Go version
go 1.24.1 darwin/arm64 Apple M1
Summary
I'm working on a performance optimization in our business logic and noticed a significant performance difference when swapping the strings on either side of an equality operator. After simplifying the logic to a contains function, I was able to reproduce the behavior. Below are the sample code and benchmarks
Sample Code
var containsSlice = func() []string {
return []string{
"12312312",
"abcsdsfw",
"abcdefgh",
"qereqwre",
"gwertdsg",
"hellowod",
"iamgroot",
"theiswer",
"dg323sdf",
"gadsewwe",
"g42dg4t3",
"4hre2323",
"23eg4325",
"13234234",
"32dfgsdg",
"23fgre34",
"43rerrer",
"hh2s2443",
"hhwesded",
"1swdf23d",
"gwcdrwer",
"bfgwertd",
"badgwe3g",
"lhoejyop",
}
}()
func containsStringA(strs []string, str string) bool {
for i := range strs {
if strs[i] == str {
return true
}
}
return false
}
func containsStringB(strs []string, str string) bool {
for i := range strs {
if str == strs[i] {
return true
}
}
return false
}
func BenchmarkContainsStringA(b *testing.B) {
for n := 0; n <= b.N; n++ {
containsStringA(containsSlice, "lhoejyop")
}
}
func BenchmarkContainsStringB(b *testing.B) {
for n := 0; n <= b.N; n++ {
containsStringB(containsSlice, "lhoejyop")
}
}
Benchmark Result
goos: darwin
goarch: arm64
pkg: go-playground/simple
cpu: Apple M1
BenchmarkContainsStringA-8 19314198 61.63 ns/op
BenchmarkContainsStringB-8 72874310 16.04 ns/op
Swapping the string comparison order (strs[i] == str ➔ str == strs[i]) results in ~4x performance improvement (61.63 ns/op → 16.04 ns/op) Why does operand ordering cause performance divergence when both implementations are logically equivalent?
Comment From: gabyhelp
Related Issues
- runtime: improve performance of == on arrays. #14302 (closed)
- bytes: Equal more expensive than string equality #31587 (closed)
(Emoji vote if this was helpful or unhelpful; more detailed feedback welcome in this discussion.)
Comment From: randall77
Hm, seems a lot like CL 485535 isn't triggering for some reason. Maybe there's something in the inlining process that trips up that CL's rules.
Comment From: apocelipes
I can reproduce this issue on Apple M4 with go 1.24.4:
$ go test -bench . -benchmem -count 10
goos: darwin
goarch: arm64
pkg: strtest
cpu: Apple M4
BenchmarkContainsStringB-10 97770924 12.12 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 100000000 12.15 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 99099842 12.12 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 100000000 12.16 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 95220146 12.15 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 100000000 12.22 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 99952105 12.19 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 100000000 12.21 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 100000000 12.24 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringB-10 99284324 12.20 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 40335907 29.86 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41011618 29.31 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41048912 29.43 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41670765 29.23 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 40361742 29.30 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41527760 29.39 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41797524 29.47 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41919382 29.49 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 42055520 29.41 ns/op 0 B/op 0 allocs/op
BenchmarkContainsStringA-10 41972167 29.35 ns/op 0 B/op 0 allocs/op
PASS
ok strtest 25.712s
Comment From: zhangguanzhang
$ go test -bench=.
goos: linux
goarch: amd64
pkg: test/gotest/test
cpu: Common KVM processor
BenchmarkContainsStringA-6 16278399 89.93 ns/op
BenchmarkContainsStringB-6 90614661 12.99 ns/op
PASS
ok test/gotest/test 2.735s
$ go version
go version go1.23.10 linux/amd64
$ uname -a
Linux guan 5.4.0-216-generic #236-Ubuntu SMP Fri Apr 11 19:53:21 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux
Comment From: TapirLiu
With for b.Loop(), it shows no performance differences.
The performance difference happened since Go toolchain 1.21. Before 1.21, the functions are on par.
Looks only impact []string, not other "[]T`.
