusz834
~~There is no way to clone Options, see https://github.com/golang/go/issues/71611#issuecomment-2643932472.~~ I was wrong: https://github.com/golang/go/issues/71611#issuecomment-2644068294
Comment From: mitar
@dsnet I still think current API has an issue which cannot be in the future added without breaking changes, so I would really prefer if it is added in v2:
- Custom marshal methods cannot skip marshaling the value (in an array or as object value). I think the workaround you hinted at cannot really work and I do not think we can make add it in the future without changing how those marshaling methods work (e.g., parent JSON marshal calls have to check error return value).
- Custom marshal methods should have access to struct tags for the value, so that they can check if user set
omitemptyor something similar. If we do not add this now, then in those rare but probably existing cases when code contains a value with type with custom marshal method and a struct tag would be in the future potentially encoded differently.
So not sure how to proceed here. I understand that you are reluctant to add those but I do think those are critical features which really limit what can one do currently in custom marshal methods and what can be done in the future.
Comment From: glenjamin
In v1, it's possible to unmarshal a multi-gigabyte JSON stream by using Token to read [, then looping on Decode to get a value, followed by either , or ].
I was about to comment on how this would be done in v2, but I've looked at the more detailled godocs in the implementation and I see that UnmarshalDecode does not read to EOF, it only reads one value - it might be worth noting that in the proposal summary in case someone else wonders this.
Comment From: dsnet
@glenjamin, thanks. I added a sentence to point this out.
Comment From: glenjamin
One hard-to-retrofit detail that isn't mentioned here is whether there could be some way to plumb the value of the format tag into a custom struct's Marshaler or Unmarshaler - to allow custom types to support multiple format variants.
I checked the previous discussion, and found this https://github.com/golang/go/discussions/63397#discussioncomment-7206575
Which appears to conclude that this is quite difficult/expensive and has semantics with an open question - but roughly equivalent behaviour can be achieved using the Caller-specified customization feature.
Comment From: dsnet
@mitar and @glenjamin, we're getting into the territory of user-defined options or user-access to all options, both of which I still believe generally can be added on top of the current API.
MarshalJSONToshould be able to reimplement everything struct tags can achieve. Currently you cannot replicateomitemptyfor example.
We decided early on that this isn't a practical goal to achieve.
Exposing omitempty and format suffers from the challenge that this option is scoped only for the next sub-value rather than applying to the entirety of the sub-value. This is a subtle distinction, but a critical one and I don't know how to expose that without a complicated API.
inline is also another option that does not play well with T.MarshalJSONTo. Fundamentally, we need to know beforehand the list of possible JSON members that are supported by type T, but if the representation is a Turing-complete implementation, how can we derive that list? We could add another API method to require that T self report what JSON members it supports, but now we're getting increasingly more complicated for questionable return. For the time being, we forbid an inline type to implement the MarshalerJSONTo to keep the future open.
I must say I do not get how your example can simulate behavior of, for example,
omitempty
I'm confused by what you mean by "simulate" the behavior of omitempty. The omitempty option does nothing to change the JSON representation of the field that it is marked on. It omits the field if it serialized as a JSON null, {}, [] or "". Thus, if a user-defined MarshalJSONTo method returns {} and the field is marked as omitempty, then the field will still be omitted. Notice that omitempty is evaluated at the layer of the parent Go struct, rather than by the child struct field (and therefore I question the utility of plumbing omitempty down to the child field's MarshalJSONTo implementation.
there could be some way to plumb the value of the
formattag into a custom struct'sMarshalerorUnmarshaler- to allow custom types to support multiple format variants.
The feature of user-defined options or access to builtin options is a sufficiently large topic that we should probably turn this into a sub-issue. I can file one later today or this weekend as a polished version of my prototype in https://github.com/go-json-experiment/json/pull/138. I recommend giving that a read.
Comment From: mitar
This is a subtle distinction, but a critical one and I don't know how to expose that without a complicated API.
As I mentioned, I would just solve this by simply providing whole struct tag, maybe even unparsed, for current value, through options. So other sub-values would then get other values for struct tags (maybe even empty struct tags). Am I missing something?
if a user-defined
MarshalJSONTomethod returns{}and the field is marked asomitempty, then the field will still be omitted.
What? This is awesome! But this is new behavior in v2. How did I miss that. I see now also OmitEmptyWithLegacyDefinition. And yes, this makes things much easier.
I am satisfied with this. Thanks.
Comment From: doggedOwl
Custom marshal methods should have access to struct tags for the value, so that they can check if user set omitempty or something similar. If we do not add this now, then in those rare but probably existing cases when code contains a value with type with custom marshal method and a struct tag would be in the future potentially encoded differently.
Maybe the omitempty here is the wrong tag to focus to but generally I would think this is controlled by the main marshal and not the custom ones. For sure I would not like surprises when custom marshals (defined in a dependency) get to choose to honor a behaviour or not.
Comment From: puellanivis
@puellanivis, unfortunately we needed to leave out some details in the proposal keep it more concise. The package docs of the prototype says:
Marshaling or unmarshaling a non-empty struct without any JSON representable fields results in a
SemanticError. Unexported fields must not have anyjsontags except forjson:"-".If that's not clear, we can improve the documentation or change the behavior. The motivation for this change is seeing how often a new Go programmer is surprised when trying to marshal certain struct types result in
{}because exported-ness based on casing is a novel idea unique to Go.
Documentation is clear. 👍
Comment From: jdemeyer
In contrast, in v2 a time.Duration is represented as a JSON string containing the formatted duration (e.g., "1h2m3.456s")
I still find this a strange choice, as the format is Go-specific. Since JSON is often meant to communicate with applications written in other programming languages, I would find the "sec" format (floating-point number of seconds) a much more natural default (it's just a number: easy to work with in any programming language). I already suggested that here https://github.com/golang/go/discussions/63397#discussioncomment-10936895 but then the discussion got side-tracked by the ISO 8601 duration format.
Also, I think the proposal should clarify whether the formats "sec", "milli", "micro" marshal as floating-point or integer (I would assume floating-point but given that https://pkg.go.dev/time#Duration.Milliseconds returns int64 I think it's good to make that explicit in documentation).
Comment From: dsnet
Hi @jdemeyer, I filed #71631 to further discuss the default representation for time.Duration since it's sufficiently large topic. Let's move future discussion there. Thanks!
Comment From: seankhliao
I don't think the argument that "GET" is used over http.MethodGet applies: plain GET is much more familiar to users from other environments, whether that be other languages https://developer.mozilla.org/en-US/docs/Web/API/RequestInit#method, documentation https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods, or cli tooling (curl -X GET).
The same can't be said for json token kinds, you likely rarely write custom json encoders/decoders, and it would be much more readable to have defined constants, and nicer to have the editor suggest values. While writing the defined values directly is short, they are somewhat arbitrary and "magic".
Comment From: seankhliao
This proposal introduces many new formatting options, but this poses a problem for online systems that wish to migrate the representations of any existing fields, see https://github.com/golang/go/issues/10275#issuecomment-1190572632
While it's possible for custom types to implement dual v2/v1 decoding in UnmarshalJSONFrom, and it doesn't seem possible for built in types controlled with format (Unmarshalers don't see struct tags, and apply to all types at the same time).
I propose an additional option, func FallbackUnmarshal(v bool) Options:
when set, unmarshaling proceeds with v2 semantics (format or UnmarshalJSONFrom) but if it errors, it tries v1 semantics (original encoding, UnmarshalJSON).
This gives us a reasonable path forward for changing the serialization, or potentially adding the new json marshaler / unmarshaler output for standard library types for encoding/json/v2.
