Description:
This proposal aims to enhance the Go standard library’s math ( math/stats.go )package by introducing several essential statistical functions. The proposed functions are:
- Mean: Calculates the average value of a data set.
- Median: Determines the middle value when the data set is sorted.
- Mode: Identifies the most frequently occurring value in a data set.
- Variance: Measures the spread of the data set from the mean.
- StdDev: Computes the standard deviation, providing a measure of data dispersion. and many more....
Motivation:
The inclusion of these statistical functions directly in the math package will offer Go developers robust tools for data analysis and statistical computation, enhancing the language's utility in scientific and financial applications. Currently, developers often rely on external libraries for these calculations, which adds dependencies and potential inconsistencies. Integrating these functions into the standard library will:
- Provide Comprehensive Statistical Analysis: These functions will facilitate fundamental statistical measures, aiding in more thorough data analysis and better understanding of data distributions.
- Ensure Reliable Behavior: Functions are designed to handle edge cases, such as empty slices, to maintain predictable and accurate results.
- Optimize Performance and Accuracy: Implemented with efficient algorithms to balance performance with calculation accuracy.
- Increase Utility: Reduces the need for third-party libraries, making statistical computation more accessible and consistent within the Go ecosystem.
Design:
The functions will be added to the existing math package, ensuring they are easy to use and integrate seamlessly with other mathematical operations. Detailed documentation and examples will be provided to illustrate their usage and edge case handling.
Examples:
- Mean:
go mean := math.Mean([]float64{1, 2, 3, 4, 5}) - Median:
go median := math.Median([]float64{1, 3, 3, 6, 7, 8, 9}) - Mode:
go mode := math.Mode([]float64{1, 2, 2, 3, 4}) - Variance:
go variance := math.Variance([]float64{1, 2, 3, 4, 5}) - StdDev:
go stddev := math.StdDev([]float64{1, 2, 3, 4, 5})
@gabyhelp's overview of this issue: https://github.com/golang/go/issues/69264#issuecomment-2593973713
Comment From: gabyhelp
Related Issues and Documentation
(Emoji vote if this was helpful or unhelpful; more detailed feedback welcome in this discussion.)
Comment From: ianlancetaylor
In general the math package aims to provide the functions that are in the C++ standard library <math>.
Comment From: hemanth0525
Thanks for the feedback! I get that the math package is meant to mirror the functions in C++'s <cmath>, but I think adding some built-in stats functions could be a nice improvement. A lot of developers deal with stats regularly, so having these in the standard library could make things easier without stepping too far from the package’s core purpose. Happy to chat more about it if needed!
Comment From: earthboundkid
Can you do some detective work to see how people are dealing with this in open source Go now? Is there some go-stats package that has a million stars on Github? Are there ten libraries that are each imported five hundred times? Seeing that something has big demand already is important for bringing something that could be in a third party library into the standard library. Otherwise this will just get closed with "write a third party library." Which has certainly happened to me more than once!
Comment From: hemanth0525
I’ve done some digging into how statistical functions are currently being handled in the Go community. While libraries like Gonum and others provide statistical methods, there's no single source of truth or dominant package in this space, and many are designed for more complex or specialized tasks. However, the basic statistical functions we're proposing—like Mean, Median, Mode, Variance, and StdDev—are foundational for a wide range of applications, from simple data analysis to more advanced scientific and financial computations.
By integrating these into the standard library, we'd eliminate the need for external dependencies for basic tasks, which is in line with Go's philosophy of having a strong standard library for common use cases. While third-party packages are an option, including these functions in the math package would make Go more self-sufficient for everyday statistical needs, benefiting developers who want a simple, reliable way to compute these without resorting to third-party solutions.
Comment From: seankhliao
for common use cases
this is the part where we need to see evidence. especially considering the existence of libraries like gonum, how often does the need arise for functions like those proposed where you wouldn't need the extra functionality that other libraries provide.
Comment From: jimmyfrasche
For what it's worth, python has a statistics package in its standard library: https://docs.python.org/3/library/statistics.html
It would be nice to have a simple package everyone agrees on for common use cases, but that doesn't necessarily need to be in std.
Comment From: randall77
These functions sound pretty simple, but I think there's actually a lot of subtlety here. For instance, what does Mean do for rounding? Do we need to use Kahan's algorithm? What if the sum at some point rounds up to +Inf?