Comment From: songokuwork
Go version
go 1.24.1 darwin/arm64 Apple M1
Summary
I'm working on a performance optimization in our business logic and noticed a significant performance difference when swapping the strings on either side of an equality operator. After simplifying the logic to a
containsfunction, I was able to reproduce the behavior. Below are the sample code and benchmarksSample Code
var containsSlice = func() []string { return []string{ "12312312",
"abcsdsfw", "abcdefgh", "qereqwre", "gwertdsg", "hellowod", "iamgroot", "theiswer", "dg323sdf", "gadsewwe", "g42dg4t3", "4hre2323", "23eg4325", "13234234", "32dfgsdg", "23fgre34", "43rerrer", "hh2s2443", "hhwesded", "1swdf23d", "gwcdrwer", "bfgwertd", "badgwe3g", "lhoejyop", } }()func containsStringA(strs []string, str string) bool { for i := range strs { if strs[i] == str { return true } } return false }
func containsStringB(strs []string, str string) bool { for i := range strs { if str == strs[i] { return true } } return false }
func BenchmarkContainsStringA(b *testing.B) { for n := 0; n <= b.N; n++ { containsStringA(containsSlice, "lhoejyop") } }
func BenchmarkContainsStringB(b *testing.B) { for n := 0; n <= b.N; n++ { containsStringB(containsSlice, "lhoejyop") } }
Benchmark Result
goos: darwin goarch: arm64 pkg: go-playground/simple cpu: Apple M1 BenchmarkContainsStringA-8 19314198 61.63 ns/op BenchmarkContainsStringB-8 72874310 16.04 ns/opSwapping the string comparison order (strs[i] == str ➔ str == strs[i]) results in ~4x performance improvement (61.63 ns/op → 16.04 ns/op) Why does operand ordering cause performance divergence when both implementations are logically equivalent?
so easy: if s is a value already loaded in a register -> The Go compiler (SSA backend) will ensure that s is loaded into a CPU register and does not need to be reloaded from RAM on each loop iteration. while ss[i] resides in a large array in RAM, then writing s == ss[i] might be slightly advantageous because s is already in the cache or a register, so the CPU only needs to load ss[i] for the comparison.
Conversely, if you write ss[i] == s, the CPU might prioritize loading ss[i] (which is in memory), and then retrieve s from the register afterward. Therefore, s == ss[i] is generally faster.
Comment From: apocelipes
Conversely, if you write ss[i] == s, the CPU might prioritize loading ss[i] (which is in memory), and then retrieve s from the register afterward.
Although I disagree with this point of view, if that is the case, it would indicate a bug in the compiler. You could provide the generated code (ASM) of two functions to support your point.
Comment From: songokuwork
Conversely, if you write ss[i] == s, the CPU might prioritize loading ss[i] (which is in memory), and then retrieve s from the register afterward.
Although I disagree with this point of view, if that is the case, it would indicate a bug in the compiler. You could provide the generated code (ASM) of two functions to support your point.
| Metric | containsStringA |
containsStringB |
Notes |
|---|---|---|---|
cycles |
79.6 billion | 73.0 billion | ✅ B is faster |
cache-references |
2,215,445 | 2,471,188 | ≈ Roughly equal |
cache-misses |
404,538 (18.26%) | 519,154 (21.01%) | 🔁 B slightly worse |
branches |
61.3 billion | 64.3 billion | ≈ Comparable |
branch-misses |
455.8 million (0.74%) | 243.8 million (0.38%) | ✅ B has fewer mispredictions |
time elapsed |
21.49s | 20.65s | ✅ B is ~4% faster |
Branch Misses -> This is the main reason containsStringB performs better. CPU branch predictors tend to work better when the left-hand side is a fixed value (like a local variable).
Comment From: randall77
To be clear, I know exactly what the problem is here. The string length is not getting constant-folded in some situations.
The generated code for comparing strings s and t does:
if s.len == t.len {
result = memequal(s.ptr, t.ptr, x)
} else {
result = false
}
The question is, what to use for x? Either s.len or t.len would be appropriate, as they are equal.
But the compiler has rules for doing memequal(?, ?, N) for compile-time constant N without a runtime call. So if s.len is a constant (because s is a constant) and t is not, then we want to use x = s.len. If it is the other way around, we want to use x = t.len. When the compiler gets that choice wrong, there is a memequal call when there need not be.
So the compiler needs to do a better job of picking x than CL 485535 does. Or, the compiler needs to understand that x is a constant even if it is a non-constant variable that is == to a constant.
I don't think this would be too hard to fix. There is some trickiness with phase ordering because we pick x pretty early in compilation, before we've constant-propagated everything.
