Hi, several months ago I submit a patch to implement LICM(https://github.com/golang/go/pull/59194), but in that patch the performance improvement was not compelling, after some research we think we need to hoist the high-yield instructions (Load/Store/etc) to achieve a positive performance improvement. Since these high-yield instructions are usually not speculative execution, we may need to implement a fulll LICM with the following dependencies:
- LICM: hoist load/store/nilcheck etc
- Loop Rotation: Transform while loop to do-while loop, it creates a home for hoistable Values
- LCSSA: Loop closed SSA form, it ensures that all values defined inside the loop are only used within loop. This significantly simplifies the implementation of Loop Rotation and is the basis for future loop optimization such as loop unswitching and loop vectorization.
- Def-Use Utilities
- Type-based Alias Analysis: It ensures load/store are not pointing to the same location, thus we can safely hoist Load/Store/etc.
Overall, LCSSA opens the door to future loop optimizations, and LICM is expected to have attractive performance improvements on some benchmarks.
| package | arch | baseline | opt | delta |
|---|---|---|---|---|
| unicode/utf16 | amd64 | 12.83n | 10.59n | -17.45% |
| math/bits | yitian | 0.8228n | 0.7231n | -12.11% |
| regexp/syntax | amd64 | 175.3n | 157.5n | -10.17% |
| unicode/utf16 | yitian | 8.191n | 7.582n | -7.43% |
| math/rand | amd64 | 54.91n | 50.90n | -7.31% |
| expvar | yitian | 162.7n | 154.0n | -5.36% |
| runtime/internal/atomic | yitian | 6.194n | 5.889n | -4.92% |
| mime | amd64 | 48.96n | 46.73n | -4.57% |
| encoding/binary | amd64 | 28.94n | 27.83n | -3.84% |
| runtime/cgo | yitian | 801.9n | 771.6n | -3.79% |
| encoding/binary | yitian | 23.65n | 22.76n | -3.75% |
| sync/atomic | yitian | 4.748n | 4.577n | -3.61% |
| archive/zip | amd64 | 326.9_ | 316.0_ | -3.33% |
| time | yitian | 489.9n | 474.3n | -3.18% |
| image | amd64 | 8.690n | 8.427n | -3.03% |
| fmt | yitian | 79.12n | 76.77n | -2.97% |
| encoding/csv | amd64 | 2.189_ | 2.132_ | -2.62% |
| net/rpc | amd64 | 10.62_ | 10.35_ | -2.61% |
| encoding/base64 | amd64 | 373.4n | 363.8n | -2.56% |
| time | amd64 | 745.2n | 726.3n | -2.54% |
| text/template/parse | yitian | 17.42µ | 17.00µ | -2.41% |
| bufio | amd64 | 319.2n | 311.5n | -2.40% |
| encoding/gob | amd64 | 7.626_ | 7.445_ | -2.37% |
| encoding/base32 | yitian | 17.63µ | 17.22µ | -2.36% |
| crypto/rc4 | amd64 | 1.967_ | 1.921_ | -2.30% |
| math/bits | amd64 | 1.377n | 1.346n | -2.28% |
| encoding/xml | amd64 | 3.507_ | 3.430_ | -2.18% |
| fmt | amd64 | 167.0n | 163.5n | -2.14% |
| log/slog/internal/benchmarks | amd64 | 178.6n | 174.7n | -2.14% |
| crypto/x509 | amd64 | 121.9_ | 119.3_ | -2.12% |
| log/slog/internal/benchmarks | yitian | 76.34n | 74.75n | -2.08% |
| encoding/gob | yitian | 3.439µ | 3.368µ | -2.07% |
| internal/poll | amd64 | 140.6n | 137.7n | -2.04% |
| image/jpeg | yitian | 252.0µ | 247.4µ | -1.82% |
| compress/lzw | yitian | 946.3µ | 929.7µ | -1.75% |
| text/template/parse | amd64 | 21.72_ | 21.34_ | -1.72% |
| slices | amd64 | 144.1n | 141.7n | -1.67% |
| compress/lzw | amd64 | 1.446m | 1.422m | -1.66% |
| crypto/x509 | yitian | 98.15µ | 96.54µ | -1.64% |
| io | amd64 | 7.584_ | 7.461_ | -1.62% |
| crypto/des | amd64 | 236.3n | 232.5n | -1.60% |
| log/slog | amd64 | 452.1n | 445.0n | -1.59% |
| crypto/elliptic | amd64 | 57.17_ | 56.33_ | -1.48% |
| crypto/internal/nistec | yitian | 131.1µ | 129.1µ | -1.48% |
| net/rpc | yitian | 8.009µ | 7.896µ | -1.42% |
| crypto/internal/nistec/fiat | amd64 | 89.35n | 88.15n | -1.34% |
| crypto/internal/nistec/fiat | yitian | 51.92n | 51.25n | -1.30% |
| slices | yitian | 99.47n | 98.17n | -1.30% |
| encoding/asn1 | yitian | 2.581µ | 2.549µ | -1.24% |
| crypto/internal/nistec | amd64 | 208.6_ | 206.2_ | -1.15% |
| sort | yitian | 528.5µ | 522.7µ | -1.08% |
| reflect | amd64 | 36.59n | 36.20n | -1.06% |
| compress/flate | amd64 | 1.597m | 1.582m | -0.92% |
| internal/fuzz | amd64 | 9.127_ | 9.043_ | -0.92% |
| image/gif | yitian | 4.505m | 4.464m | -0.92% |
| reflect | yitian | 23.30n | 23.09n | -0.90% |
| debug/elf | yitian | 5.180µ | 5.134µ | -0.88% |
| debug/gosym | yitian | 4.722µ | 4.683µ | -0.83% |
| regexp | amd64 | 10.57_ | 10.48_ | -0.81% |
| crypto/elliptic | yitian | 37.49µ | 37.18µ | -0.81% |
| encoding/json | amd64 | 3.434_ | 3.407_ | -0.80% |
| image | yitian | 6.054n | 6.005n | -0.80% |
| encoding/pem | amd64 | 170.6_ | 169.4_ | -0.71% |
| runtime/cgo | amd64 | 845.7n | 839.9n | -0.69% |
| debug/elf | amd64 | 5.933_ | 5.894_ | -0.67% |
| crypto/internal/bigmod | yitian | 8.593µ | 8.538µ | -0.64% |
| hash/crc32 | amd64 | 287.9n | 286.1n | -0.63% |
| go/constant | amd64 | 40.93_ | 40.67_ | -0.62% |
| image/png | amd64 | 1.220m | 1.212m | -0.60% |
| math/big | amd64 | 3.557_ | 3.536_ | -0.59% |
| crypto/aes | amd64 | 27.64n | 27.48n | -0.58% |
| net/netip | yitian | 44.12n | 43.87n | -0.57% |
| math/big | yitian | 2.412µ | 2.399µ | -0.51% |
| math/cmplx | amd64 | 39.62n | 39.43n | -0.46% |
| crypto/subtle | yitian | 8.622n | 8.583n | -0.46% |
| math | yitian | 5.104n | 5.083n | -0.41% |
| sort | amd64 | 825.4_ | 822.0_ | -0.40% |
| bytes | amd64 | 1.733_ | 1.727_ | -0.37% |
| image/color | yitian | 3.669n | 3.655n | -0.36% |
| image/gif | amd64 | 4.927m | 4.910m | -0.35% |
| html/template | yitian | 494.9n | 493.3n | -0.32% |
