The same code with DataFrame.apply is >4x slower when the data is in Arrow dtypes versus Numpy.
Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this issue exists on the latest version of pandas.
-
[x] I have confirmed this issue exists on the main branch of pandas.
Reproducible Example
import pandas as pd
import numpy as np
import pyarrow as pa
import time
NUM_ROWS = 500_000
df = pd.DataFrame({"A": np.arange(NUM_ROWS) % 30, "B": np.arange(NUM_ROWS)+1.0})
print(df.dtypes)
df2 = df.astype({"A": pd.ArrowDtype(pa.int64()), "B": pd.ArrowDtype(pa.float64())})
print(df2.dtypes)
t0 = time.time()
df.apply(lambda r: 0 if r.A == 0 else (r.B // r.A), axis=1)
print(f"Non-Arrow time: {time.time() - t0:.2f} seconds")
t0 = time.time()
df2.apply(lambda r: 0 if r.A == 0 else (r.B // r.A), axis=1)
print(f"Arrow time: {time.time() - t0:.2f} seconds")
Output with Pandas 2.3 on a local M1 Mac (tested on main branch too).
A int64
B float64
dtype: object
A int64[pyarrow]
B double[pyarrow]
dtype: object
Non-Arrow time: 3.21 seconds
Arrow time: 16.66 seconds
Installed Versions
Prior Performance
No response
Comment From: jbrockmendel
Any hotspots show up in profiling?
Comment From: ehsantn