The path forwards for changing the field serialization would then be:
1. run new systems with v2.Unmarshal(..., FallbackUnmarshal()), v1.Marshal
2. upgrade any existing systems with same settings
3. switch from v1.Marshal to v2.Marshal
4. remove FallbackUnmarshal
Comment From: mvdan
@seankhliao it seems to me like named constants for the token types could be added later; is there a reason why such a change must be considered as part of the initial proposal?
Comment From: seankhliao
It's rare to go back to change already working code, so we'll be stuck with some difficult to read code for quite some time? afaik no other stdlib api does this where there are only a few special values that are valid, but doesn't actually define them in code.
If there's an inconsistency argument, it's that json is inconsistent with the rest of std, all the other exposed kinds have constants, ~nobody uses their raw forms. Not adding the constants now generates more inconsistency if/when it's proposed in a follow up. * https://pkg.go.dev/go/constant#Kind * https://pkg.go.dev/reflect#Kind * https://pkg.go.dev/log/slog#Kind
Comment From: dsnet
@mitar and @glenjamin, I filed #71664 regarding user-specified format flags and option values. We can continue further discussion on that topic in that issue.
Comment From: mateusz834
I wonder whether exposing an unexported type through a const is a good idea, instead of var SkipFunc error = jsonError("skip function")?
In the std the only place where we do so (or at least that i am aware of is: encoding/binary).
// SkipFunc may be returned by MarshalToFunc and UnmarshalFromFunc functions.
// Any function that returns SkipFunc must not cause observable side effects
// on the provided Encoder or Decoder.
const SkipFunc = jsonError("skip function")
Also it probably should be named ErrSkipFunc.
EDIT: I guess that keeping it as const SkipFunc = jsonError would also cause unnecessary allocations when returning this as an error.
Comment From: dsnet
I don't feel strongly about using a constant. If we do it for SkipFunc, we would probably want to consistently do that for all of our sentinel errors. As you noticed, we don't really use constants for anywhere else in the stdlib (to my knowledge) for errors.
cause unnecessary allocations
I'm fairly certain storing a constant into an interface does not allocate, so that's not a problem.
Also it probably should be named
ErrSkipFunc.
The naming was to be consistent with other sentinel errors that aren't actually errors (e.g., io.EOF, fs.SkipAll, fs.SkipDir).
Comment From: mateusz834
I don't feel strongly about using a constant.
People might do weird stuff like: var str = string(json.SkipFunc), not sure why but then you have to think about these kind of stuff in terms of backwards compatibility.
Comment From: Merovius
If we use a string-constant as a sentinel, then every if err == SkipFunc comparison needs to potentially compare the entire string to evaluate to false.
[edit] though, if there is a unique unexported string type per sentinel, that wouldn't be the case, but at that point, why use a constant at all, instead of an unexported type xyzErr struct{}.
Comment From: mateusz834
I don't feel strongly about using a constant.
People might do weird stuff like: var str = string(json.SkipFunc), not sure why but then you have to think about these kind of stuff in terms of backwards compatibility. But on the other hand var can be reassigned, but we can always use type assertion in encoding/json/v2, rather than err == SkipFunc, so that if they do so then it would not work.
we use a string-constant as a sentinel, then every if err == SkipFunc comparison needs to potentially compare the entire string to evaluate to false.
It can be a type skipFuncError byte, then we don't have to worry about that.
Comment From: Merovius
The suggestion of using constants for errors periodically comes up. And personally, I remain strongly unconvinced of its advantages. Which, as far as I can tell, are only that no one can re-assign the value. Which always seemed like a contrived problem to me. Because even if someone would do that, it would only become a real problem if the value is not comparable (which will quickly panic) or if people also stored the original value somewhere.
Weighing these supposed advantages of constants over the disadvantages - for example, explaining const SkipFunc = skipFuncError(0) vs. explaining var SkipFunc = errors.New("skip function") - to me always gets me to oppose the idea. I think errors.New is a fine mechanism for sentinel errors and I honestly don't really understand why people keep trying to innovate on it.
Ultimately, I think this is a relatively minor detail, though. So it's not a hill I'll die on.
Comment From: mitar
I would ask that sentinel errors are errors and not constants, because then you can wrap them up with other errors, maybe adding some semantic meaning or logging to it (imagine a use case where somewhere deep inside multiple layers of calling, a function decides to abort and return SkipFunc, but maybe want to annotate to higher layers (before returning from custom marshal function) why it decided to skip.
Comment From: seankhliao
I just saw https://github.com/golang/go/issues/10275#issuecomment-1197093855 , should net/url.URL get special treatment this time round for marshal/unmarshal?
Comment From: dsnet
I believe we need a principled way to think through what types get special treatment. At present the only specially treated types are time.Time and time.Duration. These are arguably fundamental types that practically every program needs to know about.
Other types like regexp.Regexp, net.IP, url.URL, big.Int, big.Float, big.Rat etc. should properly self-implement their representation through encoding.TextMarshaler or json.Marshaler. The fact that net.URL doesn't do so is a historical mistake, but it seems the right answer is that there should one day be a v2 url.URL type. I don't think the v2 "json" package is responsible for fixing the mistaken representation of various stdlib types. We want to limit the dependency scope of v2 "json" to something reasonable.
Comment From: mitar
but it seems the right answer is that there should one day be a v2 url.URL type.
Yea, but is there a longer list of fixes needed for url.URL which would warrant a new major version? Because just JSON representation will not be enough for v2.
So maybe while theoretically this should be fixed in url.URL, I think this use case is common enough that having a special case for it could be the simplest fix here for an unfortunate situation.
Comment From: seankhliao
what if encoding/json/v2 didn't special case time and duration either, instead having them implement json/v2.MarshalerTo, and json/v2.UnmarshalerFrom, and accept formatting through #71664 ?
Comment From: dsnet
The "time" package cannot depend on "json", which is another argument that "time" is a package with fundamental types.
Comment From: josharian
The "time" package cannot depend on "json", which is another argument that "time" is a package with fundamental types.
The fact that a package has to import json in order to control its json encoding is pretty unfortunate, because @seankhliao's suggestion feels like the fundamentally correct approach.
Comment From: seankhliao
implementation of the interface only requires it depend on jsontext though?
Comment From: dsnet
implementation of the interface only requires it depend on jsontext though?
True, and while we tried to keep the "jsontext" package reduced in dependencies, it's still notably more dependencies than what "time" has. For example, JSON processing needs to depend on various Unicode and string conversation functionality that the "time" package goes out of its way to avoid. It even avoids the "strings" package.
Comment From: nemith
From the example for Number I see this
go
if dec.PeekKind() == '0' {
*val = jsontext.Value(nil)
}
Which makes me even more think that constants are the way to go. Reading this as "peeking at the kind to see if it is zero" and then taking a couple of seconds to realize that 0 mean number is just too confusing for me. This is made worse that 0 (not '0' an invalid kind.
I still find the analogy to HTTP methods to be flawed as the use in spec and intentional expansion (new methods are allowed in HTTP are new tokens going to ever be in JSON?) to not be the same.
If the worry is abuse in use then just make the Kind completely opaque? (Edit: It is also unclear why Kind needs to be byte character at all. I am not against it and it feels clever but the HTTP argument goes away when they are represented by anything else)
I am also already missing json.Number (although it seems like it can be reimplemented pretty straightforwardly)
Comment From: dsnet
I just filed #71756 for adding Kind constants. Let's continue any further discussion there. Thanks.
Comment From: seankhliao
71756 raises the prospect of another package. Can enough declarations move such that the MarshalerTo / UnmarshalerFrom interface methods take an interface instead of a concrete Encoder / Decoder?