| hash/crc64 | yitian | 10.65µ | 10.63µ | -0.27% |
| internal/poll | yitian | 62.14n | 61.99n | -0.25% |
| crypto/internal/edwards25519 | yitian | 28.41µ | 28.34µ | -0.24% |
| mime/multipart | yitian | 35.87µ | 35.79µ | -0.22% |
| crypto/md5 | amd64 | 4.305_ | 4.298_ | -0.17% |
| crypto/sha1 | amd64 | 1.381_ | 1.378_ | -0.17% |
| crypto/cipher | amd64 | 1.182_ | 1.180_ | -0.16% |
| crypto/ecdh | amd64 | 483.4_ | 482.7_ | -0.14% |
| unicode/utf8 | yitian | 55.44n | 55.38n | -0.12% |
| html/template | amd64 | 664.7n | 664.0n | -0.10% |
| bytes | yitian | 1.154µ | 1.153µ | -0.09% |
| crypto/internal/bigmod | amd64 | 9.538_ | 9.532_ | -0.07% |
| compress/bzip2 | yitian | 5.270m | 5.266m | -0.07% |
| crypto/rc4 | yitian | 1.501µ | 1.500µ | -0.06% |
| archive/tar | yitian | 3.656µ | 3.654µ | -0.05% |
| crypto/ecdsa | yitian | 187.3µ | 187.2µ | -0.05% |
| crypto/sha1 | yitian | 483.7n | 483.7n | -0.01% |
| crypto/internal/edwards25519/field | yitian | 34.96n | 34.97n | 0.02% |
| hash/fnv | amd64 | 2.075_ | 2.075_ | 0.03% |
| crypto/md5 | yitian | 3.746µ | 3.747µ | 0.03% |
| crypto/cipher | yitian | 816.4n | 816.9n | 0.06% |
| crypto/hmac | amd64 | 1.677_ | 1.678_ | 0.08% |
| crypto/ed25519 | amd64 | 42.51_ | 42.55_ | 0.09% |
| encoding/asn1 | amd64 | 3.390_ | 3.394_ | 0.10% |
| crypto/sha256 | amd64 | 3.200_ | 3.204_ | 0.11% |
| crypto/ecdh | yitian | 307.9µ | 308.2µ | 0.11% |
| crypto/sha512 | yitian | 1.036µ | 1.037µ | 0.11% |
| hash/crc32 | yitian | 166.1n | 166.3n | 0.11% |
| image/png | yitian | 787.7µ | 788.5µ | 0.11% |
| crypto/hmac | yitian | 473.6n | 474.1n | 0.12% |
| sync | amd64 | 85.76n | 85.89n | 0.15% |
| image/jpeg | amd64 | 417.5_ | 418.2_ | 0.17% |
| archive/zip | yitian | 205.1µ | 205.5µ | 0.20% |
| go/printer | amd64 | 232.9_ | 233.5_ | 0.23% |
| strconv | yitian | 42.90n | 43.00n | 0.23% |
| log/slog | yitian | 335.1n | 335.9n | 0.24% |
| image/color | amd64 | 5.199n | 5.213n | 0.26% |
| crypto/ed25519 | yitian | 32.43µ | 32.51µ | 0.27% |
| crypto/internal/edwards25519/field | amd64 | 44.30n | 44.42n | 0.28% |
| crypto/internal/edwards25519 | amd64 | 36.84_ | 36.95_ | 0.30% |
| compress/flate | yitian | 990.4µ | 993.5µ | 0.32% |
| debug/gosym | amd64 | 5.990_ | 6.011_ | 0.36% |
| strings | yitian | 816.3n | 819.3n | 0.36% |
| go/constant | yitian | 39.23µ | 39.37µ | 0.37% |
| math/rand/v2 | yitian | 5.932n | 5.954n | 0.37% |
| crypto/rsa | yitian | 734.8µ | 738.4µ | 0.49% |
| crypto/ecdsa | amd64 | 312.1_ | 313.7_ | 0.51% |
| log | amd64 | 175.0n | 175.9n | 0.53% |
| regexp | yitian | 7.101µ | 7.138µ | 0.53% |
| crypto/sha256 | yitian | 581.6n | 585.0n | 0.58% |
| encoding/csv | yitian | 1.870µ | 1.881µ | 0.62% |
| crypto/sha512 | amd64 | 2.774_ | 2.792_ | 0.65% |
| runtime | yitian | 34.38n | 34.61n | 0.65% |
| sync | yitian | 56.61n | 56.98n | 0.65% |
| image/draw | amd64 | 626.6_ | 631.0_ | 0.69% |
| runtime/trace | amd64 | 4.299n | 4.329n | 0.69% |
| strings | amd64 | 1.152_ | 1.160_ | 0.70% |
| internal/fuzz | yitian | 6.616µ | 6.663µ | 0.71% |
| crypto/subtle | amd64 | 12.80n | 12.90n | 0.74% |
| crypto/aes | yitian | 17.14n | 17.27n | 0.76% |
| text/tabwriter | amd64 | 388.0_ | 391.0_ | 0.77% |
| go/parser | amd64 | 1.634m | 1.647m | 0.80% |
| net/textproto | yitian | 1.647µ | 1.661µ | 0.80% |
| crypto/des | yitian | 162.4n | 163.7n | 0.81% |
| internal/intern | yitian | 128.0n | 129.1n | 0.85% |
| encoding/hex | amd64 | 5.941_ | 5.993_ | 0.86% |
| compress/bzip2 | amd64 | 8.345m | 8.419m | 0.89% |
| go/parser | yitian | 1.233m | 1.244m | 0.89% |
| encoding/base64 | yitian | 240.5n | 242.8n | 0.92% |
| log | yitian | 180.6n | 182.4n | 0.96% |
| encoding/hex | yitian | 4.120µ | 4.161µ | 0.97% |
| encoding/base32 | amd64 | 27.58_ | 27.85_ | 0.98% |
| net/http | yitian | 3.268µ | 3.301µ | 1.03% |
| encoding/json | yitian | 1.572µ | 1.589µ | 1.06% |
| math/cmplx | yitian | 26.43n | 26.74n | 1.17% |
| mime | yitian | 24.37n | 24.65n | 1.17% |
| strconv | amd64 | 67.41n | 68.25n | 1.24% |
| runtime | amd64 | 51.06n | 51.71n | 1.26% |
| runtime/trace | yitian | 2.411n | 2.443n | 1.31% |
| math/rand | yitian | 40.09n | 40.64n | 1.38% |
| html | yitian | 2.562µ | 2.599µ | 1.46% |
| bufio | yitian | 267.9n | 272.0n | 1.50% |
| expvar | amd64 | 264.3n | 268.5n | 1.60% |
| net/netip | amd64 | 64.72n | 65.76n | 1.62% |
| os | yitian | 1.387µ | 1.414µ | 1.94% |
| encoding/xml | yitian | 3.475µ | 3.544µ | 2.00% |
| go/types | yitian | 497.5µ | 507.8µ | 2.07% |
| io | yitian | 1.994µ | 2.036µ | 2.12% |
| regexp/syntax | yitian | 106.3n | 108.6n | 2.14% |
| math/rand/v2 | amd64 | 8.660n | 8.854n | 2.24% |
| context | yitian | 953.0n | 975.0n | 2.31% |
| encoding/pem | yitian | 106.5µ | 108.9µ | 2.31% |
| mime/multipart | amd64 | 42.46_ | 43.55_ | 2.57% |
| database/sql | amd64 | 853.1_ | 875.5_ | 2.62% |
| go/scanner | amd64 | 241.1_ | 247.4_ | 2.62% |
| hash/maphash | yitian | 28.44n | 29.21n | 2.71% |
| runtime/internal/math | yitian | 0.9047n | 0.9295n | 2.74% |
| go/scanner | yitian | 164.8µ | 169.6µ | 2.94% |
| errors | yitian | 132.0n | 136.1n | 3.16% |
| image/draw | yitian | 370.5µ | 382.8µ | 3.30% |
| unicode/utf8 | amd64 | 76.28n | 78.91n | 3.45% |
| text/tabwriter | yitian | 284.5µ | 294.3µ | 3.45% |
| runtime/internal/atomic | amd64 | 13.41n | 13.95n | 4.01% |
| html | amd64 | 2.673_ | 2.783_ | 4.12% |
| errors | amd64 | 166.2n | 173.3n | 4.25% |
| net/url | yitian | 254.0n | 264.9n | 4.29% |