Profiler output is a bit hard to read as usual. Here are some snakeviz screenshots. The fast_xs function has different code paths for ExtensionDtype that look suspicious to me. find_common_type and _from_sequence stand out looks like.
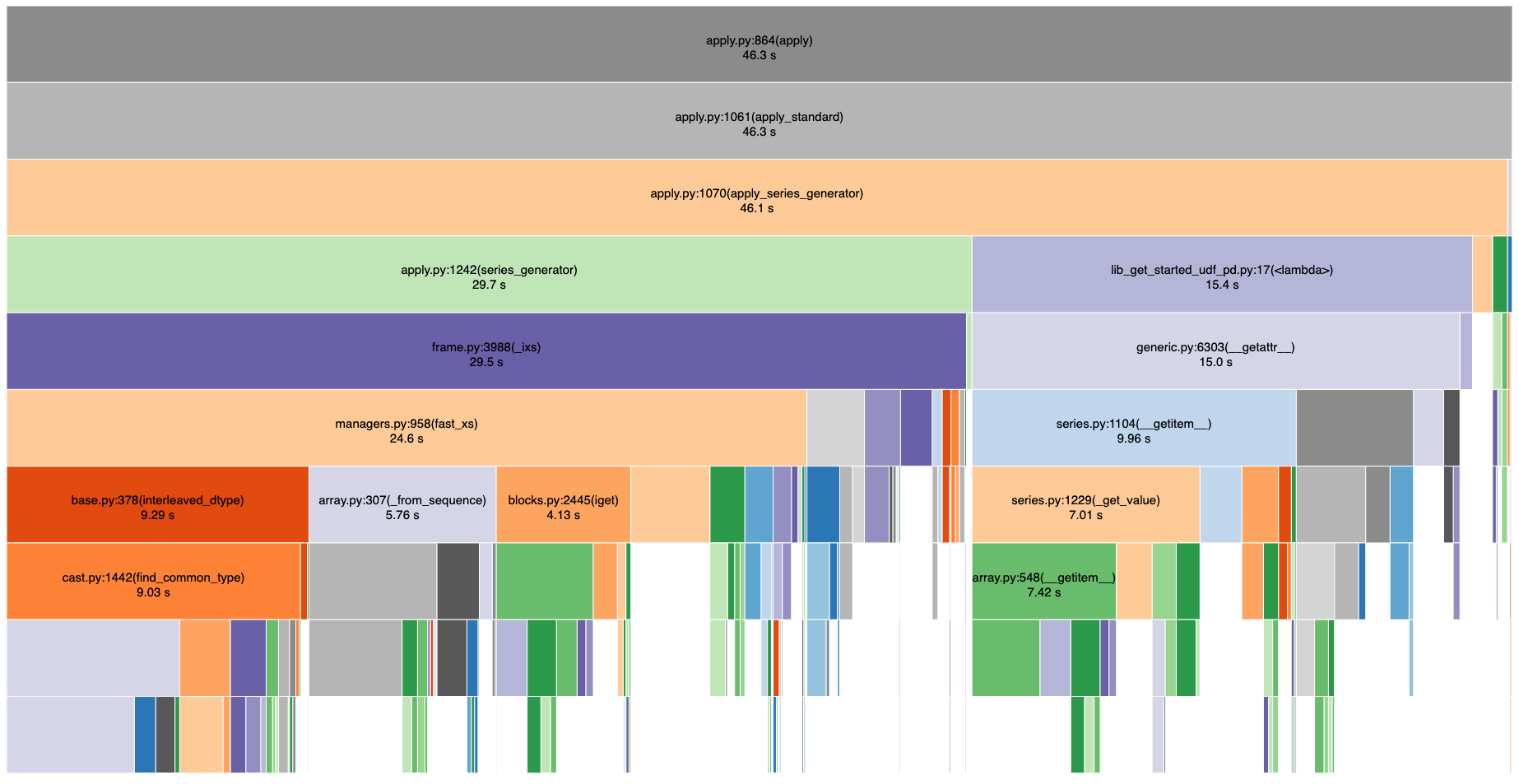
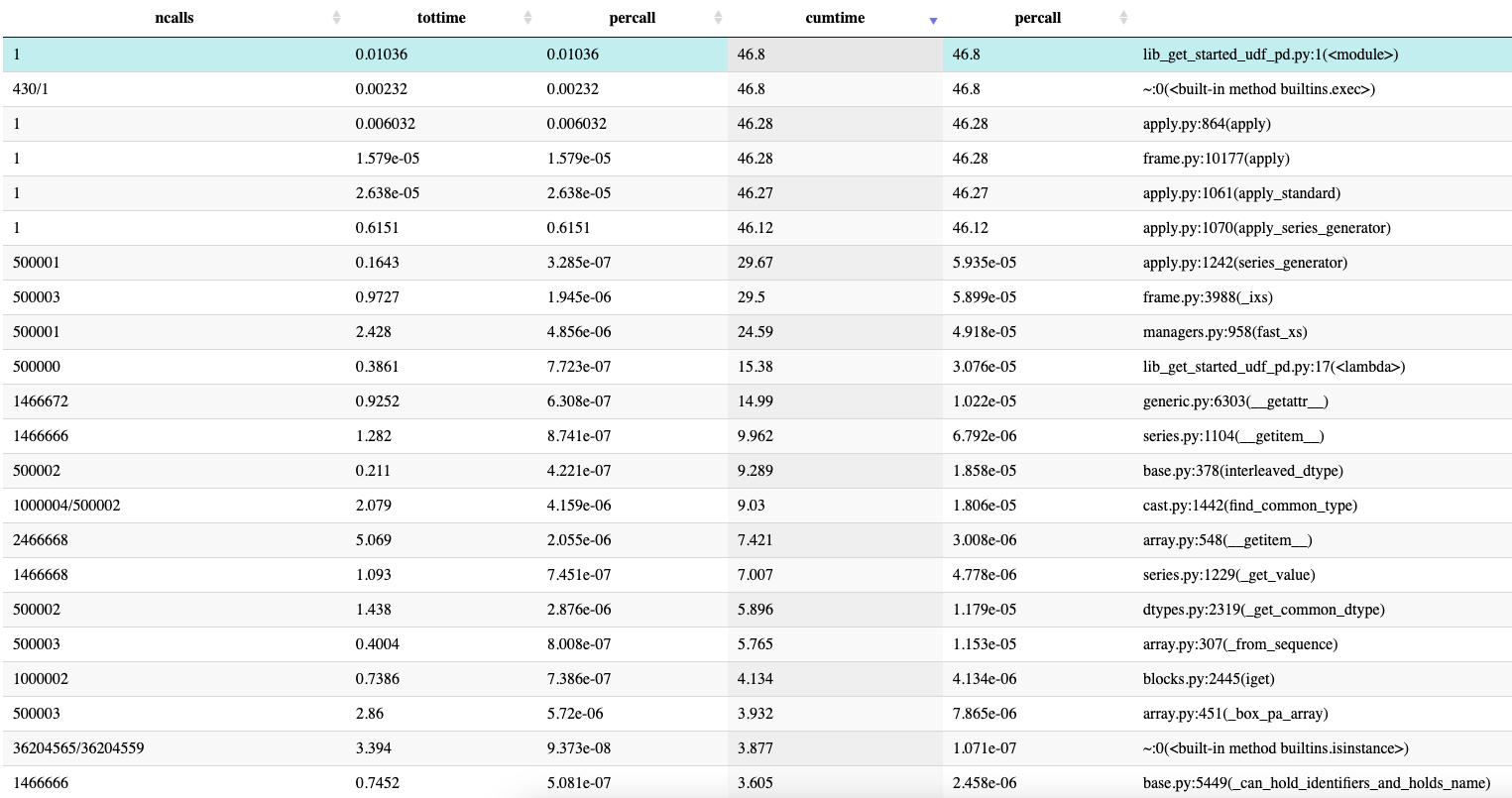
Comment From: jbrockmendel
That's a tough one. In core.apply.FrameColumnApply.series_generator we have a fastpath that only works with numpy dtypes.
We might be able to get some mileage for EA Dtypes by changing
for i in range(len(obj)):
yield obj._ixs(i, axis=0)
to something like
dtype = ser.dtype
for i in range(len(obj)):
new_vals = the_part_of_fast_xs_after_interleaved_dtype_is_called()
new_arr = type(ser.array)._from_sequence(new_vals, dtype=dtype)
yield obj._constructor(new_arr, name=name)
That would save 20% of the runtime by avoiding the interleaved_dtype calls.
Comment From: ehsantn
This difference makes sense but what's confusing is that the performance issue goes away if one of the column is changed to string:
import pandas as pd
import numpy as np
import pyarrow as pa
import time
NUM_ROWS = 500_000
df = pd.DataFrame({"A": np.arange(NUM_ROWS) % 30, "B": np.arange(NUM_ROWS).astype(str)})
print(df.dtypes)
df2 = df.astype({"A": pd.ArrowDtype(pa.int64()), "B": pd.ArrowDtype(pa.large_string())})