Comment From: dsnet
I'm not sure I see the connection with splitting "jsontext" apart and whether MarshalerTo should use an encoder interface instead of a concrete *jsontext.Encoder. The primary issue there was regarding performance since the Write methods are hotly called (where the calling overhead is often more bytes than the JSON payload itself!). An interface is great at allowing for multiple implementations, but makes them all equally slower since every single method is now a virtual method call. A vast majority of interface implementations will probably be *jsontext.Encoder and so it seems like an unfortunate hit to performance for almost all users for some benefit in flexibility. Also, the compiler can no longer prove that arguments that go through a interface method do not escape, further hurting performance.
In the future, we could technically still support third-party encoder implementations by allowing users to register a custom implementation into the jsontext.Encoder implementation. When jsontext.Encoder.WriteToken is called, it checks (with a single nil function pointer check) if there is a custom implementation registered and calls that. This approach would keep the common-case usage with *jsontext.Encoder fast, while still supporting custom implementations (albeit with a somewhat strange API).
Thus far, I haven't been convinced of the need for third-party implementations to justify that the flexibility wins outweights the performance hit of interfaces.
Comment From: seankhliao
I was thinking less about third party implementations, and more about making the interfaces implementable without pulling in so many dependencies.
Comment From: dsnet
I see, so in relation to the earlier discussion that "time" should directly implement MarshalerTo? I can see a benefit to that. While it would be nice if "time" could properly implement JSON itself by only referencing a lightweight interface (with minimal dependencies), is that benefit worth the performance costs? I think probably not.
Comment From: huww98
I'm trying to implement UnmarshalerFrom for my struct. It seems that I cannot reach comparable performance without access to the DisableNamespace method. Can we somehow expose this from jsontext package? So that I can implement my own more efficient duplicate name check in UnmarshalFrom method. User can set AllowDuplicateNames, but that will affects all types.
I propose adding this Method to jsontext.Decoder:
// DisableDuplicateNameCheck disables the duplicate name check for the current decoding object for better performance.
// Call this just after reading '{' token.
// Returns whether the caller should run its own check, depending on whether [AllowDuplicateNames] is set.
DisableDuplicateNameCheck() bool
Comment From: willfaught
The package name "jsontext" doesn't seem right to me.
The term "jsontext" comes from RFC 8259, section 2, where "JSON text" is defined as "a sequence of tokens" or "a serialized value". This matches the Token and Value constructs in the package.
@dnet I'd forgotten about that point, which you brought up in the GitHub discussion:
It's called "jsontext" because it literally handles "JSON text", which is specifically called out as a term in RFC 8259, section 1.2.
This was my response:
I haven't read the JSON RFCs, and I've only skimmed 8259 and searched for uses of "JSON text" in it, but it seems to me that 8259 refers to "JSON text" in the same way an XML specification would refer to "XML text": it's not a special term, they just use it to refer to a particular instance of the JSON grammar/syntax, as opposed to a "JSON specification", a "JSON user", and so on. 8259 says:
JSON is also described in [ECMA-404].
The reference to ECMA-404 in the previous sentence is normative, not with the usual meaning that implementors need to consult it in order to understand this document, but to emphasize that there are no inconsistencies in the definition of the term "JSON text" in any of its specifications. Note, however, that ECMA-404 allows several practices that this specification recommends avoiding in the interests of maximal interoperability.
ECMA-404 says (emphasis mine):
1 Scope
JSON is a lightweight, text-based, language-independent syntax for defining data interchange formats. It was derived from the ECMAScript programming language, but is programming language independent. JSON defines a small set of structuring rules for the portable representation of structured data.
The goal of this specification is only to define the syntax of valid JSON texts. Its intent is not to provide any semantics or interpretation of text conforming to that syntax. It also intentionally does not define how a valid JSON text might be internalized into the data structures of a programming language. There are many possible semantics that could be applied to the JSON syntax and many ways that a JSON text can be processed or mapped by a programming language. Meaningful interchange of information using JSON requires agreement among the involved parties on the specific semantics to be applied. Defining specific semantic interpretations of JSON is potentially a topic for other specifications. Similarly, language mappings of JSON can also be independently specified. For example, ECMA-262 defines mappings between valid JSON texts and ECMAScript’s runtime data structures.
2 Conformance A conforming JSON text is a sequence of Unicode code points that strictly conforms to the JSON grammar defined by this specification.
A conforming processor of JSON texts should not accept any inputs that are not conforming JSON texts. A conforming processor may impose semantic restrictions that limit the set of conforming JSON texts that it will process.
It seems clear that "JSON text" is superfluous, and perhaps even wrong, when understood to be referring to a particular instance of JSON, just as it is for "XML text", at least outside of the specification. Terminology that is used in a specification to be unambiguous and precise isn't needed in other contexts. We would know what "encoding/json/text" means.
Unless I missed something, you had no counterargument to that, and your only response was:
It seems that we're metaphorically spilling a lot of ink bike-shedding over the name of the package. I believe efforts should be spent elsewhere.
Because of this and my package name stutter argument above, it seems to me that "jsontext" is the wrong name, and "encoding" or "syntax" or "text" would be better.
Comment From: willfaught
jsontext.SyntacticError.JSONPointer and json.SemanticError.{JSONPointer,JSONKind,JSONValue} seem to stutter.
A SemanticError describes an error bridging two different type systems (i.e., Go and JSON). The Go or JSON prefix in the field name is to be explicit about which type system some error context is stemming from. Given that SemanticError already uses the JSON prefix, we made SyntacticError be consistent in its naming of fields.
@dsnet It seems to me that the types of the fields in SemanticError make it clear which type system they pertain to:
Pointer jsontext.Pointer
Kind jsontext.Kind
Value jsontext.Value
Type reflect.Type
By the way, the type of JSONKind in the proposal is Kind instead of jsontext.Kind.
Comment From: willfaught
I believe it be more productive to condense your thoughts down to the most significant ideas so that we don’t overwhelm the discussion. 20+ thoughts spread throughout 9 distinct posts is challenging for others to follow and engage with even they are worth discussing. We appreciate your thoughts, but not all thoughts are equally fruitful to discuss.
For the sake of this proposal, we should focus on API that cannot be changed once this has been proposed and merged. I recommend choosing a small set of issues that you believe are the most significant and bring the most value. You’re welcome to re-raise a concern already discussed, but let’s aim to keep it a singular issue or two that you believe is most important.
@dsnet It strikes me as improper for you to moderate, shape, or discourage the discussion of your own proposal because you have a conflict of interest. For the proposal process to be perceived as fair, productive, and useful, it should avoid the appearance of impropriety. Frankly, I was so dismayed by your behavior that I walked away from this discussion a couple weeks ago, and I regret participating in it. I don't plan to stay involved past wrapping up this comment.
Some of the points you raised have already been addressed in the prior discussion (https://github.com/golang/go/discussions/63397).
The prior GitHub Discussion wasn't part of the proposal process. That was for you to gather early feedback. This GitHub Issue is for us, the Go Community, to vet the final proposal, and part of that vetting is pointing out issues that were raised before that haven't been properly addressed in some peoples' estimation. Many people here may have never read that GitHub Discussion, so listing those issues here is a service to them, just as listing the changes to the proposal since the Discussion is a service to those who had.
(The rest of this comment was drafted two weeks ago.)
In general, it’s most effective to keep a single comment to a single cohesive thought. GitHub supports emojis, which allows others to signal whether they agree (or disagree) with the idea. Multiple thoughts per comment confuses this reaction mechanism. For example, https://github.com/golang/go/issues/71497#issuecomment-2627773329 on naming of nocase and strictcase was a concise and singular idea, making it possible for people to 👍 the comment signaling support for the suggestion. If someone has already made a similar argument to what you’re about to make, then it’s best to upvote the earlier argument rather than to reiterate the same thing.