Comment From: doggedOwl
Can you do some detective work to see how people are dealing with this in open source Go now? Is there some go-stats package that has a million stars on Github? Are there ten libraries that are each imported five hundred times? Seeing that something has big demand already is important for bringing something that could be in a third party library into the standard library. Otherwise this will just get closed with "write a third party library." Which has certainly happened to me more than once
in my experience everytime some numeric problems comes up gonum lib is suggested. they have a stats package https://pkg.go.dev/gonum.org/v1/gonum@v0.15.1/stat
Comment From: hemanth0525
Can you do some detective work to see how people are dealing with this in open source Go now? Is there some go-stats package that has a million stars on Github? Are there ten libraries that are each imported five hundred times? Seeing that something has big demand already is important for bringing something that could be in a third party library into the standard library. Otherwise this will just get closed with "write a third party library." Which has certainly happened to me more than once
in my experience everytime some numeric problems comes up gonum lib is suggested. they have a stats package https://pkg.go.dev/gonum.org/v1/gonum@v0.15.1/stat
Yeah, so think about having it's functionalities in go std lib straight away !
Comment From: hemanth0525
Gonum library is indeed often suggested for statistical and numerical work in Go, and it has a dedicated stat package. It’s a robust library that covers a wide range of statistical functions, and for more complex needs, it's definitely a go-to solution.
However, my proposal is focused on adding foundational statistical functions like Mean, Median, Mode, Variance, and StdDev,... directly into the standard library. These are basic but essential tools that many developers need in day-to-day tasks, and having them in the standard library could save developers from importing an entire external library like Gonum for simple calculations. I believe integrating these functions would make Go more self-sufficient, particularly for developers who need straightforward statistical calculations without additional dependencies.
Comment From: adonovan
IMHO these functions would be very useful in the standard library, even if (or indeed, because) the implementation requires some care. There are many "quick" uses of these basic stats operations in testing, benchmarking, and writing CL descriptions that shouldn't require a heavyweight dependency on a fully-featured third-party stats library. (I often end up moving data out of my Go program to the shell and running the github.com/nferraz/st command.)
Another function I would like is Percentile(n, series), which reports the nth percentile value of a given series.
Comment From: jimmyfrasche
If it belongs in std, it should probably be in a "math/stats" or "math/statistics" instead of directly in "math".
Comment From: meling
Here is a small experience report with existing stats packages: In some code I was using gonum’s stats package, and a collaborator started using github.com/montanaflynn/stats as well, whose API returns an error (which I felt was annoying.) Luckily, I caught the unnecessary dependency in code review.
These are the types of things that can easily cause unnecessary dependencies to get added in projects. Hence, I think adding common statistics functions would be a great addition to the std.
Comment From: hemanth0525
It seems like a lot of developers will benefit from this !!
Comment From: hemanth0525
Can I know the update on this proposal ??_
Comment From: adonovan
The proposal review committee will likely look at it this week. It usually takes a few rounds to reach a final decision.
Comment From: hemanth0525
The proposal review committee will likely look at it this week. It usually takes a few rounds to reach a final decision.
OK, Cool !
Comment From: hemanth0525
Can I know the update on this proposal please ?
Comment From: adonovan
Sorry, we didn't get to it last week, but perhaps will this week.
Comment From: hemanth0525
Yes Please....
Comment From: adonovan
Some of the questions raised in the meeting were:
- Which package should this live in? The scope of the math package aligns with the C++ math package, so it does not seem the appropriate home. Perhaps math/stats? But this might create a temptation to add a lot more statistical functions. Which leads to:
- If we create a new package, what should be its scope? The proposed set of functions (including Percentile) is roughly the set of statistical functions that every high-school student knows, and perhaps that's the appropriate scope.
- Should the functions be generic? Should we support the median of an integer series, say? Personally I'm not convinced it's necessary; users can convert integers to floats as needed. This package should make common problems (such as arise during testing and benchmarking) convenient, not aim for maximum generality or efficiency.
- Is a single result sufficient for the Mode function? What is the mode of [1, 2]?