| go/printer | yitian | 159.7µ | 166.6µ | 4.36% |
| hash/crc64 | amd64 | 12.87_ | 13.43_ | 4.38% |
| math | amd64 | 9.082n | 9.480n | 4.39% |
| archive/tar | amd64 | 4.891_ | 5.107_ | 4.42% |
| index/suffixarray | yitian | 46.87m | 49.02m | 4.60% |
| go/types | amd64 | 685.3_ | 718.3_ | 4.81% |
| net/textproto | amd64 | 2.142_ | 2.246_ | 4.87% |
| hash/fnv | yitian | 1.453µ | 1.526µ | 5.00% |
| sync/atomic | amd64 | 8.594n | 9.055n | 5.37% |
| database/sql | yitian | 698.3µ | 735.9µ | 5.38% |
| runtime/internal/math | amd64 | 1.390n | 1.465n | 5.40% |
| crypto/rsa | amd64 | 970.1_ | 1.025m | 5.67% |
| net/url | amd64 | 385.5n | 412.0n | 6.86% |
| internal/intern | amd64 | 135.3n | 145.1n | 7.24% |
| os | amd64 | 1.671_ | 1.799_ | 7.67% |
| hash/maphash | amd64 | 45.60n | 49.25n | 8.02% |
| index/suffixarray | amd64 | 79.15m | 85.55m | 8.08% |
| net/http | amd64 | 4.357_ | 4.712_ | 8.16% |
| context | amd64 | 1.236_ | 1.350_ | 9.18% |
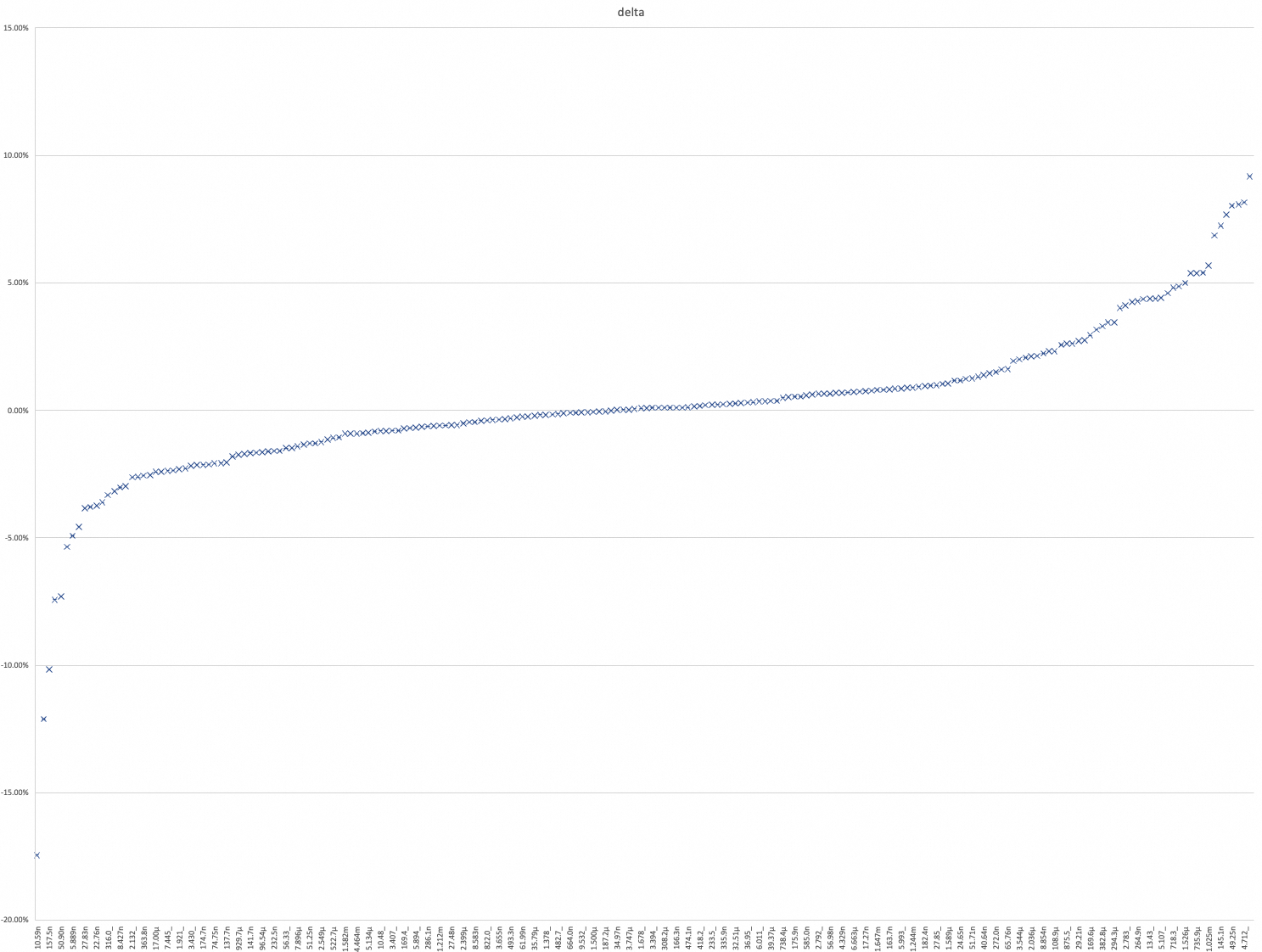
Because loop rotation significantly changes the control flow, it also affects block layout and register allocation, leading to regressions in some benchmarks. I have fixed some of these, but completely eliminating these regressions remains a long-term task. To prevent the patch from growing larger and mixing code changes that increase the difficulty of review, such as the fix to the register allocation algorithm and adjust to the block layouting algorithm, and to keep features independent, I have introduced GOEXPERIMENT=loopopts to control these optimizations, with the expectation of gradually fixing all the regressions and reducing compilation time in the follow-up patches.
Below is a more detailed explanation of the changes, which may be helpful to the reviewer. Thank you for your patience!
1. Loop Invariant Code Motion
The main idea behind LICM is to move loop invariant values outside of the loop so that they are only executed once, instead of being repeatedly executed with each iteration of the loop. In the context of LICM, if a loop invariant can be speculatively executed, then it can be freely hoisted to the loop entry. However, if it cannot be speculatively executed, there is still a chance that it can be hoisted outside the loop under a few prerequisites:
#1 Instruction is guaranteed to execute unconditionally#2 Instruction does not access memory locations that may alias with other memory operations inside the loop
For #1, this is guaranteed by loop rotation, where the loop is guaranteed to
execute at least once after rotation. But that's not the whole story. If the
instruction is guarded by a conditional expression (e.g., loading from a memory
address usually guarded by an IsInBound check), in this case, we try to hoist
it only if the loop invariant dominates all loop exits, which implies that it
will be executed unconditionally as soon as it enters the loop.
For #2, we rely on a simple but efficient type-based alias analysis to know
whether two memory access instructions may access the same memory location.
2. Type-based Alias Analysis
Type-based Alias Analysis(TBAA) is described in Amer Diwan, Kathryn S. McKinley, J. Eliot B. Moss: Type-Based Alias Analysis. PLDI 1998 TBAA relies on the fact that Golang is a type-safe language, i.e. different pointer types cannot be converted to each other in Golang. Under assumption, TBAA attempts to identify whether two pointers may point to same memory based on their type and value semantics. They can be summarized as follows rules:
#0 unsafe pointer may aliases with anything even if their types are different
#1 a must aliases with b if a==b
#2 a.f aliases with b.g if f==g and a aliases with b
#3 a.f aliases with *b if they have same types
#4 a[i] aliases with *b if they have same types
#5 a.f never aliases with b[i]
#6 a[i] aliases with b[j] if a==b
#7 a aliases with b if they have same types
3. Loop Close SSA Form
Loop closed SSA form(LCSSA) is a special form of SSA form, which is used to simplify loop optimization. It ensures that all values defined inside the loop are only used within loop. The transformation looks up loop uses outside the loop and inserts the appropriate "proxy phi" at the loop exit, after which the outside of the loop does not use the loop def directly but the proxy phi.
loop header: loop header:
v3 = Phi(0, v4) v3 = Phi(0, v4)
If cond->loop latch,loop exit If cond->loop latch,loop exit
loop latch: loop latch:
v4 = Add(v3, 1) => v4 = Add(v3, 1)
Plain->loop header Plain->loop header
loop exit: loop exit:
v5 = Add(5, v3) v6 = Phi(v3) <= Proxy Phi
Ret v18 v5 = Add(5, v6)
Ret v18
Previously, v5 used v3 directly, where v5 is in the loop exit which is outside the loop. After LCSSA transformation, v5 uses v6, which in turn uses v3. Here, v6 is the proxy phi. In the context of LCSSA, we can consider the use block of v6 to be the loop header rather than the loop exit. This way, all values defined in the loop are loop "closed", i.e. only used within the loop.
Any further changes to the loop definition only need to update the proxy phi, rather than iterating through all its uses and handling properties such as This significantly simplifies implementation of Loop Rotation
4. Loop Rotation
4.1 CFG transformation
Loop rotation, also known as loop inversion, it transforms while/for loop to do-while style loop, e.g.
// Before
for i := 0; i < cnt; i++ {
...
}
// After
if 0 < cnt {
i := 0
do {
...