For the most part, I split my comments to facilitate voting on the suggestions/ideas, but it looks like there were a couple comments that mistakenly grouped stuff together they shouldn't have. The questions and corrections were batched together because they're not meant to be voted on. (I note that you still haven't answered the questions.) Some things were posted as they came up while I was drafting other comments. The comments weren't all written or submitted at once.
Perhaps I should just put every separate thought in its own comment. That would be simpler, but I hate the thought of the noise.
This particular proposal is paired with a working prototype, so some of the questions could be answered on your own by running some code in a playground.
I'm not sure what you're referring to. Can you be specific? If I could have knowingly run code to answer a question, I would have.
Suggestions about spelling errors or nuances of documentation are better filed at github.com/go-json-experiment/json.
The proposal says that the prototype will be used, presumably as-is. For all I know, issues filed there now will never be addressed. This seems to be the appropriate place to report them now.
Some of the points you raised have already been addressed in the prior discussion (https://github.com/golang/go/discussions/63397). While ideas may have merit, engineering is about tradeoffs and so we sometimes still choose to go down a different path even when presented with valid counter-arguments.
Can you identify which specific points you're referring to, and link to or quote how you addressed them, instead of painting all the points with the same brush? For all we know, you may be mistaken. The community needs to be able to judge for themselves. Unfortunately, your assurances that you've struck the right design and engineering trade-offs aren't convincing in and of themselves.
Comment From: timbray
It's called "jsontext" because it literally handles "JSON text", which is specifically called out as a term in RFC 8259, section 1.2.
This was my response:
I haven't read the JSON RFCs, and I've only skimmed 8259 and searched for uses of "JSON text" in it, but it seems to me
Speaking as the editor of 8259, although most credit has to go to Doug Crockford who wrote the original RFC4627 many years ago… the spec says what it says, not what Doug or I thought we meant, but FWIW I think that “JSON text” refers to the bits on the wire or the bytes on the disk, which earn that name by conforming to the grammar productions in the RFC.
Given that, "jsontext" seems like a perfectly appropriate name for the lowest-level API used for addressing those bytes & bytes.
Comment From: doggedOwl
Many people here may have never read that GitHub Discussion, so listing those issues here is a service to them,
@willfaught the discussion is there for anyone interested to read. There is no need to replicate everything here, either wise there is no need for a discussion before a proposal in the first place. And I agree too that your initial flood of comments many of them just reiterating the same points you or others had raised in the discussion is not helpful. The fact that the answers where not to your satisfaction does not mean that you need to bring them again and again when the discussion in general reached a very satisfactory equilibrium and has been active for almost two years now.
Comment From: burdiyan
I haven’t followed the full conversation leading up to this proposal, so apologies if I’m bringing up something already discussed.
I really like this proposal! But I wonder—could this be an opportunity to introduce a more generalized approach to marshaling/unmarshaling data in Go? Something like Rust’s Serde (not a big Rust fan myself, but having a standard serialization framework is pretty nice).
For example, there could be a generic way to (un)marshal data, similar to what’s outlined here, taking an Encoder + options, but making the Encoder/Decoder more general-purpose, such that various encoding formats (JSON, CBOR, etc.) could implement their own. That way, different formats could share the same reflection machine, walking of the structs, etc.
On top of that, maybe encoders could use a well-known registry interface, so custom encodings for types wouldn’t require modifying those types. That’d make it easier to define custom codecs (e.g., for time.Time) without conflicts across packages. A program could set up its own codec early on and use it consistently for marshaling/unmarshaling.
Comment From: mvdan
@burdiyan this was briefly discussed in https://github.com/golang/go/discussions/63397#discussioncomment-7431314, but it didn't really go anywhere - primarily as it's not clear if such an approach would work in Go, or what it would look like. It seems to me like it would need to be a separate proposal, as it would affect more than just JSON if accepted.
And ideally we don't hold up json/v2 for another year or two while we figure out if such an approach is viable.
Comment From: willfaught
@doggedOwl I'm going to reply because you bring up points I forgot to make in my last comment.
@willfaught the discussion is there for anyone interested to read. There is no need to replicate everything here, either wise there is no need for a discussion before a proposal in the first place.
That isn't compatible with the Go proposal process. Preliminary, informal discussions elsewhere on GitHub, Reddit, Slack, Discord, Twitter, email, etc. don't count, and pose an undue burden on people trying to participate as commenters in the proposal process.
And I agree too that your initial flood of comments many of them just reiterating the same points you or others had raised in the discussion is not helpful. The fact that the answers where not to your satisfaction does not mean that you need to bring them again and again when the discussion in general reached a very satisfactory equilibrium and has been active for almost two years now.
To my recollection, every point I raised here except for one (the name of jsontext) was new. I'd never brought them up before, and neither had others. That's why I asked @dsnet to cite where he addressed them previously: because I didn't know what he was talking about. What he said was (I assume unintentionally) misleading, and many readers won't go back and check the old GitHub discussion for themselves, which is why the first quotation above is a bad idea.
Comment From: josharian
[...] because he can't. He misled you [...]
This is a serious accusation. I have known Joe personally and professionally for many years. He is serious, impeccably honest, and dedicated. (And, I will note, is doing this work as a service to the community, not as his job.)
Please rethink your tone.
Comment From: willfaught
@josharian What I meant was that what he said was misleading. "To mislead" can be done with malicious intent or unintentionally. I suggest you remember that part of the Go code of conduct is to be charitable. I've never questioned his motives. I've thanked @dsnet more than once for his hard work on this project, and I would have thanked him once more in my planned last feedback comment here, but I never got there. I apologize if my phrasing implied malicious intent.
Comment From: ianlancetaylor
This conversation has unfortunately gotten heated. I think everybody needs to step back and focus on any remaining technical details, not on discussions of what was said before and when, not on discussions for how to approach this proposal, not on requests for citations. Thanks.
Comment From: andig
How far does this proposal address cleaning up invalid json tags in the standard library?
One notable example is oauth2.Token with it's time struct marked as
Expiry time.Time `json:"expiry,omitempty"`
Comment From: dsnet
@andig, perhaps that's better addressed by #51261?
For existing usages, it seems these should be fixed by having such cases migrate to omitzero rather than muddle the meaning of omitempty.
Comment From: ianlancetaylor
I just read through the whole API again. Excellent work.
I made the following notes:
- The v1
Tokentype can betokenArrayCommaortokenObjectComma, but those are not supported by the v2Tokentype. These values are not exported but do show up in error messages. - It's not clear from the description, but I assume that
Value.Formatmodifies theValuebyte slice? - I note that
Valuehas some value methods and some pointer methods. I guess this is OK but it's unusual. - Why is
srcinAppendFormat[]byte,notValue? I don't have a clear understanding of theAppendfunctions. I thinkAppendQuoteandAppendUnquoteneed examples. What are they for? - Seems like v2
UnusedBufferis the same asbytes/buffer.AvailableBuffer. Should we use the nameAvailableBuffer? - The
UnusedBufferdocs should say when buffer becomes invalid; onany call toWriteTokenorWritevalue? - For
StackIndexwhat unit is the length? Is it the number of JSON values? - Why is the name
StackPointer? It just refers to the most recent value, not the stack, so why notJSONPointerorCurrentPointeror justPointer? - If
PreserveRawStringsis not set, what happens? Pointer.AppendTokentakes a string, not aToken. Is that the right name? Similarly forPointer.LastToken,Pointer.Tokens.- Doesn't it cost something to reject duplicate names in a JSON object?