Comment From: hemanth0525
Thanks for the feedback! I totally get the concerns and here’s my take:
-
Package Location: I agree that a new
math/statspackage makes sense. It keeps things organized and prevents the coremathpackage from becoming too broad. We can start with the basics—mean, median, mode, variance, etc.—covering foundational stats functions that are universally useful. -
Scope: Let’s keep it simple for now. The goal should be to provide common, practical functions that people need for everyday testing, benchmarking, and basic analytics. We don’t need to cover advanced statistical methods yet—just the essentials. And yeah !, potential addons would be
[ Percentile, Quartiles, Geometric Mean, Harmonic Mean, Mean Absolute Deviation (MAD), Coefficient of Variation (CV), Cumulative Sum (Cumsum), Root Mean Square (RMS), Skewness, Kurtosis, Covariance, Correlation Coefficient, Z-Score, ..... ] -
Generics: I don’t think we need generics here. Users can convert integers to floats if needed, and keeping it focused on simplicity will make the package more accessible.
-
Mode Function: For cases like
[1, 2], we can returnnilor an empty slice[]if no mode exists, or return all modes in a slice when there’s more than one. That way, it’s clear and flexible.
Overall, I think this keeps the package lightweight, practical, and easy to use, which should be the priority. Looking forward to hearing your thoughts!
Comment From: adonovan
And yeah potential addons would be Percentile, ...[long list]...
I think the goal of limiting the scope would be to ensure that these (other than Percentile) are not potential additions. ;-)
I agree that a slice result for Mode seems appropriate. Perhaps it should be called Modes.
Comment From: hemanth0525
Yeah gotcha !!
Totally agree..
Comment From: jimmyfrasche
The python lib has a good scope set in its description (essentially "what you'd find on a calculator")
Comment From: ianlancetaylor
I think the main goal of making these functions generic would be to support either float32 or float64.
Comment From: doggedOwl
I don't see a reason for these to not be generic. accepting a slice of Integers does not bring complexity in the implementation and it would be a pity that even now we would need to convert manually when these are naturally functions over numeric values.
For example many surveys would naturally have integer slice values. depending on the size of the input it could be a significant allocation factor. Speaking of allocation, would it be useful to also have a *Iter variant of the methods that takes an Iterator instead of slices?
Comment From: aclements
This proposal has been added to the active column of the proposals project and will now be reviewed at the weekly proposal review meetings.
Comment From: hemanth0525
I'm working on this. Could you please assign it to me ??
Comment From: gophun
@hemanth0525 It doesn't make much sense to work on something that isn't yet accepted by the proposal process.
Comment From: hemanth0525
@hemanth0525 It doesn't make much sense to work on something that isn't yet accepted by the proposal process.
Initially, I created a pull request without realizing that Go follows a formal proposal process. Afterward, I submitted the required proposal.
Comment From: gophun
@hemanth0525
Yes, see https://github.com/golang/proposal. This proposal is now in the 'Active' state, meaning it receives a few minutes of consideration by the review group every week (typically on Wednesdays if I recall correctly). It can take anywhere from several weeks to months before a final decision is made.
If you'd like to do something, you can update the initial proposal by adding the proposed function signatures (without implementation) along with their doc comments to reflect the current state of the discussion. For an example, see https://github.com/golang/go/issues/45955#issue-875940635
Comment From: hemanth0525
@gophun Yeah I understand thank you !
Comment From: jdemeyer
accepting a slice of Integers does not bring complexity in the implementation
What's the mean of []int{2, 3} then? The integer 2 (when naively computing (2 + 3)/2 as int) or float64(2.5)? Always returning float64 doesn't sound right either, as you want to return float32 if the input is []float32.
Comment From: tianon
That's just a more obvious form of the same problem at the bounds of float precision, right?
Comment From: jdemeyer
+1 to Percentile as that's less obvious to implement correctly, but actually useful. And you could implement Median as just calling Percentile(x, 0.5).
Comment From: aclements
Percentile is tempting, but not nearly as universally agreed upon as these other operations. There's a standard taxonomy of nine different definitions of percentile/quantile. Maybe there's value in being opinionated here, or maybe it's an attractive nuisance.
Comment From: hemanth0525
Can I know the status ??
Comment From: adonovan
Can I know the status ??
This is the status:
It can take anywhere from several weeks to months before a final decision is made.
Comment From: hemanth0525
Can I receive any updates, at least weekly?
Comment From: ianlancetaylor
@hemanth0525 I appreciate this issue is important to you. Please understand that we have over 700 proposals waiting for attention, as can be seen at https://github.com/orgs/golang/projects/17. It's not feasible for our small team to provide weekly updates for each separate proposal. You can track the proposal review activities at #33502.
