Bug description
When using metrics as rows in pivot table, sorting is done by row at the most granular level, not by series.
E.g. when sorting by Key A-Z, metrics are displayed correctly under their parent in the series.
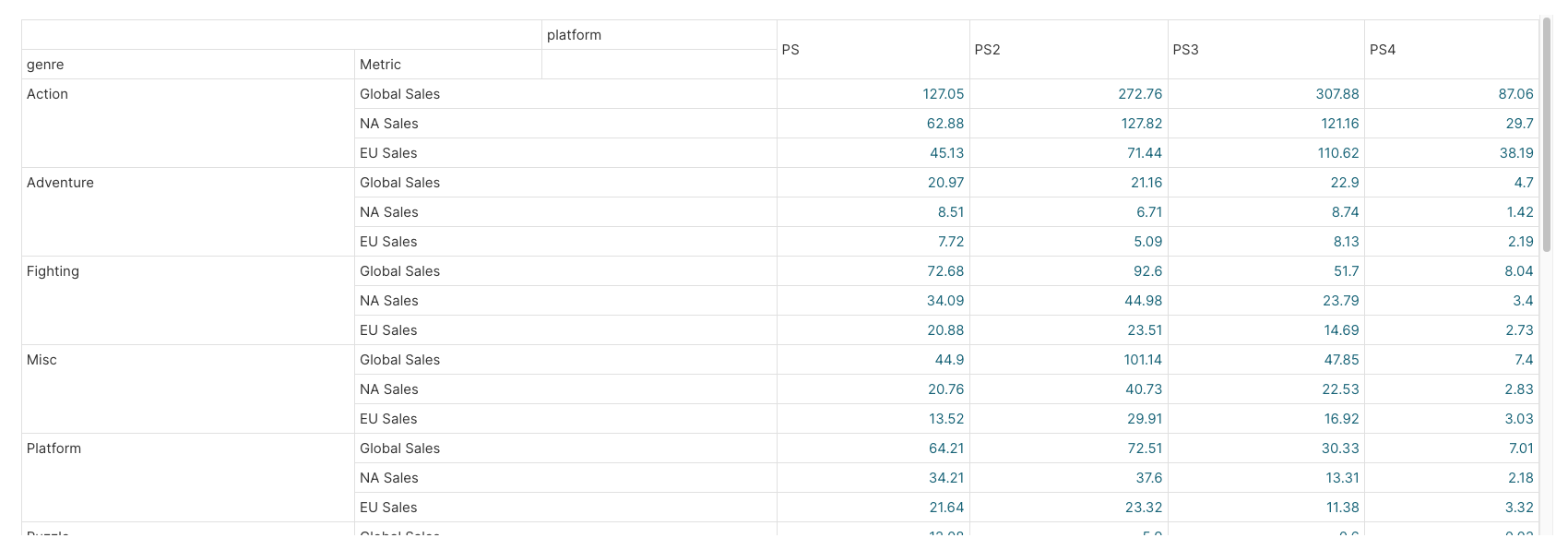
However, when sorting by Value, sorting is done by row, not by series (e.g. "Puzzle" genre is now split into 2 separated groups)
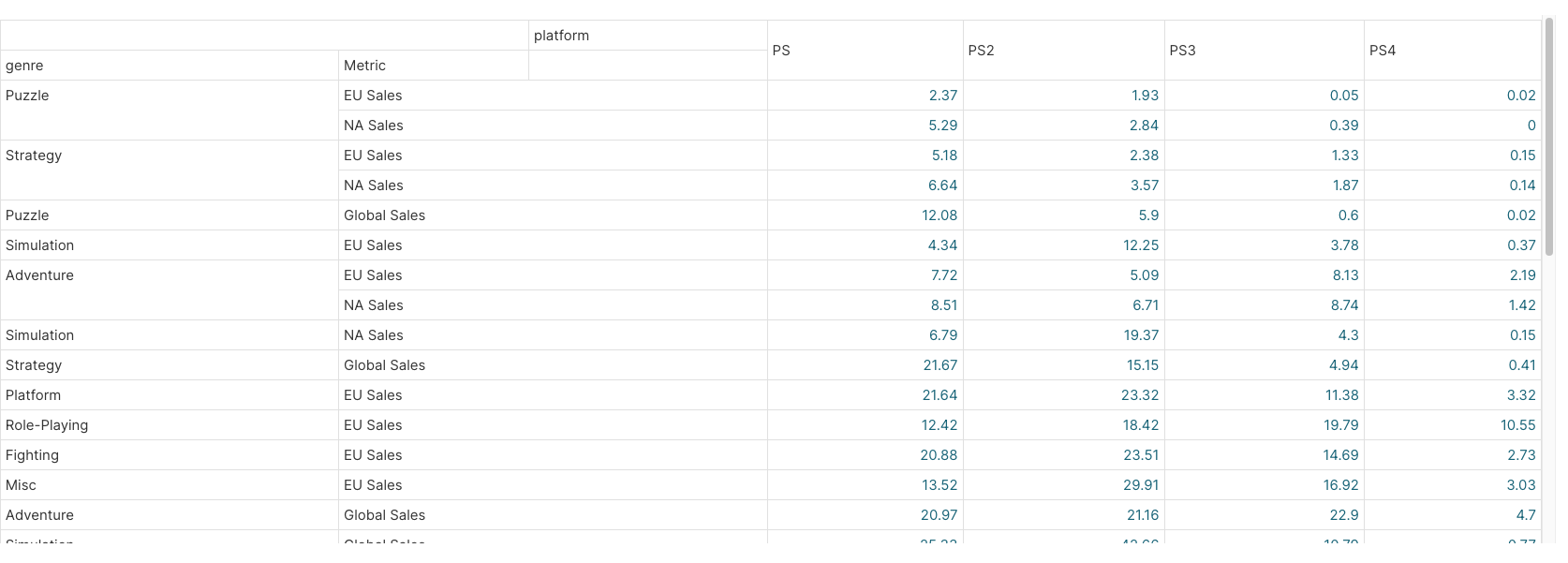
I've spent a lot of time searching for solutions for this, nothing came up. I tried sorting the raw data in the way that I want, but the sorting is overridden by the pivot.
How to reproduce the bug
- Create Pivot Table
- Select >1 metric
- Select metrics as rows
- Go to "Customize" and choose sort by values
Screenshots/recordings
No response
Superset version
master / latest-dev
Python version
3.9
Node version
16
Browser
Chrome
Additional context
No response
Checklist
- [X] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [X] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [X] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: ljluestc
import pandas as pd
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import create_engine
# Initialize Flask app
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///pivot_data.db' # Use SQLite for simplicity
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
# Define a model for the pivot table data
class PivotData(db.Model):