- If I specify
nocaseon a field of type struct, does it apply to all the fields of the struct? If not, isn't it easier to specify the expected field name in a tag rather than use nocase? - Should
stringsupport base64, etc., as[]bytedoes? Seems like the same considerations might sometimes arise. - The
time.Timeformat operand says it accepts a Go identifier for a format constant defined in the time package. Does that mean that whenever we add a new format constant we need to add it to encoding/json/v2 as well? Marshalersis cool but seems like it could be split out into a separate proposal. It doesn't seem necessary.NonFatalSemanticErrorsrefers to[SemanticErrors]but later that is calledSemanticError.- Why does the v1 encoding/json package define options that can only be used in conjunction with encoding/json/v2? Why not define them in v2?
EscapeInvalidUTF8needs an example.- The "Number methods" section refers to a
Numbertype, but I don't see any place where that is documented.
Comment From: puellanivis
I don’t have many answers, but:
- I note that
Valuehas some value methods and some pointer methods. I guess this is OK but it's unusual.
It’s not particularly unusual when the underlying type is a slice.
- Doesn't it cost something to reject duplicate names in a JSON object?
This is why it can be disabled, right?
Comment From: huww98
Doesn't it cost something to reject duplicate names in a JSON object?
It has significant overhead for custom UnmarshalerFrom. That's why I propose https://github.com/golang/go/issues/71497#issuecomment-2661251397 . But I think it is OK for built-in struct arshaler, because it use bitset to detect duplicate.
Comment From: treuherz
I have a small naming concern about the proposal (everyone’s favourite!). In British English, “omit” and “emit” are homophones, or at least are close enough in pronunciation that I’d have to ask someone to repeat themselves to figure out if they’d said “omitnull” or “emitnull”. I know this is minor, and these words are likely to be read more than they’re said, but it seems like an avoidable issue.
It would be good to know if this is just a BE problem or if it’s an issue in other dialects as well.
Comment From: DeedleFake
They can be slurred to be similar in the American dialect that I use, but they are often pronounced differently.
Comment From: smlx
It would be good to know if this is just a BE problem or if it’s an issue in other dialects as well.
I'd say omit / emit are just as homophonic in Australian English (my dialect) as BE, and I honestly don't see this being a problem. I don't recall ever reading struct tags out loud to a colleague.
In text the words are concise, accurate, and clear. So unless there is an alternative word which is equally concise, accurate, and clear, I don't see much of a case for changing these based on how they sound.
Comment From: puellanivis
It would be good to know if this is just a BE problem or if it’s an issue in other dialects as well.
I’ve asked a linguistics group I’m in. (These spaces tend to get a lot of polls just like this.) Only 19 responses, but a plurality seem to not reduce at least one of either ⟨omit⟩ or ⟨emit⟩, so they remain quite distinct. But maybe about a quarter of responses said it was a homophone, or was close enough that they would have to exaggerate to make the distinction.
Extrapolating this to anything useful is of course, not in scope, but I think there’s probably enough people for whom they are too close together, that it warrants consideration.
Comment From: treuherz
I'd say
omit/emitare just as homophonic in Australian English (my dialect) as BE, and I honestly don't see this being a problem. I don't recall ever reading struct tags out loud to a colleague.
I'd be more concerned about explaining this to juniors or students than normal conversations with colleagues. Something that's a non-issue for experienced practitioners can be a trip hazard for every new learner of a language or library.
In text the words are concise, accurate, and clear. So unless there is an alternative word which is equally concise, accurate, and clear, I don't see much of a case for changing these based on how they sound.
bikeshedding: If omitnull and omitempty weren't already familiar I'd say they could be skipnull/skipempty. For format:emitnull and format:emitempty I'd propose format:asnull/asempty, or format:nilasnull/nilasempty. These match the full options (e.g. FormatNilSliceAsNull), and nilasempty tells a reader when it would be null, which emitempty doesn't.
Comment From: puellanivis
I'd be more concerned about explaining this to juniors or students than normal conversations with colleagues. Something that's a non-issue for experienced practitioners can be a trip hazard for every new learner of a language or library.
A ubiquitous concern across nearly all domains.
Comment From: AnatolyRugalev
From my experience, Go learners have a lot of trouble understanding how omitempty behaves, and IMO changing omitempty's semantics in v2 will bring even more confusion. I would argue that zero and empty behaviors warrant their own options, as its quite important to get it right in type-safe JSON APIs. Also, I find emit* options out of place inside format.
How about something like this:
zero:omit- skips field rendering if Go value is considered to be zero. Identical toomitzeroin this proposal. Can be set as default behavior usingOmitZeroValuesoption.zero:-(alt:zero:keep) - cancels the effect ofOmitZeroValuesoption (if set)-
zero:empty- nil maps and slices will be rendered as their "empty" representations:{}and[]. Identical toemitemptyin this proposal. When set, empty value is a subject ofempty:*options. -
empty:omit- skips field rendering if the resulting JSON value is "empty". Identical toomitemptyin this proposal. Can be set as default behavior usingOmitEmptyJSONValues empty:-- (alt:empty:keep) cancels the effect ofOmitEmptyJSONValuesmarshaller option (if set)empty:null- replaces "empty" JSON value withnull. Identical toemitnullin this proposal.
With this separation, it's clear that zero applies transformation from Go zero values to JSON, and empty applies transformations when dealing with empty JSON values.
This may create some edge cases for slices and maps which aren't exactly practical:
type A struct {
B []string `json:",zero:empty,empty:omit"` // same effect as `zero:omit`
C []string `json:",zero:empty,empty:null"` // same effect as `zero:-` or just not having `json` tag at all
}
While impractical, this edge case only applies to nil slices and maps. And with sequential interpretation of zero and empty it's quite easy to follow. What's not so easy to follow is the following example based on this proposal:
type A struct {
B []string `json:",omitempty,format:emitnull"`
}
It's not clear to me what would be a result when we combine these two options. If I try to unpack this, format:emitnull should just cancel the effect of FormatNilSliceAsNull if it's set. Then, omitempty treats both null and [] as empty values, so format:emitnull is redundant here, as omitempty will skip both null and [] values.
With my proposed semantics, this will be identical to:
type A struct {
B []string `json:",empty:omit,empty:null"`
}
Which suggests that you are trying to apply the same option with a different value, making it much easier to parse (and remove the redundant option).
And yes, this also resolves omitempty/emitempty confusion, as it becomes: empty:omit and zero:empty
Comment From: danp
Re format for time.Time, I often want RFC3339Nano but only in UTC when marshaling times in JSON, regardless of the time.Times' Location/Zone/etc. Would it be worthwhile to have a way to specify that as part of format or another tag on the field?
Or maybe a Marshaler option to apply to all Times?
Oops! This should be totally doable with MarshalFunc if I understand correctly.
Comment From: kortschak
The issue of omit v emit is not just one of pronunciation. Having completely opposite behaviour specified by words with separated by a Hamming distance of one, and so without a way to otherwise distinguish the intention leaves open a wide path of missing errors where this is important during code review.
Comment From: adrienaury
Thank you @dsnet for the proposal, I think it's great
In the jsontext package, is there a way in the current implementation to customize the types used to create arrays and objects ? I checked both conversations and I didn't find anything, i'm sorry if it already was discussed.
The idea is to somehow subscribe to these events during the decoding : - create object - set value for object key - create array - append value to array
The solution could be done via Options :
func CustomArrays[A](Maker[A], Appender[A]) Options
func CustomObjects[O](Maker[O], Keyer[O]) Options
With these predefined types :
type (
Maker[T any] func() (T, error)
Appender[T any] func(arr T, value any) (T, error)
Keyer[T any] func(obj T, key string, value any) (T, error)
)
The most common use cases would be to keep keys order in object (in a deserialize/reserialize scenario) or to implement interfaces on structural nodes (for example to enable external library capabilities that use specific interfaces)
Comment From: mitar
Would it make sense to have something like MarshalPrepare(out any) *Something which would pre-process the output struct, get out its reflect tags, custom marshal methods, etc., so that any later calls to Decode would then be faster? I am thinking that in many cases (like API calls) I am always having the same output struct type, just different input bytes. So having some way to "precompile" that could improve performance?