} while(i < cnt)
}
The original natural loop is in form of below IR
entry
│
│ ┌───loop latch
▼ ▼ ▲
loop header │
│ │ │
│ └──►loop body
▼
loop exit
In the terminology, loop entry dominates the entire loop, loop header contains the loop conditional test, loop body refers to the code that is repeated, loop latch contains the backedge to loop header, for simple loops, the loop body is equal to loop latch, and loop exit refers to the block that dominated by the entire loop.
We move the conditional test from loop header to loop latch, incoming backedge argument of conditional test should be updated as well otherwise we would lose one update. Also note that any other uses of moved values should be updated because moved Values now live in loop latch and may no longer dominates their uses. At this point, loop latch determines whether loop continues or exits based on rotated test.
entry
│
│
▼
loop header◄──┐
│ │
│ │
▼ │
loop body │
│ │
│ │
▼ │
loop latch────┘
│
│
▼
loop exit
Now loop header and loop body are executed unconditionally, this may changes program semantics while original program executes them only if test is okay. A so-called loop guard is inserted to ensure loop is executed at least once.
entry
│
│
▼
┌──loop guard
│ │
│ │
│ ▼
│ loop header◄──┐
│ │ │
│ │ │
│ ▼ │
│ loop body │
│ │ │
│ │ │
│ ▼ │
│ loop latch────┘
│ │
│ │
│ ▼
└─►loop exit
Loop header no longer dominates entire loop, loop guard dominates it instead. If Values defined in the loop were used outside loop, all these uses should be replaced by a new Phi node at loop exit which merges control flow from loop header and loop guard. Based on Loop Closed SSA Form, these Phis have already been created. All we need to do is simply reset their operands to accurately reflect the fact that loop exit is a merge point now.
One of the main purposes of Loop Rotation is to assist other optimizations such as LICM. They may require that the rotated loop has a proper while safe block to place new Values, an optional loop land block is hereby created to give these optimizations a chance to keep them from being homeless.
entry
│
│
▼
┌──loop guard
│ │
│ │
│ ▼
| loop land <= safe land to place Values
│ │
│ │
│ ▼
│ loop header◄──┐
│ │ │
│ │ │
│ ▼ │
│ loop body │
│ │ │
│ │ │
│ ▼ │
│ loop latch────┘
│ │
│ │
│ ▼
└─► loop exit
The detailed loop rotation algorithm is summarized as following steps
- Transform the loop to Loop Closed SSA Form 1.1 All uses of loop defined Values will be replaced by uses of proxy phis
- Check whether loop can apply loop rotate 2.1 Loop must be a natural loop and have a single exit and so on..
- Rotate loop conditional test and rewire loop edges 3.1. Rewire loop header to loop body unconditionally. 3.2 Rewire loop latch to header and exit based on new conditional test. 3.3 Create new loop guard block and rewire loop entry to loop guard. 3.4 Clone conditional test from loop header to loop guard. 3.5 Rewire loop guard to original loop header and loop exit
- Reconcile broken data dependency after CFG transformation 4.1 Move conditional test from loop header to loop latch 4.2 Update uses of moved Values because these defs no longer dominates uses after they were moved to loop latch 4.3 Add corresponding argument for phis at loop exits since new edge from loop guard to loop exit had been created 4.4 Update proxy phi to use the loop phi's incoming argument which comes from loop latch since loop latch may terminate the loop now
Some gory details in data dependencies after CFG transformation that deviate from intuition need to be taken into account. This has led to a more complex loop rotation implementation, making it less intuitive.
4.2 Fix Data Dependencies
The most challenging part of Loop Rotation is the update of data dependencies (refer to steps 3 and 4 of the algorithm).
Update conditional test operands
In original while/for loop, a critical edge is inserted at the end of each iteration, Phi values are updated. All subsequent uses of Phi rely on updated values. However, when converted to a do-while loop, Phi nodes may be used at the end of each iteration before they are updated. Therefore, we need to replace all subsequent uses of Phi with use of Phi parameter. This way, it is equivalent to using updated values of Phi values. Here is a simple example:
Normal case, if v2 uses v1 phi, and the backedge operand v4 of v1 phi is located in the loop latch block, we only need to modify the usage of v1 by v2 to the usage of v4. This prevents loss of updates, and the dominance relationship will not be broken even after v2 is moved to the loop latch.
Before:
loop header:
v1 = phi(0, v4)
v2 = v1 + 1
If v2 < 3 -> loop body, loop exit
loop latch:
v4 = const 512
After:
loop header:
v1 = phi(0, v4)
loop latch:
v4 = const 512
v2 = v4 + 1
If v2 < 3 -> loop header, loop exit
After updating uses of val, we may create yet another cyclic dependency, i.e.
loop header:
v1 = phi(0, v4)
v2 = v1 + 1
If v2 < 3 -> loop body, loop exit
loop latch:
v4 = v2 + 1
After updating iarg of val to newUse, it becomes
loop header:
v1 = phi(0, v4)
loop latch:
v2 = v4 + 1 ;;; cyclic dependency
v4 = v2 + 1
If v2 < 3 -> loop header, loop exit
This is similiar to below case, and it would be properly handled by updateMovedUses. For now, we just skip it to avoid infinite recursion.
If there is a value v1 in the loop header that is used to define a v2 phi in the same basic block, and this v2 phi is used in turn to use the value v1, there is a cyclic dependencies, i.e.
loop header:
v1 = phi(0, v2)
v2 = v1 + 1
If v2 < 3 -> loop body, loop exit
In this case, we need to first convert the v1 phi into its normal form, where its back edge parameter uses the value defined in the loop latch.
loop header:
v1 = phi(0, v3)
v2 = v1 + 1
If v2 < 3 -> loop body, loop exit
loop latch:
v3 = Copy v2
After this, the strange v1 phi is treated in the same way as other phis. After moving the conditional test to the loop latch, the relevant parameters will also be updated, i.e., v2 will use v3 instead of v1 phi:
loop header:
v1 = phi(0, v3)
loop latch:
v3 = Copy v2
v2 = v3 + 1
If v2 < 3 -> loop header, loop exit
Finally, since v3 is use of v2, after moving v2 to the loop latch, updateMovedUses will update these uses and insert a new v4 Phi.
loop header:
v1 = phi(0, v3)
v4 = phi(v2', v2) ;;; v2' lives in loop guard
loop latch:
v3 = Copy v4
v2 = v3 + 1
If v2 < 3 -> loop header, loop exit
Update uses of moved Values because these defs no longer dominates uses after they were moved to loop latch
If the loop conditional test is "trivial", we will move the chain of this conditional test values to the loop latch, after that, they may not dominate the in-loop uses anymore:
loop header
v1 = phi(0, ...)
v2 = v1 + 1
If v2 < 3 ...
loop body:
v4 = v2 - 1
So we need to create a new phi v5 at the loop header to merge the control flow from the loop guard to the loop header and the loop latch to the loop header and use this phi to replace the in-loop use v4. e.g.
loop header:
v1 = phi(0, ...)
v5 = phi(v2', v2) ;;; v2' lives in loop guard
loop body:
v4 = v5 - 1
loop latch:
v2 = v1 + 1
If v2 < 3 ...
Add corresponding argument for phis at loop exits since new edge from loop guard to loop exit had been created
Loop header no longer dominates loop exit, a new edge from loop guard to loop exit is created, this is not reflected in proxy phis in loop exits, i.e. these proxy phis miss one argument that comes from loop guard, we need to reconcile the divergence
loop guard
|
loop exit loop exit /
| => | /
v1=phi(v1) v1=phi(v1 v1') <= add missing g2e argument v1'
Since LCSSA ensures that all loop uses are closed, i.e. any out-of-loop uses are replaced by proxy phis in loop exit, we only need to add missing argument v1' to v1 proxy phi
Update proxy phi to use the loop phi's incoming argument which comes from loop latch since loop latch may terminate the loop now
Loop latch now terminates the loop. If proxy phi uses the loop phi that lives in loop header, it should be replaced by using the loop phi's incoming argument which comes from loop latch instead, this avoids losing one update.
Before:
loop header:
v1 = phi(0, v4)
loop latch:
v4 = v1 + 1
loop exit
v3 = phi(v1, ...)
After:
loop header:
v1 = phi(0, v4)
loop latch:
v4 = v1 + 1
loop exit
v3 = phi(v4, ...) ;; use v4 instead of v1
5. Bug Fix
The loop exit created by BlockJumpTable will not be discovered by findExits().