__tablename__ = 'pivot_data'
id = db.Column(db.Integer, primary_key=True)
series = db.Column(db.String(50)) # e.g., "Puzzle"
metric = db.Column(db.String(50)) # e.g., "Sales", "Profit"
value = db.Column(db.Float) # Numeric value
# Simulate your data (replace with your actual data source)
def create_sample_data():
data = {
'series': ['Puzzle', 'Puzzle', 'Action', 'Action'],
'metric': ['Sales', 'Profit', 'Sales', 'Profit'],
'value': [100, 20, 150, 30]
}
df = pd.DataFrame(data)
# Sort by series first, then value descending within series
df = df.sort_values(by=['series', 'value'], ascending=[True, False])
return df
# Populate the database
def init_db():
db.drop_all()
db.create_all()
df = create_sample_data()
for _, row in df.iterrows():
entry = PivotData(series=row['series'], metric=row['metric'], value=row['value'])
db.session.add(entry)
db.session.commit()
# Flask route to serve data (for debugging)
@app.route('/data', methods=['GET'])
def get_data():
data = PivotData.query.all()
result = [{'series': d.series, 'metric': d.metric, 'value': d.value} for d in data]
return jsonify(result)
if __name__ == '__main__':
with app.app_context():
init_db() # Initialize database with sorted data
app.run(debug=True, host='0.0.0.0', port=5000)
Comment From: rusackas
Can we get some context regarding the above code chunk? Is there a PR that ought to be opened here?
Comment From: rusackas
This might be closed as inactive, if we can't find a path forward or get any responses.