Comment From: huww98
@mitar It is already cached in a map. This can only become an issue if we are marshalling very small objects (e.g. just an int), where the reflection and map lookup can take significant time.
Comment From: mitar
Oh, nice. Thanks for explaining.
Comment From: veqryn
If anyone is itching to try using JSON v2 for structured logging, I've created a library that uses it and surfaces all the configuration that that json v2 allows: https://github.com/veqryn/slog-json
Its pretty much a copy of standard library's log/slog package's JSONHandler (with the TextHandler and several abstractions needed for it removed).
We use github.com/veqryn/slog-json in production, and make use of the single-line pretty printed json options in v2 (that I am very happy and proud to have gotten merged into v2 🥳).
Examples: This v2 json is so much easier to read than the default json:
{"time":"2000-01-02T03:04:05Z", "level":"INFO", "msg":"m", "attr":{"nest":1234}}
or
{"time": "2000-01-02T03:04:05Z", "level": "INFO", "msg": "m", "attr": {"nest": 1234}}
Versus the default standard library JSON Handler:
{"time":"2000-01-02T03:04:05Z","level":"INFO","msg":"m","attr":{"nest":"1234"}}
Comment From: seankhliao
I think there should be a way to go from a jsontext.Pointer + jsontext.Value to a jsontext.Value. Currently you're sort of left to your own devices on how to programmatically interpret the value of a jsontext.Pointer.
Perhaps:
package jsontext
func (*Value) Resolve(p Pointer) Value
Comment From: dsnet
Going from a Pointer and Value to a particular sub-Value is something useful to probably one day provide, but there are a few things to figure out and thus I don't think it should block initial v2.
For example, it wasn't clear to me that:
func (*Value) Resolve(p Pointer) Value
is the right signature. In particular, it doesn't tell you where (by offsets) in the original value that the sub-value occurs, so you can't easily mutate the sub-value. For example, you should be able to use this API to replace a particular sub-value.
An alternative signature could be:
func (*Value) Resolve(p Pointer) (begin, end int)
but these feels awkward to use for the more common case of just need read-only access to a particular sub-value.
Alternatively, if we had #66981, then the more natural API would work out, since you could derive the offset with something like:
subvalue := value.Resolve(pointer) // pointer to sensitive data
if len(subvalue) > 0 {
offset := slices.IndexPointer(value, &subvalue[0])
slices.Replace(value, offset, offset+len(subvalue), `"REDACTED"`...)
}
Comment From: gopherbot
Change https://go.dev/cl/665796 mentions this issue: encoding/json: add json/v2 with GOEXPERIMENT=jsonv2 guard
Comment From: stapelberg
I’m not sure if you’re looking for experience reports at this point, but I was eager to try out the newly merged GOEXPERIMENT=jsonv2 and can report that it seems to work correctly in my test application and delivered a nice speed-up:
Loading many tens of thousands of rows from PostgreSQL (encoding parts of it as JSON, which Go then decodes) used to take about 80-100ms, but with encoding/json/v2, it takes consistently only ≈70ms! 🎉
(This isn’t a micro-benchmark, it’s a real-world application. Always nice to see performance wins manifest in the actual program.)
full log of loading times
May 01 10:04:41 bgcache.go:96: [turboload] async-updated cached value in 79.384274ms from bgcache.go:74
May 01 10:06:08 bgcache.go:96: [turboload] async-updated cached value in 85.069964ms from bgcache.go:74
May 01 10:07:35 bgcache.go:96: [turboload] async-updated cached value in 89.891927ms from bgcache.go:74
May 01 10:09:02 bgcache.go:96: [turboload] async-updated cached value in 97.229215ms from bgcache.go:74
May 01 10:10:29 bgcache.go:96: [turboload] async-updated cached value in 89.616166ms from bgcache.go:74
May 01 10:11:56 bgcache.go:96: [turboload] async-updated cached value in 79.538227ms from bgcache.go:74
May 01 10:13:23 bgcache.go:96: [turboload] async-updated cached value in 90.557807ms from bgcache.go:74
May 01 10:14:50 bgcache.go:96: [turboload] async-updated cached value in 79.082058ms from bgcache.go:74
# switch to encoding/json/v2
May 01 10:15:56 bgcache.go:131: [turboload] updated cached value in 73.08324ms from bgcache.go:69
May 01 10:17:23 bgcache.go:96: [turboload] async-updated cached value in 69.712233ms from bgcache.go:74
May 01 10:18:50 bgcache.go:96: [turboload] async-updated cached value in 71.574878ms from bgcache.go:74
May 01 10:20:17 bgcache.go:96: [turboload] async-updated cached value in 70.868179ms from bgcache.go:74
May 01 10:21:44 bgcache.go:96: [turboload] async-updated cached value in 70.367366ms from bgcache.go:74
May 01 10:23:11 bgcache.go:96: [turboload] async-updated cached value in 79.473242ms from bgcache.go:74
May 01 10:24:38 bgcache.go:96: [turboload] async-updated cached value in 69.935425ms from bgcache.go:74
Great work!
Comment From: adam-azarchs
Possibly too late to really do anything about this now, but I do have a problem with the "option pattern" proposed in this API, which otherwise hasn't been seen before in the standard library. That is, using something like
func Format(opts ...Options)
where Options is an interface rather than e.g.
Format(opts *Options)
where Options is a struct.
My main objections to this pattern is twofold: 1. Performance: Interfaces generally entail a vtable lookup and heap allocation. They also have an impact on the compiler's ability to do dead-code elimination. 2. Discoverability: It's easy for a language server to tell you what fields are legal in a struct. It's harder to list all functions which produce a type compatible with an interface.
There are other issues as well. For example what happens if someone passes both EscapeForHTML(true) and EscapeForHTML(false)? Either you define "first one wins", "last one wins" or panic/error. By comparison setting the same field twice in a struct is a compile-time error.
Using a struct avoids these issues while retaining the ability to extend the struct with more options later if need be. This is the pattern used in most standard library packages. The only benefit I've seen people point to is that the variadic nature of the options pattern makes it simple to accept the defaults; I'm not at all convinced that the brevity of that vs. passing nil to indicate a desire to use the defaults is sufficient compensation for the downsides.
Comment From: DeedleFake
There are other issues as well. For example what happens if someone passes both
EscapeForHTML(true)andEscapeForHTML(false)? Either you define "first one wins", "last one wins" or panic/error. By comparison setting the same field twice in a struct is a compile-time error.
This is addressed in the documentation. The options pattern here is conceptually more of a type-safe map assignment. Later options override earlier ones.
Comment From: adam-azarchs
Yes, I understand that it can be documented as such but the fact that one needs to read the documentation in such detail to find that out is less than ideal. It's also something that can result in accidental mistakes, as compared to an API that would provide compile-time safety.
Comment From: puellanivis
The interface used has no methods that can be implemented outside of the json package. This means that it provides perfectly reasonable compile-time safety.
The receiver method defined for Options is never actually called, because it is a no-op function. So, any concern about vtable lookups is irrelevant.
Interfaces do not incur any more heap allocation than the escape analysis would otherwise provide.
Discoverability: It’s actually reasonably easy to enumerate the functions that produce the interface: https://pkg.go.dev/github.com/go-json-experiment/json#pkg-index Since the interface is a non-operational interface, it’s basically building a closed sum type, and thus we don’t want to ever return the concrete types, we want to return only the sum type.