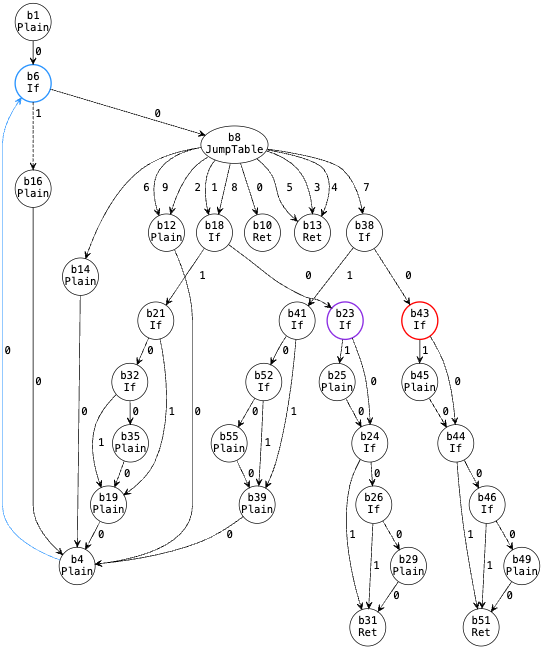
The current loop exits are only b23 and b43, but the expected ones should include b10 and b13.
6. Performance Regression
6.1 block layout
In original block layout algorithm, regardless of whether successors of the current basic block have likely attribute, the layout algorithm would place each successor right after the current basic block one by one. The improved algorithm employs a greedy approach, aiming to allocate the basic blocks of a "trace" together as much as possible, in order to minimize excessive jumps. i.e. For given IR:
b1:
BlockIf -> b2 b3 (likely)
b2:
BlockPlain->b4
b4:
...
The final block orders are as follows:
baseline:
b1 b2 b3 b4
opt:
b1 b2 b4 b3
6.2 register allocation
After loop rotation, there are some significant performance regression. Taking the strconv.Atoi benchmark as an example, the performance deteriorates by about 30%. In the following example:
;; baseline
b12
00025 JMP 30
00026 LEAQ (BX)(BX*4), R8
00027 MOVBLZX DI, DI
00028 INCQ AX
00029 LEAQ (DI)(R8*2), BX
00030 CMPQ AX, SI
b18
00031 JGE 38
00032 MOVBLZX (DX)(AX*1), DI
00033 ADDL $-48, DI
00034 CMPB DI, $9
b19
00035 JLS 26
;; opt
b27
00027 JMP 29
00028 MOVQ R8, AX
00029 MOVBLZX (DX)(AX*1), DI
00030 ADDL $-48, DI
00031 CMPB DI, $9
b19
00032 JHI 40
00033 LEAQ 1(AX), R8
00034 LEAQ (BX)(BX*4), BX
00035 MOVBLZX DI, DI
00036 LEAQ (DI)(BX*2), BX
00037 CMPQ SI, R8
b20
00038 JGT 28
b20
00039 JMP 43
In the code generated by the baseline, the loop includes 10 instructions [26-35], whereas the optimized code contains 11 instructions [28-38]. This is because the baseline's loop increment instruction i++ produced incq ax, while the optimized code generated is:
00028 MOVQ R8, AX
...
00033 LEAQ 1(AX), R8
The culprit is empty basic block created during the split critical edge after rotation, which affects the logic of register allocation;
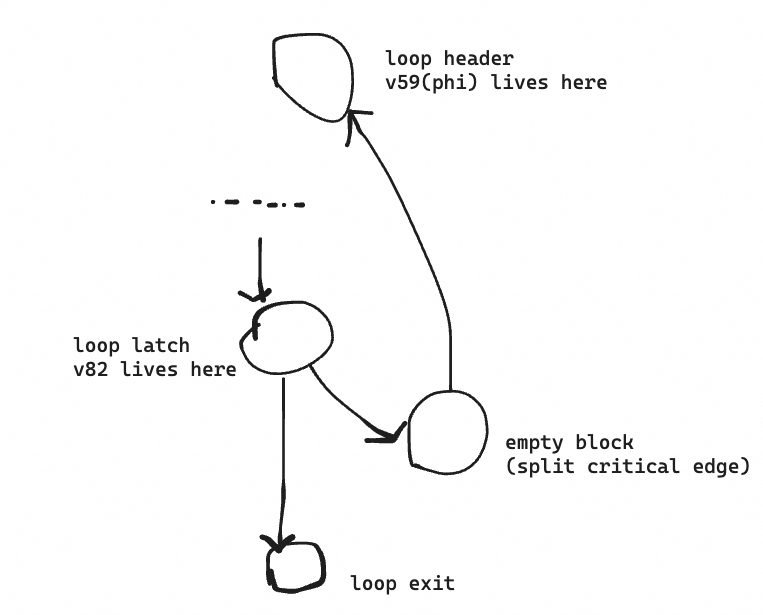
During the register allocation process, for the instruction v82 = ADDQconst <int> [1] v59, the register allocator checks if v59 is in the next basic block and examines the expected register for v59. For example, if v59 is in the next basic block and its expected register is R8, then the register allocator would also allocate the R8 register for v82 = ADDQconst <int> [1] v59, because the input and result are in the same register, allowing the production of incq. However, after loop rotation, the next basic block for v82 is the newly inserted empty basic block from the split critical edge, preventing the register allocator from knowing the expected register for v59, so v82 and v59 end up being allocated to different registers, R8 and RAX, resulting in an extra mov instruction. The proposed fix is to skip empty basic block and directly check the next non-empty basic block for the expected register.
6.3 high branch miss
BenchmarkSrcsetFilterNoSpecials shows noticeable performance regression due to high branch mispredictions after the optimization
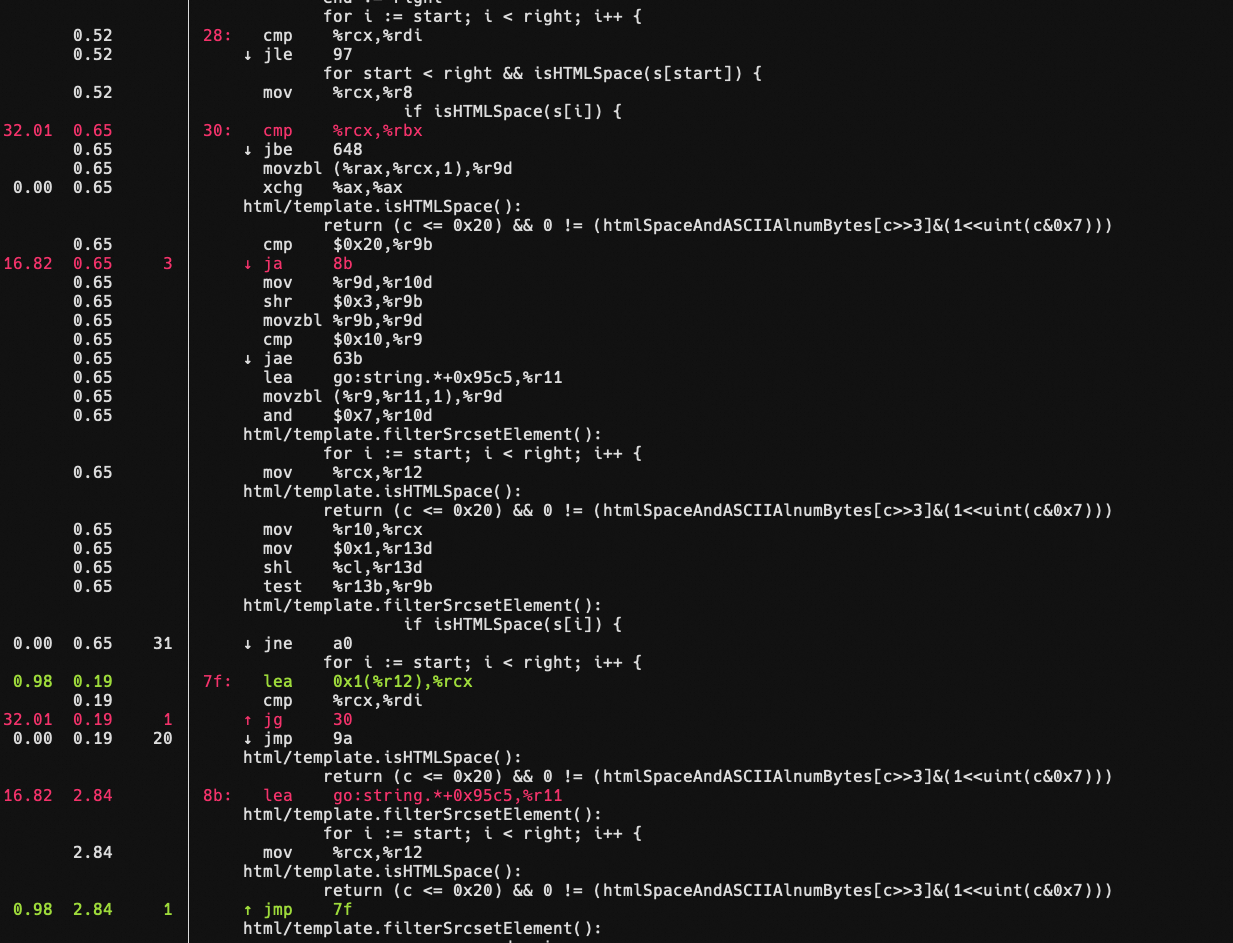
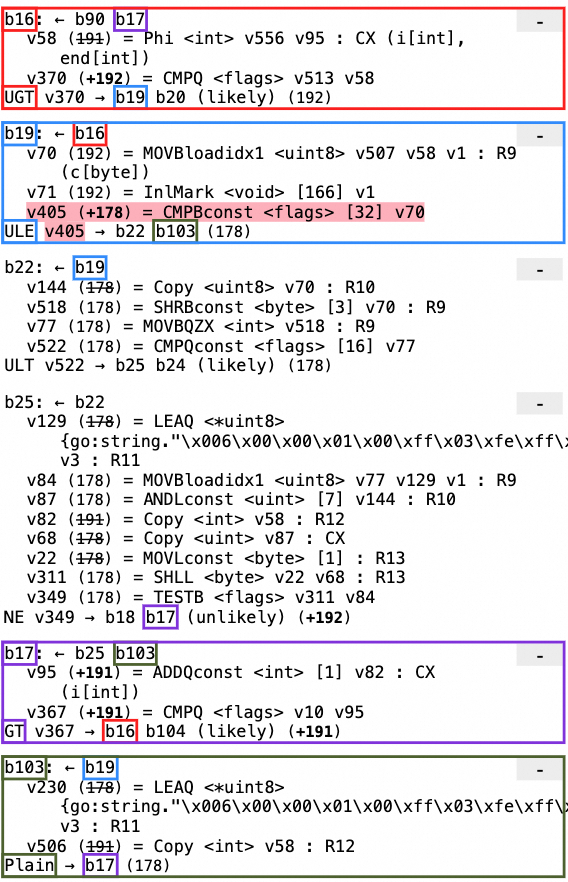
The program execution flow is b16->b19->b103->b17->b16(loop), but b103 is placed below the loop latch b17, leading to high branch misses as illustrated above (ja 8b(goto b103),jmp 7f(goto b17), and jg 30(goto b16)). I propose to always place the loop header(or loop latch after real rotation) to the bottom of the loop.
7. Test fix
7.1 codegen/issue58166.go
codegen/issue58166.go fails, it expected loop increment to generate incq, but instead, it ended up generating leaq+mov.
During register allocation, v114 couldn't be allocated to the same register r8 as v149, due to the fact that there were two uses of v114 (v136 and v146) right after v149. As a result, unexpected instructions were produced.
b26:
v149 = ADDQconst <int> [1] v114