Comment From: hemanth0525
@ianlancetaylor Yes I get it, Thanks !!
Comment From: aclements
What's the scope?
The scope of this package should be fairly narrow. If you search for "basic descriptive statistics", basically all results include mean, median, mode, and standard deviation. Variance is also common. "Range" is pretty common, but that's easy to get with the min and max built-ins. Most include some form of quantile/percentile/quartile.
The Python statistics package is an interesting example here (thanks @jimmyfrasche), as it aims to be a small collection of common operations. However, I think it actually goes too far. I was particularly surprised to see kernel density estimation in there, as I consider that, and especially picking good KDE parameters, a fairly advanced statistical method.
Which package?
math/stats could invite feature creep. On the other hand, it's scoped and purposeful. It's also easier to search for.
math currently follows the C library, but I'm not convinced that's very important (Go isn't C). However, everything in math operates on one or two float64s, so this would be a break from that. math already mixes together a few different fields (e.g., there's no math/trig), but that's probably just because it follows the C math library. It already had a few other sub-packages for different data types (math/cmplx) and specific fields (math/bits).
Overall I'm leaning toward math/stats.
Operations
Quantile: I personally find myself wanting quantiles quite often, so this is certainly tempting. We should get a statistics expert to weigh in on which definition to use. I do think this should be "quantile" and not "percentile".
Variance and standard deviation: Are these for populations or do they apply sample correction? Do we provide both a population form and a sample-corrected form (this is what Python does)? If we're going to provide sample forms, which of the various corrections do we use?
Mode: I'm not completely convinced that we should include mode. If we do, I'd suggest only including "multimode", which returns a possibly-nil slice, as this is a total function, unlike mode.
Comment From: adonovan
Quantile: I personally find myself wanting quantiles quite often, so this is certainly tempting. We should get a statistics expert to weigh in on which definition to use. I do think this should be "quantile" and not "percentile".
Meaning the parameter should be in [0,1] not [0,100]? Or that one should provide lower and upper bounds for the portion of the CDF of interest?
Variance and standard deviation: Are these for populations or do they apply sample correction? Do we provide both a population form and a sample-corrected form (this is what Python does)? If we're going to provide sample forms, which of the various corrections do we use?
I would think that population is more in line with the typical use of such a package, but it may be safer to provide both with distinct names, preventing casual use of the wrong one. The doc comments should provide clear examples of which one is appropriate.
Mode: I'm not completely convinced that we should include mode. If we do, I'd suggest only including "multimode", which returns a possibly-nil slice, as this is a total function, unlike mode.
I agree; I proposed Modes([]float) []float to acknowledge its multiplicity up front.
Comment From: seehuhn
About the different ways to compute quantiles: R, which is very mainstream in statistics, implements 9 different quantile algorithms and lets the user choose. Documentation is at https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/quantile . (I didn't check whether this is the same list of methods as in the Wikipedia article quoted above.)
Comment From: Merovius
I'm not sure about the proposed API. Specifically, it seems to me that these should arguably take iter.Seq[float64] instead of []float64, from a pure API perspective. But if you need more than one of these outputs (which I would assume you commonly do), iter.Seq makes it clear that it's less efficient to iterate multiple times. Instead of having a single loop that does a bunch of accumulations. The same concern ultimately exists with slices, it's just less obvious.
So to me, this API only really makes sense for small data series. Where the cost of looping multiple times is negligible and/or you are fine with pre-allocating them. An API to remedy that is arguably too complex for the stdlib.
Are we okay with that limitation? If so, should we still make the arguments iter.Seq?
Comment From: jimmyfrasche
Another design would a single value with methods for all the various stats and whose factories take the slice or sequence (and any weights). That way it could do any sorting or failing on NaN upfront and cache any intermediate values required by multiple stats.
Something like
stats, err := statistics.For(floats)
// handle err
fmt.Println(stats.Mean(), stats.Max(), stats.Median())
Comment From: adonovan
Are we okay with that limitation [that the cost of looping multiple times is negligible and/or you are fine with pre-allocating them]? If so, should we still make the arguments
iter.Seq?