Comment From: katsusan
Go version
go 1.24.1 darwin/arm64 Apple M1
Summary
I'm working on a performance optimization in our business logic and noticed a significant performance difference when swapping the strings on either side of an equality operator. After simplifying the logic to a
containsfunction, I was able to reproduce the behavior. Below are the sample code and benchmarksSample Code
var containsSlice = func() []string { return []string{ "12312312", "abcsdsfw", "abcdefgh", "qereqwre", "gwertdsg", "hellowod", "iamgroot", "theiswer", "dg323sdf", "gadsewwe", "g42dg4t3", "4hre2323", "23eg4325", "13234234", "32dfgsdg", "23fgre34", "43rerrer", "hh2s2443", "hhwesded", "1swdf23d", "gwcdrwer", "bfgwertd", "badgwe3g", "lhoejyop", } }() func containsStringA(strs []string, str string) bool { for i := range strs { if strs[i] == str { return true } } return false } func containsStringB(strs []string, str string) bool { for i := range strs { if str == strs[i] { return true } } return false } func BenchmarkContainsStringA(b testing.B) { for n := 0; n <= b.N; n++ { containsStringA(containsSlice, "lhoejyop") } } func BenchmarkContainsStringB(b testing.B) { for n := 0; n <= b.N; n++ { containsStringB(containsSlice, "lhoejyop") } }
Benchmark Result
goos: darwin goarch: arm64 pkg: go-playground/simple cpu: Apple M1 BenchmarkContainsStringA-8 19314198 61.63 ns/op BenchmarkContainsStringB-8 72874310 16.04 ns/opSwapping the string comparison order (strs[i] == str ➔ str == strs[i]) results in ~4x performance improvement (61.63 ns/op → 16.04 ns/op) Why does operand ordering cause performance divergence when both implementations are logically equivalent?
so easy: if s is a value already loaded in a register -> The Go compiler (SSA backend) will ensure that s is loaded into a CPU register and does not need to be reloaded from RAM on each loop iteration. while ss[i] resides in a large array in RAM, then writing s == ss[i] might be slightly advantageous because s is already in the cache or a register, so the CPU only needs to load ss[i] for the comparison.
Conversely, if you write ss[i] == s, the CPU might prioritize loading ss[i] (which is in memory), and then retrieve s from the register afterward. Therefore, s == ss[i] is generally faster.
That's not the case, usually in benchmark's busy loop cases, all data are ready on L1d cache, or even load buffer can fit them on modern micrprocessors.
When it comes to this issue, as randall77 said, compiler will apply some optimization to these special rules, Eg, for comparing with 8Byte string constant, compiler will convert it to a int64 and make it into a int64 vs int64 comparion.That's where the 8101827752538105964 comes from in the assembly code.("lhoejyop"=0x706f796a656f686c=8101827752538105964)
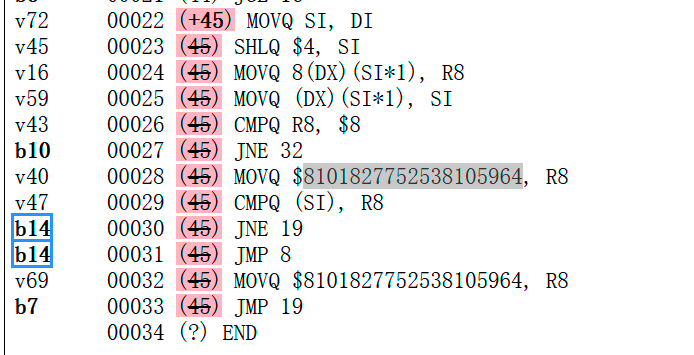
Generally, the perf difference between containsStringA and containsStringB becomes the performance
gap between a call to runtime.memequal and a simple CMPQ instruction, in which the latter obviously wins.
Comment From: gopherbot
Change https://go.dev/cl/686195 mentions this issue: cmd/compile: try harder to find constant string during comparison
Comment From: Jashanpreet2
To be clear, I know exactly what the problem is here. The string length is not getting constant-folded in some situations.
The generated code for comparing strings
sandtdoes:
if s.len == t.len { result = memequal(s.ptr, t.ptr, x) } else { result = false }The question is, what to use for
x? Eithers.lenort.lenwould be appropriate, as they are equal.But the compiler has rules for doing
memequal(?, ?, N)for compile-time constantNwithout a runtime call. So ifs.lenis a constant (becausesis a constant) andtis not, then we want to usex = s.len. If it is the other way around, we want to usex = t.len. When the compiler gets that choice wrong, there is amemequalcall when there need not be.So the compiler needs to do a better job of picking
xthan CL 485535 does. Or, the compiler needs to understand thatxis a constant even if it is a non-constant variable that is==to a constant.I don't think this would be too hard to fix. There is some trickiness with phase ordering because we pick
xpretty early in compilation, before we've constant-propagated everything.
Where would the updates need to be made to fix this?
Comment From: randall77
A fix is already written in CL 686195.