v135 = MULSD <float64> v87 v123
v136 = ADDSDloadidx8 <float64> v135 v50 v114 v160 ;;use of v114
v146 = MOVSDstoreidx8 <mem> v50 v114 v136 v160 ;; use of v114
v91 = CMPQ <flags> v15 v149
After loop rotation, the schedule pass calculated scores for b26, resulting in the following order:
Before schedule:
b26:
v135 (12) = MULSD <float64> v87 v123
v136 (12) = ADDSDloadidx8 <float64> v135 v50 v114 v160
v146 (12) = MOVSDstoreidx8 <mem> v50 v114 v136 v160
v149 (+11) = ADDQconst <int> [1] v114
v91 (+11) = CMPQ <flags> v15 v149
After schedule:
b26:
v149 = ADDQconst <int> [1] v114
v135 = MULSD <float64> v87 v123
v136 = ADDSDloadidx8 <float64> v135 v50 v114 v160
v146 = MOVSDstoreidx8 <mem> v50 v114 v136 v160
v91 = CMPQ <flags> v15 v149
An optimization was made as per https://go-review.googlesource.com/c/go/+/463751, which prioritizes values that are used within their live blocks. Since v149 is used by v91 in the same block, it has a higher priority.
The proposed fix is that if a value is used by a control value, then it should have the lowest priority. This would allow v146 and v91 to be scheduled closely together. After this scheduling, there would be no use of v114 after v146, thus allowing v146 and v114 to be allocated to the same register, ultimately generating an incq instruction.
7.2 test/nilptr3.go
func f4(x *[10]int) {
...
_ = x[9] // ERROR "generated nil check"
for {
if x[9] != 0 { // ERROR "removed nil check"
break
}
}
}
Loop rotation duplicates conditional test Values into loop gaurd block:
...
loopGuard:
v6 (+159) = NilCheck <*[10]int> v5 v1
v15 (159) = OffPtr <*int> [72] v6
v9 (159) = Load <int> v15 v1
v7 (159) = Neq64 <bool> v9 v13
If v7 → b5 loopHeader
loopHeader:
v8 (+159) = NilCheck <*[10]int> v5 v1
v11 (159) = OffPtr <*int> [72] v8
v12 (159) = Load <int> v11 v1
v14 (159) = Neq64 <bool> v12 v13
Plain → b3
So we need to add a loop nilcheckelim pass after all other loop opts to remove the v6 NilCheck in the loop guard, but that's not the whole story.
The code _ = x[9] is expected to generate a nilcheck, buttighten pass will move the LoweredNilCheck from the loop entry b1 to the loop guard. At that point, there happens to be a CMPQconstload in the loop guard that meets the conditions for late nilcheckelim, resulting in the elimination of the LoweredNilCheck as well. Therefore, we also need to modify the test to no longer expect the generated code to contain a nilcheck.

7.3 test/writebarrier.go
func f4(x *[2]string, y [2]string) {
*x = y // ERROR "write barrier"
z := y // no barrier
*x = z // ERROR "write barrier"
}
We added loop opt pass after writebarrier pass, *x = y becomes dead store, simply removing ERROR directive fixes this case.
Comment From: dr2chase
Do you have a favorite reference for LCSSA? I understand what it's about from reading your patch (and I can see why we would want it) but there are also corner cases (multiple exits to different blocks, exits varying in loop level of target) and it would be nice to see that discussed. I tried searching, but mostly got references to LLVM and GCC internals.
Also, how far are you into a performance evaluation for this? Experience in the past (I also tried this) was uncompelling on x86, better but not inspiring for arm64 and ppc64. But things are changing; I'm working on (internal use only) pure and const calls that would allow commoning, hoisting, and dead code elimination, and arm64 is used much more now in data centers than five years ago.
Comment From: y1yang0
Do you have a favorite reference for LCSSA?
LLVM's doc is a good reference, maybe I can write some doc later either in go/doc or other place.
but there are also corner cases (multiple exits to different blocks, exits varying in loop level of target) and it would be nice to see that discussed.
Yes! This is the most challenging part.