The ability to override an earlier option is part of the ability to provide progressive layers of options with more narrow overrides. Thus, I can provide a generic slice of Options that specifies EscapeForHTML(true), but in an arbitrary one-off case, where I need to not escape for HTML, I can append(opts, EscapeForHTML(false)) knowing that it will override any value set by earlier opts.
I fear that your concerns might be generically about interfaces themselves, rather than considering their specific use case here.
Comment From: dsnet
There are benefits and detriments to options structs, but there are also benefits and detriments of variadic options. The initial prototype of json/v2 was actually a Go struct and we deemed variadic options more ergonomic after using it for some time. There are many layers to this and it was discussed very extensively at https://github.com/golang/go/discussions/63397#discussioncomment-7202160.
Comment From: dsnet
I just filed #74324 for whether SkipFunc should be permitted in MarshalerTo and UnmarshalerFrom methods.
Comment From: udf2457
Just for the record, this v2 effort got a menion on the Trail of Bits blog about the insecurity of the existing json...
https://blog.trailofbits.com/2025/06/17/unexpected-security-footguns-in-gos-parsers/
Comment From: prattmic
For the json:”-,…” case in the blog post, I wonder if we could change the behavior for v2?
I am thinking that rather than json:”-“ ignoring the field and json:”-,…” using a literal dash, we change the latter to ignore the field as well. Basically, if the field name is specified as “-“ then the field is ignored. In the json:”-,…” case, the additional options are simply useless no-ops (maybe make them an error?).
For the rare case that someone really does want a field named “-“, we could do something silly like add a dedicated option: json:”-,literaldash”
Comment From: dsnet
In v2, we support a single-quoted literal to handle special characters (#22518). Thus, we could require that explicitly using a JSON name of - could be specified with something like json:"'-',omitempty" as a workaround.
This allows us to forbid json:"-," or json:"-,omitempty" since there is at least some evidence of this being a footgun.
Comment From: dsnet
Static analysis of open source code known by the module proxy reveals ~2k instances of json:"-,omitempty" that look mostly obviously wrong.
Comment From: Merovius
Another way to solve this is to change how fields are omitted: Use json:",omit" instead of json:"-".
Comment From: dsnet
If we could go back in time, json:",omit" might have been a better choice, but json:"-" already exists and has largely marinated into muscle memory over the many years. The problem being raised by the blog isn't that people forget that "-" is the way to ignore a field, but rather they weren't expecting that combining "-" with other options (e.g., json:"-,omitempty") would cause the field to no longer be ignored.
Comment From: gopherbot
Change https://go.dev/cl/683175 mentions this issue: encoding/json/v2: reject unquoted dash as a JSON field name
Comment From: thepudds
FWIW, there is a related discussion at https://github.com/dominikh/go-tools/issues/1655 about possibly updating staticcheck to catch current instances of these types of mistakes.
Comment From: jameshartig
I'm curious what plans others have to transition from v1 to v2 effectively given that there might be places that are (unknowingly) relying on case-insensitivity across codebases. For example if you previously defined struct { A string } and a frontend repository was sending {"a":"foo"} (which is very possible since things in JS lean lowercase) it's working today in v1 and now it would break in v2. Yes, we could opt into MatchCaseInsensitiveNames forever but that's annoying and it's possible that it would be forgotten in some places versus others, especially as things start to default to v2.
Would there be interest in adding an optional callback or logging when matching case-insensitive names so that they could be cleaned up? Like CaseInsensitiveNamesCallback(func(typeName, fieldName string)) or LogCaseInsensitiveNames(bool).
Comment From: prattmic
One neat approach there (assuming there are failing tests) would be the ability to hook up golang.org/x/tools/cmd/bisect (full writeup at https://research.swtch.com/bisect) to enconding/json/v2, so it could be used to bisect (a) which behavior change breaks the test and (b) which field specifically causes breakage.
Comment From: jameshartig
One neat approach there (assuming there are failing tests) would be the ability to hook up
golang.org/x/tools/cmd/bisect(full writeup at https://research.swtch.com/bisect) toenconding/json/v2, so it could be used to bisect (a) which behavior change breaks the test and (b) which field specifically causes breakage.
I'm not confident that would work for cross-repository or inter-service especially if the field is subtle like {"optoutofemails": true} coming from a web form submission.
Ideally we'd have something we could hook into to know when this insensitive lookup happened and could act on it in some way.
Comment From: prattmic
Yes, I agree, the bisect approach would only work well in an automated testing scenario. Even if you could technically apply bisection to a production service, it would be very slow to deploy steps one at a time.
Comment From: mitar
You could temporary implement your own Unmarshal function which uses both v1 and v2 implementations and compare both output structs if they are the same. If not, you log the error and return v1 result.
Comment From: gopherbot
Change https://go.dev/cl/683555 mentions this issue: cmd/dist: test encoding/json/... with GOEXPERIMENT=jsonv2
Comment From: gopherbot
Change https://go.dev/cl/683896 mentions this issue: encoding/json/jsontext: rename Encoder.UnusedBuffer as Encoder.AvailableBuffer
Comment From: gopherbot
Change https://go.dev/cl/683897 mentions this issue: encoding/json/jsontext: remove Encoder.UnusedBuffer
Comment From: gopherbot
Change https://go.dev/cl/685395 mentions this issue: encoding/json: decompose legacy options
Comment From: kent-h
One thought... Should jsontext.Encoder and jsontext.Decoder be interfaces?
In the case of:
func MarshalEncode(out *jsontext.Encoder, in any, opts ...Options) error
func UnmarshalDecode(in *jsontext.Decoder, out any, opts ...Options) error
Would it be sensible to have the jsontext.Encoder and jsontext.Decoder here be interfaces? Such that jsontext.Encoder/Decoder are simply the default implementation?
This would be useful when working with formats which are built on, but not-quite json. (Formats which wrap json, any simple arrays and maps format, marshaling to unrelated formats, etc.)
It would basically be a way to re-use the wonderful struct introspection logic, while encoding/decoding similar formats. (The current workaround being to have a completely separate step which converts the intermediate json format to something else; incurring an extra decode & encode for every Marshal/Unmarshal.)
I think this would simply require defining Encoder & Decoder interfaces within json/v2, and ensuring that these are passed through in most places instead of *jsontext.Encoder/Decoder.
Thoughts?
Comment From: dsnet
We explored making them interfaces early on, but the performance wasn't great since it meant that every call for every token went through a virtual method call. Also, it also meant that the arguments to the method call escaped, which led to more allocations. This is an unfortunate loss of performance for a relatively less common use case.
That said, we could have the jsontext.Encoder and jsontext.Decoder concrete types be registered with a custom implementation into them. That way the concrete type remains performant, while other implementations becomes possible
Comment From: kent-h
I'm not sure I understand what you mean by:
have the
jsontext.Encoderandjsontext.Decoderconcrete types be registered with a custom implementation into them.
Are you implying that generics could be used?
Comment From: dsnet
Something like:
package jsontext
// NewCustomEncoder creates a new encoder that delegates
// WriteToken and WriteValue calls to the provided encoder e.
func NewCustomEncoder(e interface{
OutputOffset() int64
WriteToken(Token) error
WriteValue(Value) error
}, opts ...Options) *Encoder
I'm not seriously proposing this specific API, but it is do-able. The other methods on Encoder don't need to be implemented by the custom encoder since the concrete Encoder type could track that information itself.
while encoding/decoding similar formats
Fundamentally, I'm assuming that such "similar formats" have the same type system as JSON. If not, I would argue that support for such formats is out of scope.
Comment From: apparentlymart
That idea of making it possible to swap out the lowest-level "write token" and "write value" implementations to potentially support other formats reminds me a lot of the Rust ecosystem's serde.
