- if you refer to documentary of timeseries_dataset_from_array, there is an example similarly like this ( I changed parameter for quickly proof):
data = np.arange(10)
x = data[:-3] # x will be [0, 1, 2, 3, 4, 5, 6]
y = data[3:] # y will be [3, 4, 5, 6, 7, 8, 9]
batch_data = timeseries_dataset_from_array(x, y, 3, 1)
for input, target in batch_data:
print(input, target)
It will create samples like [0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5],[4, 5, 6] with labels [3, 4, 5, 6, 7]. However, obviously, it misses samples [5, 6, 7], [6, 7, 8] with lables [8, 9].
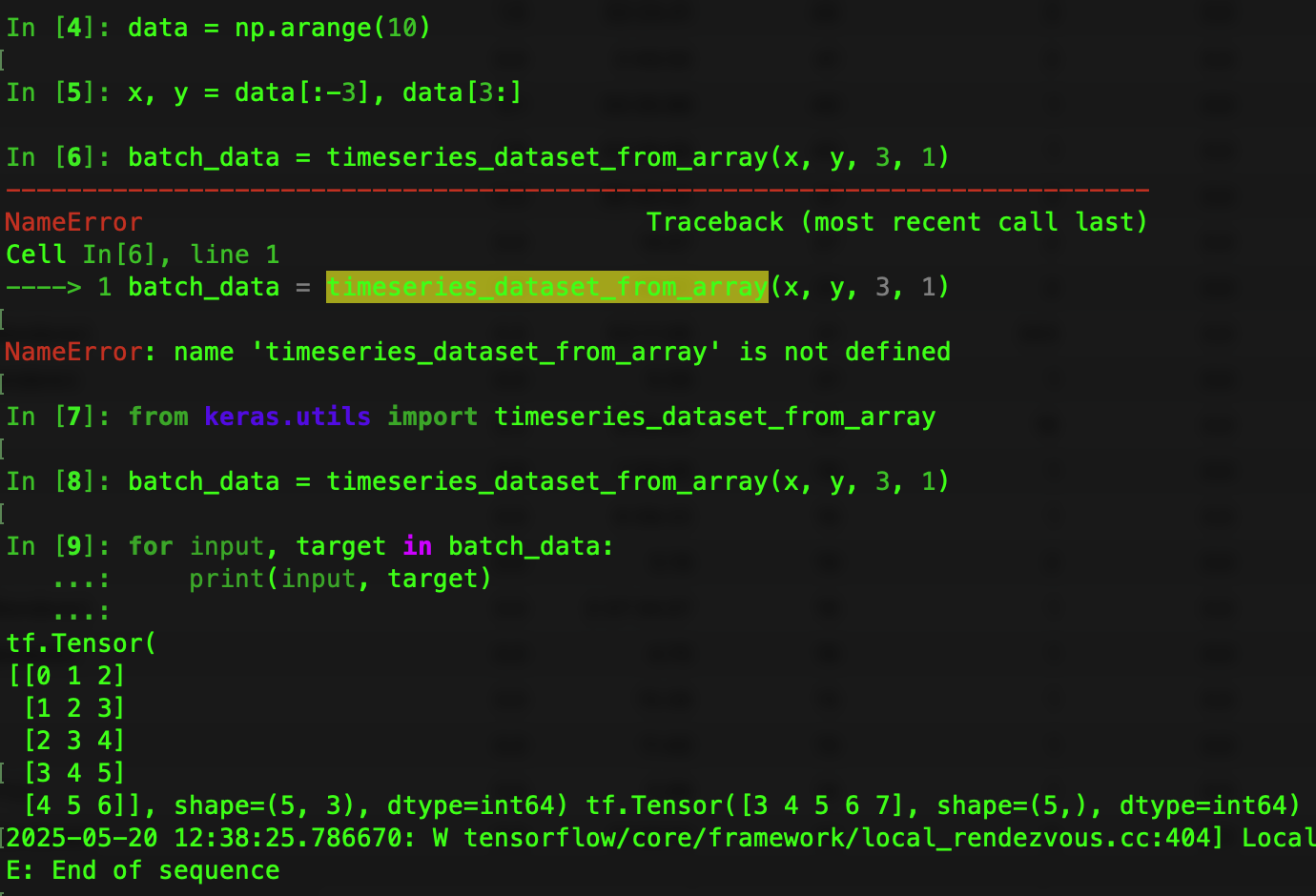
The api may expected to have the x, and y with same length, but it will miss some samples. However, if you feed x with data, and y, the output should be correct. That means, the example 2 in this api should be changed!!!