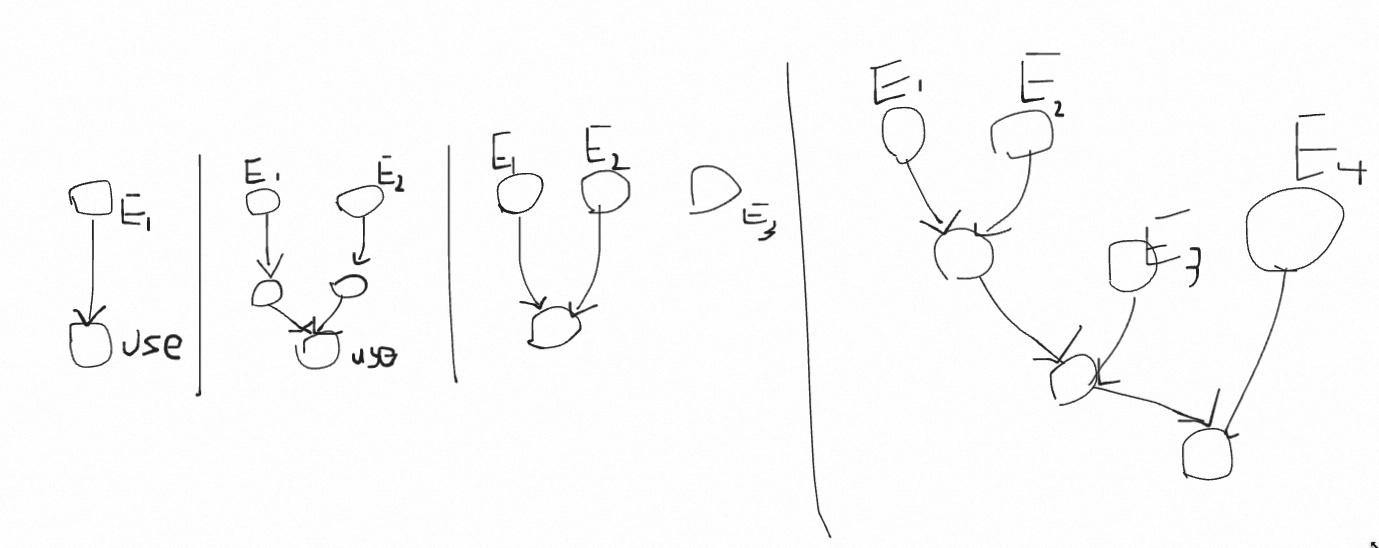
- For case 1, only one exit block, E1 doms use block, so we insert proxy phi at E1
- For case2, all exits E1 and E2 dominates all predecessors of use block, insert proxy phi p1,p2 at E1 and E2 respectively, and insert yet another proxy phi p3 at use block to merge p1, p2.
- For case 3 , use block is reachable from E1 and E2, but not E3, this is hard, maybe we can start from all loop exits(including inner loop exits) through dominance frontier and see if we can reach the use block, i.e. E1 and E2 has same dominance frontier, we insert proxy phi at there. This is hard, I'll give up now.
- For case4: ditto.
Experimental data(building go toolchain itself) shows that 98.27% loops can apply LCSSA.
Comment From: laboger
I agree that being able to hoist loads of constants and invariants should help loops in ppc64 and probably arm64. Previous hoisting CLs didn't attempt loads which is why there was not much benefit, and I couldn't make it work because of what tighten does with loads is at odds with what hoisting is trying to do.
I also recently tried to do a change to add PCALIGN to the top of loop body but because of the way looprotate moved the blocks, the alignment couldn't be inserted in the correct place. With this improved way of doing looprotate it should be more straightforward to insert the PCALIGN in the appropriate spot.
I have done some performance comparisons between gccgo and Golang on ppc64 since gccgo does better at optimizing loops in most cases on ppc64. That can show what improvement is possible.
On Mon, Oct 23, 2023 at 9:30 PM Yi Yang @.***> wrote:
Do you have a favorite reference for LCSSA?
LLVM's doc https://llvm.org/docs/LoopTerminology.html#loop-closed-ssa-lcssa is a good reference, maybe I can write some doc later either in go/doc or other place.
but there are also corner cases (multiple exits to different blocks, exits varying in loop level of target) and it would be nice to see that discussed.
Yes! This is the most challenging part.
[image: image] https://user-images.githubusercontent.com/5010047/277528772-13f97a7b-4fd3-46f0-b668-cd41abea860a.png
- For case 1, only one exit block, E1 doms use block, so we insert proxy phi at E1
- For case2, all exits E1 and E2 dominates all predecessors of use block, insert proxy phi p1,p2 at E1 and E2 respectively, and insert yet another proxy phi p3 at use block to merge p1, p2.
- For case3, use block is reachable from E1 and E2, but not E3, this is hard, maybe we need to we start from all loop exits(including inner loop exits) though dominance frontier and see if we can reach to the use block. THis is hard, we give up now.
Experimental data(building go toolchain itself shows that 98.27% loops can apply LCSSA.
— Reply to this email directly, view it on GitHub https://github.com/golang/go/issues/63670#issuecomment-1776395373, or unsubscribe https://github.com/notifications/unsubscribe-auth/ACH7BDAZ7M4ENQRHATOCOHLYA4R4HAVCNFSM6AAAAAA6K2QRESVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTONZWGM4TKMZXGM . You are receiving this because you are subscribed to this thread.Message ID: @.***>
Comment From: laboger
I tried your source tree. It looks like there is a bug when building the go1 benchmark test Fannkuch. This test used to be under test/bench/go1 but it was removed in go 1.21. If you go back to go 1.20 you can build it. One of the loops in the Fannkuch test doesn't exit.
I also noticed that hoisting the NilCheck is not always a good thing. I found a similar problem recently with tighten when a load gets moved to a different block. There is a later pass to eliminate unnecessary NilChecks, but it only gets optimized if the NilCheck is in the same block as the load or store that uses the same pointer/address. Look at the loop in math.BenchmarkSqrtIndirectLatency.
TEXT math_test.BenchmarkSqrtIndirectLatency(SB) /home/boger/golang/y1yang0/go/src/math/all_test.go
for i := 0; i < b.N; i++ {
0x13c660 e88301a0 MOVD 416(R3),R4 // ld r4,416(r3)
0x13c664 7c240000 CMP R4,R0 // cmpd r4,r0
0x13c668 40810028 BLE 0x13c690 // ble 0x13c690
0x13c66c 8be30000 MOVBZ 0(R3),R31 // lbz r31,0(r3) <-- This should stay before the MOVD that is based on r3.
0x13c670 38600000 MOVD $0,R3 // li r3,0
0x13c674 06100006 c800f50c PLFD 455948(0),$1,F0 // plfd f0,455948
0x13c67c 38630001 ADD R3,$1,R3 // addi r3,r3,1
return sqrt(x)
0x13c680 fc00002c FSQRT F0,F0 // fsqrt f0,f0
for i := 0; i < b.N; i++ {
0x13c684 7c241800 CMP R4,R3 // cmpd r4,r3
x = f(x)
0x13c688 4181fff4 BGT 0x13c67c // bgt 0x13c67c
0x13c68c 4800000c BR 0x13c698 // b 0x13c698
0x13c690 06100006 c800f4f0 PLFD 455920(0),$1,F0 // plfd f0,455920
GlobalF = x
0x13c698 06100018 d800bb70 PSTFD 1620848(0),$1,F0 // pstfd f0,1620848
}
0x13c6a0 4e800020 RET // blr
Comment From: randall77
and I couldn't make it work because of what tighten does with loads is at odds with what hoisting is trying to do.
I don't think this should be a problem. True that hoisting and tightening are working in opposite directions, but tightening should never move anything into a loop, so as long as you're correctly hoisting out of a loop then tightening should not undo that work. (Or tightening has a bug.)
Comment From: randall77
(Or maybe you mean the rematerialization of constants that regalloc does? We could disable rematerialization for constants that would require a load from a constant pool.)
Comment From: laboger
(Or maybe you mean the rematerialization of constants that regalloc does? We could disable rematerialization for constants that would require a load from a constant pool.)
I mean loads of constant values which shouldn't have any aliases. I think the rematerialization flag mostly controls where this gets loaded, and tighten has some effect on that. It's been a while since I tried to play with it.
Base addresses of arrays, slices, etc. should be constant/invariant and hoisted instead of reloaded at each iteration. I can't seem to get that to happen.
I should add that I don't know if there is anything in place right now to allow this type of hoisting even without the rematerialization done in regalloc. This statement is based on experimenting with various CLs that have tried to enable hoisting including the new one mentioned in this issue.
Comment From: laboger
Here's an example of what I meant above, from test/bench/go1.revcomp (back before it was removed)
v257
00294 (64) MOVB R11, (R6)(R9)
v259
00295 (+62) ADD $1, R4, R4
v343
00296 (+62) CMP R4, R10
b44
00297 (62) BGE 149
v241
00298 (62) MOVBZ (R3)(R4), R11
v243
00299 (+63) ADD $-1, R9, R9
v151
00300 (+64) MOVD $test/bench/go1.revCompTable(SB), R12 <--- this is a constant load that should be hoisted
v248
00301 (64) MOVBZ (R12)(R11), R11
v15
00302 (64) CMPU R5, R9
b45
00303 (64) BGT 294
Comment From: randall77
I think this is just a problem with our register allocator. At this point https://github.com/golang/go/blob/9cdcb01320d9a866e46a2daedb9bde16e0d51278/src/cmd/compile/internal/ssa/regalloc.go#L1402 we decide not to issue a rematerializeable op, as we can always issue it just before its use. But if the (a?) use is in deeper loop nest than the definition, we should issue it at its definition point.