print(df2.dtypes)
t0 = time.time()
df.apply(lambda r: 0 if r.A == 0 else (int(r.B) // r.A), axis=1)
print(f"Non-Arrow time: {time.time() - t0:.2f} seconds")
t0 = time.time()
df2.apply(lambda r: 0 if r.A == 0 else (int(r.B) // r.A), axis=1)
print(f"Arrow time: {time.time() - t0:.2f} seconds")
A int64
B object
dtype: object
A int64[pyarrow]
B large_string[pyarrow]
dtype: object
Non-Arrow time: 3.35 seconds
Arrow time: 3.21 seconds
Comment From: jbrockmendel
id have to look at the profiling output but my prior puts a lot of weight on "object dtype is just that bad"
Comment From: ehsantn
But in this case object dtype is basically the same as Numpy numeric dtype in the no-arrow cases (3.35 vs 3.21, see first numbers in the two outputs). The difference is that pa.large_string() is a lot better than pa.float64() in the Arrow cases.
Comment From: jbrockmendel
In this case df.iloc[0] has an object dtype even when you have pyarrow dtypes, so it the iteration in series_generator goes through the numpy fastpath
(Looking at profiling results, I think we can trim a bunch by changing is_object_dtype check in _can_hold_identifiers_and_holds_name to just self.dtype == object)
Comment From: ehsantn
Ok, makes sense. Thanks for the explanation.