Though an iter.Seq[float64] is the logical parameter type, I suspect it is not only less efficient (because of repeated passes) but also less convenient (because typically one has a slice already). Although an iterator would allow the caller to avoid materializing an array of float64 when they have some other data structure (such as an array of integers or structs), I suspect the work to define a one-off iterator over that data structure is probably still more than to create a []float64 slice from it. So, []float64 is probably more convenient. And as you point out, if multiple statistics are required, it may be more efficient too, but that's a secondary concern.
Another design would a single value with methods for all the various stats
There's a tantalizing idea here that perhaps one could just call fmt.Println(stats.For(series)) and obtain a nice string showing the mean, median, percentiles and so on, not unlike the convenience of fmt.Println(time.Since(t0)). But the Percentile operator requires an argument (0.9. 0.99, etc). I think the API originally proposed is simpler.
Comment From: jimmyfrasche
@adonovan it could not print percentiles or just print quartiles and you have to ask if you need something more specific.
My main thought with the API is that it makes it clear that it's taking ownership. I'm guessing in most cases you want more than one stat at a time so if it can cache some intermediary value that gets used for more than one stat or speed things up by storing the numbers in a special order or data structure that's a nice bonus. I don't know what the specific numerical methods are used for stats but I imagine there could be some savings by caching the sum or just knowing if there's a +Inf in there somewhere.
Comment From: Merovius
@adonovan
And as you point out, if multiple statistics are required, it may be more efficient too, but that's a secondary concern.
To be clear: That is the opposite of what I was trying to point out :) It requires multiple passes to calculate both the Mean and the Stddev with the proposed API. Regardless of whether they are given as an iter.Seq or as a []float64. If you don't use the API, you can do it in one pass.
And the promise has been, that range over slices.Values(s) is just as fast as over []float64 directly, FWIW. So it is not less efficient, in the special case that you already have a []float64.
Comment From: adonovan
To be clear: That is the opposite of what I was trying to point out :)
Sorry, long day, tired brain.
I don't really have a strong feeling about iterator vs slice. My initial feeling was that the slice was simpler, but perhaps we should embrace iterators so that all sequences can be supplied with equal convenience.
It requires multiple passes to calculate both the Mean and the Stddev with the proposed API.
That's true, but the point I was trying to make was that we are unlikely to be able to correctly anticipate the exact set of operations that we should compute in a single pass. Should it be mean, median, and 90% percentile? What about 95% or 99%? And so on.
So, I argue for separate operators, each taking an iter.Seq[float64].
Comment From: apparentlymart
It seems to me that this discussion about using iterators and collecting multiple results in a single pass is circling around the idea of a generic fold/reduce mechanism over iterators, with the statistics operations discussed here being a set of predefined combining functions to use with that mechanism.
Someone who wants to compute multiple at once could then presumably write their own combining function that wraps multiple others and produces a struct or map type (with one field/element per inner function) as its result.
I will say immediately that I'm not super convinced that such complexity is justified, but if we think that combining multiple operations over a single iterator is something we want to support then I'd wonder what that would look like as a more general facility implemented in package iter, or similar.
EDIT: After posting this I immediately found https://github.com/golang/go/issues/61898 which proposes to add Reduce and Reduce2 helpers to a new experimental package. Would it be possible to implement some or all of these statistical operators as functions that could be passed to xiter.Reduce?
Comment From: adonovan
I will say immediately that I'm not super convinced that such complexity is justified.
I am glad that you said that immediately. ;-)
I immediately found #61898 which proposes to add
ReduceandReduce2helpers to a new experimental package. Would it be possible to implement some or all of these statistical operators as functions that could be passed toxiter.Reduce?
This reminds me of a certain Google interview question from years back: how do you estimate the median value of a long stream with only finite working store?
Any loop over a sequence can be expressed as a wrapper around a call to Reduce, but it is often neither clearer nor more efficient to do so. We absolutely should not require users of the new stats package to hold such higher-order concepts in mind.
Comment From: apparentlymart
I should've said that my main intention in my earlier comment was to respond to the ideas around calculating multiple of these functions at the same time over a given sequence, not to the original proposal for separate functions.
Concretely what I was thinking about was:
- Expose each of these functions as something that can be passed to a "reduce" function.
- For each of them, also offer a simpler wrapper like in the original proposal that is designed for the simple case of calculating only one function for a given sequence, wrapping a call to the "reduce" function.
- Anyone who wants to, for example, calculate both mean and standard deviation at the same time would do that by directly calling "reduce" with a function that wraps both the mean and standard deviation functions and returns something like struct { Mean, StdDev float64 } with the results of both functions.