Comment From: y1yang0
I also recently tried to do a change to add PCALIGN to the top of loop body but because of the way looprotate moved the blocks, the alignment couldn't be inserted in the correct place. With this improved way of doing looprotate it should be more straightforward to insert the PCALIGN in the appropriate spot. I have done some performance comparisons between gccgo and Golang on ppc64 since gccgo does better at optimizing loops in most cases on ppc64. That can show what improvement is possible.
Do you means something like loop alignment. That's interesting.
I tried your source tree. It looks like there is a bug when building the go1 benchmark test Fannkuch. This test used to be under test/bench/go1 but it was removed in go 1.21. If you go back to go 1.20 you can build it. One of the loops in the Fannkuch test doesn't exit.
Thanks a lot! I'll fix this then. The current development is almost complete, and the remaining work mainly involves ensuring robustness and optimizing performance. I will try testing go1 benchmark and golang/benchmarks and then resolve any issues that may arise. (I am thinking about adding support for simple stress testing to the golang compiler, i.e. allow a pass runs between [start pass, end pass], and executing the pass after each pass within that range. This approach would greatly ensure the stability of optimization/transformation.)
Update: I confirmed this bug, TBAA thinks they are NoAlias but actually they do alias, because unsafe pointer may aliases with everything
#v23 = SelectN <unsafe.Pointer> [0] v21 (perm1.ptr[*int])#v328 = AddPtr <*int> v23 v488#NoAlias
v306 (+58) = Load <int> v23 v387 (perm0[int])
v299 (60) = Store <mem> {int} v328 v320 v400
Comment From: laboger
Do you means something like loop alignment. That's interesting.
Yes, there are several ports that support the PCALIGN directive and currently it is only used in assembly implementations. It would be worthwhile to have the compiler generate it for appropriate loops.
we decide not to issue a rematerializeable op, as we can always issue it just before its use. But if the (a?) use is in deeper loop nest than the definition, we should issue it at its definition point.
What do you mean by definition point for a constant? Do you mean that the loop hoisting code would generate the definition?
Thanks a lot! I'll fix this then. The current development is almost complete, and the remaining work mainly involves ensuring robustness and optimizing performance. I will try testing go1 benchmark and golang/benchmarks and then resolve any issues that may arise.
I still don't think the way NilChecks are hoisted is providing the best performance, as I mentioned earlier.
Comment From: randall77
Currently, if you have this before regalloc:
v1 = MOVDaddr {myGlobalVariable}
loop:
v2 = MOVBload v1 mem
Then after regalloc it moves v1 inside the loop
loop:
v1 = MOVDaddr {myGlobalVariable}
v2 = MOVBload v1 mem
We shouldn't do that move if the destination is in a loop. We should force v1 to stay at its original definition point.
Or maybe we reissue it just before the loop starts? In any case, don't move it into the loop.
This is currently a problem whether v1 was originally in the loop and a hoisting phase moved it out, or it was originally outside the loop in the user's code.
Comment From: gopherbot
Change https://go.dev/cl/551381 mentions this issue: cmd/compile: loop invariant code motion
Comment From: Jorropo
Have I missed compilebench results, what are the compiling time drawbacks ?
Comment From: laboger
(Or maybe you mean the rematerialization of constants that regalloc does? We could disable rematerialization for constants that would require a load from a constant pool.)
@randall77 Yes, that is what I was referring to in an earlier post. There's an example of this in hash/fnv.(*sum64).Write. The load of the constant is before the loop until it gets to regalloc which puts it immediately before its use inside the loop. In the past I tried to experiment with disabling rematerialization for cases like that but that caused other errors that I believe were due to something that the tighten pass was doing.
Comment From: merykitty
Regarding TBAA, please note that a pointer in Go might not actually point to memory allocated by Go, this may defeat all kinds of analysis as 2 completely unrelated pointers can point to elements of a C union and thus alias each other.
Comment From: Jorropo
Even while staying in go land almost most types can alias with each other.
What you currently can't do is write to some offset which was originally allocated as a pointer as a non pointer (because you will be missing write barrier calls). The inverse might also be problematic (as you would have write barrier for things the GC does not think are pointers) I don't know. You can't hold onto a pointer as a non pointer across writes either. As far as I recall everything else works.
This is stronger than what we guarantee in documentation on some points.
Comment From: y1yang0
@merykitty @Jorropo That makes sense, I was convinced that cornerstone of TBAA (rule 7) does not hold in Golang, I'll revert TBAA along with some test fixes later.
Comment From: randall77
Here's an example of a function that could benefit from hoisting some code out of a loop:
func f(x, y []int) int {
r := 0
for i := 0; i < min(len(x), len(y)); i++ {
r += x[i] * y[i]
}
return r
}
The computation of min would be nice to hoist out of the loop. Currently it isn't.
Comment From: y1yang0
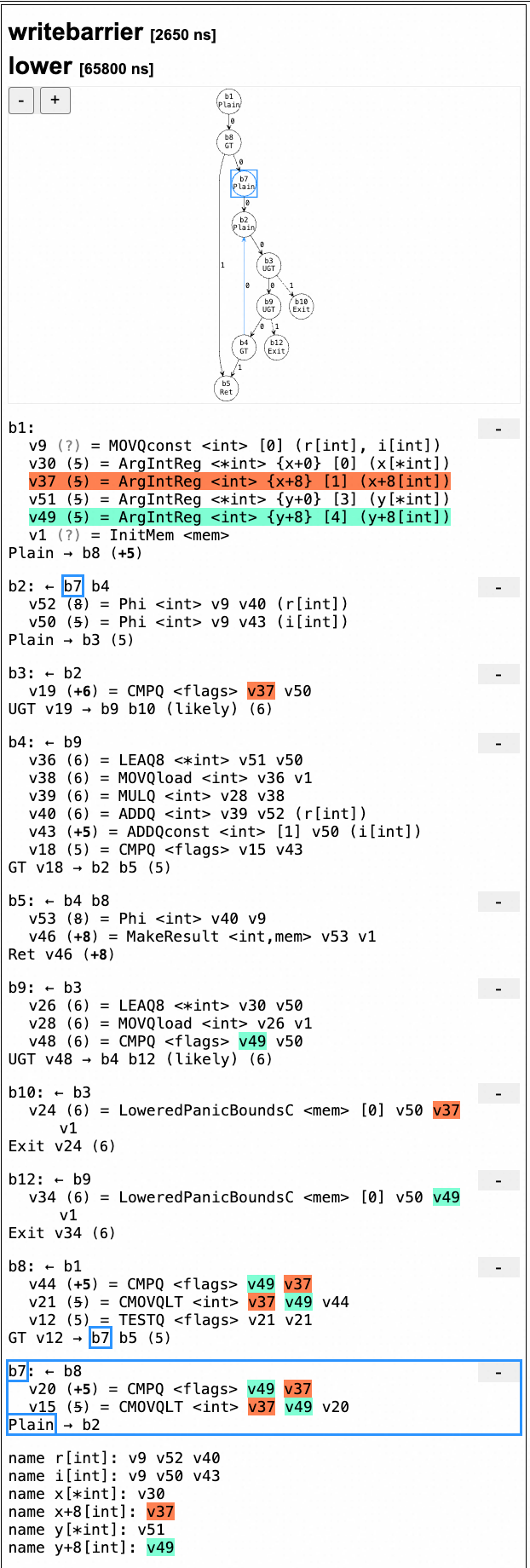
Here's an example of a function that could benefit from hoisting some code out of a loop:
Of course, this is a good candidate for LICM:
{kind=link}
min(...) is computed once within b7
Comment From: y1yang0
Hi team, while the corresponding changes are big and the performance gains are modest, this work could create a solid foundation for more impactful optimizations in the future. I understand the community may prioritize initiatives with clearer immediate impact or have concerns about complexity/resource allocation at this stage, but I’d appreciate your thoughts on whether this aligns with our long-term goals. Would you like to explore moving this forward as-is, refining the approach further, or deferring it to focus on narrower improvements first?
Comment From: randall77
I am not excited about this at the moment. It seems like a lot of complexity for not much gain. It probably only applies to very specific small loops.
I think there are other optimizations we could do that will take advantage of the same opportunities. For example, loop unrolling. If we unrolled small loops 2x, then that will effectively lift half of the loop-invariant code (because it will be CSEd between the two loop bodies).