Comment From: dhantule
Hi @zhangpanzhan, Thanks for reporting this.
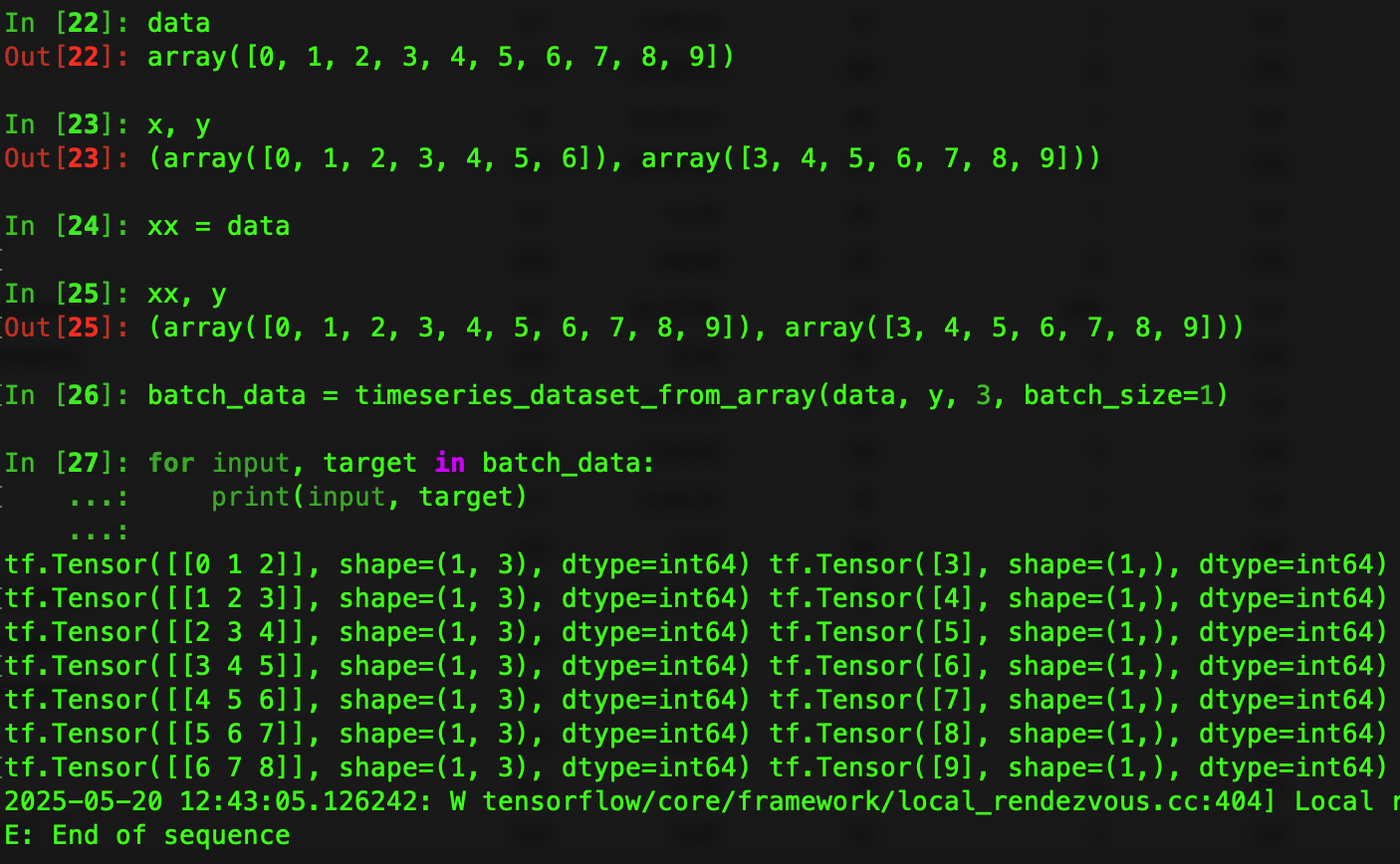
After generating the sequence [4, 5, 6] which corresponds to target 7, there are no more valid sequences of length 3 that can be extracted from x, so there are no sequences generated for target 8 and 9. So, when you replace x with data, now there are enough sequences that can be generated for the given targets.
I have tested Example 2 and it's working fine in this gist.
Comment From: github-actions[bot]
This issue is stale because it has been open for 14 days with no activity. It will be closed if no further activity occurs. Thank you.
Comment From: github-actions[bot]
This issue was closed because it has been inactive for 28 days. Please reopen if you'd like to work on this further.