I intend the last item here to be an alternative to offering in this package any specialized API for calculating multiple aggregates together. In particular, an alternative to the statistics.For and others like it.
I'm proposing this only if there's consensus that supporting the use of multiple functions over a single sequence in only one pass is a requirement. If we can convince ourselves that it isn't a requirement then I don't think this complexity is justified. I expect that the original proposal's functions, potentially but not necessarily recast as taking iter.Seq instead, should be sufficient at least in the common case.
Comment From: jimmyfrasche
To clarify, statistics.For would not (necessarily) calculate any statistics upfront it would just prepare and store all the information needed to calculate the values.
Methods could cache any intermediary calculations that other stats may need so they don't need to be computed twice if you need two stats that depend on the same value.
If, as part of storing and preparing the info, it could easily calculate and cache a few basic stats while it's at it, that's certainly a nice bonus—but that would be an implementation detail.
Whether that makes sense in some part depends on what operations there will be (now and in the future), the methods for calculating them, and how many calculations can be shared between them. Though it could have multiple factories, one for slice and one for iter so you could work easily with either without having to have a seq and slice version of each operation.
Comment From: adonovan
I'm proposing this only if there's consensus that supporting the use of multiple functions over a single sequence in only one pass is a requirement.
I firmly believe it should not be a requirement and that such complexity is unwarranted. The goal for this package is to provide simple implementations of the most well known of all statistical functions. I imagine a typical usage will be to print a summary of results in a benchmarking scenario. The cost of computing the statistics will be insignificant.
Comment From: CAFxX
Quantile: I personally find myself wanting quantiles quite often, so this is certainly tempting. We should get a statistics expert to weigh in on which definition to use. I do think this should be "quantile" and not "percentile".
I would recommend, if we include quantile, to do what both Python and R do, and accept a list of quantiles to be computed. I admit this is purely anecdotal, but I can't really recall a situation in which I had to compute a single quantile.
Comment From: aclements
I think these should all take slices. Slices are faster and simpler. Just because we have iterators doesn't mean we should stop using slices in APIs: slices should still be the default, unless there's a good justification for using an iterator. In this case, if people have enough data that they must stream it, they should probably be using something more specialized.
Meaning the parameter should be in [0,1] not [0,100]?
Right.
I would recommend, if we include quantile, to do what both Python and R do, and accept a list of quantiles to be computed.
I agree.
Let's leave Mode/Modes out for now. Especially on floating point numbers, these seem like asking for trouble given how easy it is to wind up with nearly equal floating point numbers. We could consider mode over integers, but then it doesn't fit as well into the rest of the API. It's a new package, so let's start with a narrow scope.
It seems like, if we're going to have standard deviation and variance, that we need both population and sample version. gonum.org/v1/gonum/stat calls these StdDev, PopStdDev, Variance, and PopVariance. I'm inclined to be more explicit and put Sample in the names of the sample versions. We could also provide just one or the other of standard deviation and variance, since one can trivially be computed from the other, but I suspect it's common enough that people look for one or the other that we might as well provide the convenience of both.
It would be nice to have a stats expert weigh in on including both population and sample variance, and the question of which quantile definition to use. @adonovan is going to see about getting input from a stats expert, but any other experts should feel free to weigh in.
So, I believe that leaves us at the following API for package math/stats:
func Mean(x []float64) float64
func Median(x []float64) float64
func Quantiles(x []float64, quantiles []float64) []float64
func SampleStdDev(x []float64) float64
func SampleVariance(x []float64) float64
func PopulationStdDev(x []float64) float64
func PopulationVariance(x []float64) float64
This leaves some open questions:
- What should these functions do when given an empty slice? As @meling pointed out, adding an error result would be pretty inconvenient. Other reasonable options are to return NaN or to panic. I'm slightly inclined toward panicking because of the way NaNs infect other operations and because I think NaN should be used to indicate there was a NaN in the argument.
- What should these functions do when the slice contains NaN, Inf, or -Inf? I think if there's any NaN, the result should be NaN (this is another reason for not returning NaN if the slice is empty). For Median and Quantiles, Inf, and -Inf should be sorted accordingly as samples. For Mean, if the input contains both Inf and -Inf, the result should be NaN; if it contains just one of the two, the result should be Inf or -Inf, respectively. And for StdDev and Variance, if the input contains either Inf or -Inf, the result should be Inf.