That library defines its own type system, which seems to make the opposite decision of representing concepts from Rust's own type system and expecting the implementer (of Serializer) to deal with the problem of mapping those Rust-like concepts onto whatever the target serialization format is.
The serde design is considerably more complex than Go's existing encoding patterns and so I'm definitely not meaning to suggest that encoding/json/v2 ought to copy that design. It does seem potentially interesting to be able to use a single set of struct tags and other mapping conventions to target many different serialization formats at once though, and maybe a third-party library could explore that. (Perhaps someone already did!)
The compromise of using JSON's type system as the common data model for many different target formats is interesting, but I wonder how many different formats it could successfully be applied to in practice with that WriteToken/WriteValue-based design. Formats that are intentionally defined as supersets of JSON with an overall similar structure seem workable, at least if the focus was only on encoding and not decoding. YAML seems on the trickier side but maybe okay. TOML might be too far, due to its quite different approach to nesting? 🤷♂
Analyzing what languages could be supported by differently-shaped flavors of this API seems like it could be a big discussion in its own right. Would it be worth starting a separate subissue for that?
Comment From: kent-h
@dsnet this seems reasonable to me.
I spent a bit of time looking though jsontext (trying to figure out what, if any, flexibility is lost), and it does seem like this would add just enough flexibility.
It does seem like a small amount of extra code is required, and incurs a (probably minor) performance penalty? (Due to having an if customEncoder != nil branch for each write).
Any thoughts on the likeliness of this actually happening?
As an aside (perhaps completely separate discussion), I was also thinking about whether generics could help here, by compiling the "standard" implementation with a known Encoder T.
This could: - avoiding virtual method calls. - moving the actual interface higher up the call graph, where it would incur the penalty only once per marshal.
Drawbacks: - Somewhat more complex, sprinkles T's throughout the code. - Incur a secondary compile of the generic code for custom types (which is not a big deal imho.)
This could be done at any level, whether NewCustomEncoder[T CustomEncodeIf](enc T, ... or the full MarshalEncode[T EncoderIf](out T, ...
I'm suggesting this because I've been thinking about it, though at this point it doesn't really seem worthwhile.
@apparentlymart
Analyzing what languages could be supported by differently-shaped flavors of this API seems like it could be a big discussion in its own right. Would it be worth starting a separate subissue for that?
Personally I would prefer to simply make the code flexible, and perhaps mention the capability in the docs, but let the community figure out what formats it ought to apply to.
Though an interesting discussion, I don't think it's something that a lot of time needs to be spent on.
Though this does make me wonder if it would be useful to be able to customize the struct tag; replacing json:"field,omitzero" in favor of myFormat:"field,omitzero".
Comment From: dsnet
Any thoughts on the likeliness of this actually happening?
I doubt that this will happen for the initial release of encoding/jsontext as we're focusing on making sure the current API is what we want to commit to. So long as we're not preventing future API additions, then we can defer such proposals until after the initial release.
I recommend starting a sub-issue for the proposal.
Comment From: puellanivis
It does seem like a small amount of extra code is required, and incurs a (probably minor) performance penalty? (Due to having an
if customEncoder != nilbranch for each write).
Seeing as how branch prediction would help here since it would generally be either long-term true, or long-term false, I’m not sure it would take up all that much performance at all. Heck, if the compiler were able to be sure that it is either always true or always false for a specific binary, dead code elimination could potentially make it a simple alernating-implementation at linker time.
I mean even if we did use interfaces, we could have switch enc := enc.(type) type switches to short-circuit implementations, but eh… that would probably require a lot of code repetition. And while we can have some copying, as a treat; I wouldn’t really wouldn’t want the much more extensive copying that would be involved.
As an aside (perhaps completely separate discussion), I was also thinking about whether generics could help here, by compiling the "standard" implementation with a known Encoder T.
🤔 This would be more likely to produce alternating implementations like I said above, without the compiler needing to know if customEncoder != nil is always true/false.
Drawbacks:
- Somewhat more complex, sprinkles T's throughout the code.
- Incur a secondary compile of the generic code for custom types (which is not a big deal imho.)
For the first drawback here, “simplicity is complex”. The API usage would be simple, its only our code that would be complex. So it’s not an immediately bad choice. (Though, how much it would clutter the documentation is a valid point.)
The second drawback, the secondary compile would only apply for every implementation passed in. So, like you said, not a big deal, because it should really only do these secondary compiles anytime someone wanted to use more than one encoder.
Comment From: dsnet
@mitar's suggestion of "[implementing] your own Unmarshal function which uses both v1 and v2 implementations and compare both output structs if they are the same" is the technique that we've been doing at Tailscale.
I found some time to polish up what we were using and to open source it as github.com/go-json-experiment/jsonsplit.
Comment From: dsnet
Today, the API for GetOption is:
// GetOption returns the value stored in opts with the provided constructor,
// reporting whether the value is present.
func GetOption[T any](opts Options, constructor func(T) Options) (T, bool)
but I suspect most usages will only care about the value itself and not presence. Thus, perhaps we should split it apart as:
// GetOption returns the value stored in opts with the provided constructor.
// If the value is not present, it returns the zero value.
func GetOption[T any](opts Options, constructor func(T) Options) T
// HasOption reports whether a value is present in opts with the provided constructor.
func HasOption[T any](opts Options, constructor func(T) Options) bool
Feel free to discuss further in #74675 and/or use upvote/downvote emoji to signal thoughts.
Comment From: jakebailey
Forgive me if this is mentioned somewhere else, but one thing I'm noticing is that it's awkward to process an io.Reader of whitespace separated JSON values (e.g. one line per object).
I can't use UnmarshalRead becuase that wants to consume the entire stream.
If I use UnmarshalDecode, I have to make a jsontext.Decoder (new), but then UnmarshalDecode doesn't return io.EOF, but rather an "unexpected EOF at ..." error.
I have to do this:
func process(r io.Reader) {
dec := jsontext.NewDecoder(r)
for {
if dec.PeekKind() == 0 {
_, err := decoder.ReadToken() // Try to read a fake token?
if err == io.EOF {
break
}
// handle err
}
var v any
if err := json.UnmarshalDecode(dec, &v); err != nil {
// handle err again?
}
}
}
Which seems like a lot more wordy than:
func process(r io.Reader) {
dec := json.NewDecoder(r)
for {
var v any
if err := dec.Decode(&v); err != nil {
// handle err
}
}
}
Comment From: dsnet
Hi @jakebailey, thank you for raising this. It turns out you discovered a regression from http://golang.org/cl/689919. While fixing a regression bug for v1 (as emulated using v2), we introduce a different one for v2 🤦♂️.
Comment From: nikolaydubina
I just want to highlight that lack of support for format:units in []time.Duration and map[time.Duration] is quite annoying.
Example: we have a lot of YAML configs that utilise time.Duration in slices and maps, now we need to restructure our configs to work around this.
Comment From: OrHayat
i would want to say i kinda think that the ability to add (optionally) predefined prefix to each element in inlined struct is missing that can lower the amount/bugs that this feature will cause but i would understand if that feature wont make it
Comment From: dsnet
@nikolaydubina, I think you getting at two different possible solutions:
1. The format struct tag could be extended to recursively apply to nested-values. We considered this, but grammar was getting pretty gnarly for the micro-language in struct tags. #74819 could help here.
2. Make it possible at the call site to specify that all time.Duration types should use a particular format. For that solution, see #71664. Thus, you could thus do something like: json.Marshal(v, json.WithFormat[time.Duration]("units"))
Comment From: dsnet
@OrHayat, sounds interesting, but also seems like functionality that could added on top of the current API and should thus be a separate proposal.