Comment From: jimmyfrasche
If we've settled on slices then back to an earlier question, should they be generic like
func Mean[Slice ~[]E, E ~float32 | ~float64](x Slice) E
or at least
func Mean[Slice ~[]E, E ~float64](x Slice) E
?
Also, could the quantiles param of Quantiles be ...float64 with a reasonable default if left off?
Comment From: rsc
We should not use generics; package math is float64-only. @adonovan is still trying to find out what specific algorithms we should be using.
Comment From: jimmyfrasche
Would package math be float64-only if it were designed today? It's entirely reasonable either way, imo.
However, I'd hope math/bits would use generics if designed today (or v2'd).
If I had a slice of type Temp float64 I'd hate to have to make a copy to get the mean temperature, so package slices seems as appropriate a precedence as package math here.
Comment From: glycerine
Two comments:
1) To provide better guidance for statistically naive users, I would suggest omitting the PopulationStdDev and PopulationVariance functions.
The only time the difference between population and sample standard deviation matters is when the sample size is very small and then you should be using the SampleStdDev and SampleVariance anyway.
R, for example, always divides by (n-1) for both its base library var() and sd() functions (Variance and standard deviation, respectively).
2) Like one commenter above, I'm also bothered by the suggested API forcing two passes through the data when only one will do. It seems a poor example to provide an API which forces algorithmic inefficiency in the standard library.
If one is computing the standard deviation, almost always one also wants the mean too. It makes me cringe to think I'd have to do two passes to get both; so much so that I would avoid using the standard library functions if it forced this.
In place of SampleStdDev() and SampleVariance() (the later seems redundant) I would just have a single MeanSd() func that returns both mean and sample standard deviation from a single pass. For example:
// MeanSd returns the mean and sample standard
// deviation from a single pass through the observations in x.
func MeanSd(x []float64) (mean, stddev float64)
I've provided a simple one-pass implementation of this here: https://github.com/glycerine/stats-go
Comment From: glycerine
For quantile computation, it is hard to provide an efficient, exact, online implementation, in the sense that exact computation usually requires using/storing all the data.
Almost always you need an online algorithm for your statistics to avoid O(n^2) of updates, since you are typically reporting statistics regularly. An approximation or estimate of the quantiles is also usually sufficient.
Therefore, most users are going to be better off using an online T-digest implementation like https://github.com/caio/go-tdigest with, for example, a compress setting of 100 (which gives 1000x space reduction). Although this is an approximation of the quantiles, the tail accuracy is still very good, and the space savings makes it very worth while.
Unless someone has a better algorithm or a clever way to get the exact quantiles without needing to retain all the data over time, I would recommend leaving the Quantile() function out of the standard library and pointing people at a T-digest implementation instead.
Or the standard library could bring in and polish one of the T-digest implementations for Quantile and CDF (cumulative distribution function) computation. That would also be nice.
Comment From: aclements
Thanks for weighing in, @glycerine !
The only time the difference between population and sample standard deviation matters is when the sample size is very small and then you should be using the SampleStdDev and SampleVariance anyway.
...
If one is computing the standard deviation, almost always one also wants the mean too. It makes me cringe to think I'd have to do two passes to get both; so much so that I would avoid using the standard library functions if it forced this.
Thanks! This all makes sense and certainly simplifies things.
So instead of
func SampleStdDev(x []float64) float64
func SampleVariance(x []float64) float64
func PopulationStdDev(x []float64) float64
func PopulationVariance(x []float64) float64
we'd have just
func MeanAndStdDev(x []float64) (mean, stddev float64)
For quantile computation, it is hard to provide an efficient, exact, online implementation, in the sense that exact computation usually requires using/storing all the data.
...
Or the standard library could bring in and polish one of the T-digest implementations for Quantile and CDF (cumulative distribution function) computation. That would also be nice.
My sense is that T-digests would be beyond the scope of a small descriptive stats standard package. We're not trying to replace serious stats packages, just cover really common needs. T-digests are great if you need online quantiles, but have their own cognitive overheads, especially around understanding how they're approximating.
My sense is that the common need is that you have a simple slice of data and just want to get a few quantiles. That's certainly been true in my code.
I'm also not overly concerned with the performance of these functions. It just has to be "good enough." That's why we're thinking Quantiles would accept a slice of quantiles to compute because that generally allows for a lot of work sharing, and balances that with a simple API. (Side note: we could balance the performance needs a little more here by saying that Quantiles will be faster if you pass it sorted data, but that's not required.)
Comment From: arnehormann
Please consider a struct for the api. Also, you could use an online variant like in https://www.johndcook.com/skewness_kurtosis.html I strongly suspect it has sign errors in the +operator implementation for skewness and kurtosis and it could use min and max, otherwise it's great. Primary sources are referenced in the linked article.
Comment From: tmaxmax
As a data point, at work we've created some StdDev, Mean and Median helpers for some OCR code. Something interesting is that in every place we use StdDev we also use Mean, which is inefficient and redundant. I'd be in favour for a MeanStdDev function, should these statistics functions be introduced.
Comment From: aclements
Please consider a struct for the api.
We've discussed this above and it doesn't seem like the right trade-off for a simple descriptive stats API.
Also, you could use an online variant like in https://www.johndcook.com/skewness_kurtosis.html
Again, it's not clear this is justified in this case. For more advanced stats needs, such as online computation, it's easy enough to pull in an external, more specialized package.
Comment From: aclements
If I had a slice of type Temp float64 I'd hate to have to make a copy to get the mean temperature, so package slices seems as appropriate a precedence as package math here.
@jimmyfrasche , I feel your pain here. I've run into this exact problem. However, I think it's rare enough that we shouldn't complicate this API for it. @adonovan and I just discussed that it would be worth considering a small language change to allow explicit []T -> []U conversion if T and U have the same underlying type, just like we currently allow *T -> *U. We may write up a proposal for this. (And yes this would go against and entry in the Go FAQ, but it wouldn't be the first time. :smile: This was also brought up in #29864, but dismissed as "See the FAQ.")
Also, could the quantiles param of Quantiles be ...float64 with a reasonable default if left off?
I like the idea of a ... argument. Often the quantiles you want are known at compile time, so it's more convenient to just list them as parameters.
Comment From: aclements
I believe the current proposed API for package math/stats is:
// Mean returns the arithmetic mean of the values in x.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean(x []float64) float64
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev(x []float64) (mean, stddev float64)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median(x []float64) float64
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
//
// TODO: Which quantile algorithm should we use?
// TODO: How should we treat quantiles < 0 or > 1?
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Quantiles(x []float64, quantiles... float64) []float64
There are two open questions on Quantiles, which I marked as TODO above.
Comment From: randall77
I think we do need some doc about accuracy and overflow.
For example, what does Mean([]float{1e308,1e308}) return?
Mean([]float64{1, 1e-16, 1e-16, 1e-16, 1e-16}) vs Mean([]float64{1e-16, 1e-16, 1e-16, 1e-16, 1})?
Maybe we say the result is exactly (x[0]+x[1]+...+x[n-1])/n, evaluated in normal Go precedence order.
Comment From: earthboundkid
Maybe we say the result is exactly
(x[0]+x[1]+...+x[n-1])/n, evaluated in normal Go precedence order.
This should be defined one way or another, but my preference would be to do Kahan summation.
Comment From: aclements
@adonovan and I just discussed that it would be worth considering a small language change to allow explicit []T -> []U conversion if T and U have the same underlying type, just like we currently allow T -> U. We may write up a proposal for this.
Done. See #71183
Comment From: aclements
I think we do need some doc about accuracy and overflow.
I agree with this in principle, but I don't want to lock us in to a particular algorithm when there could be higher-accuracy algorithms with good performance. Even Kahan summation isn't the state of the art here, from what I understand, and summation is only part of the accuracy story. To me, the point of pulling these functions into the standard library is to provide a reasonable default when people don't want to worry about the details. People can always reach for more specialized implementations.
Looking to other languages, Python's sum function only says "Changed in version 3.12: Summation of floats switched to an algorithm that gives higher accuracy and better commutativity on most builds." Julia apparently uses pairwise summation for accuracy (which we could do, too), but does not appear to document anything about accuracy in the API.
Comment From: aclements
I could see a blanket statement in the package documentation like "These functions aim to balance performance and accuracy, but some amount of error is inevitable in floating-point computations. The underlying implementations may change, resulting in small changes in their results from version to version. If the caller needs particular guarantees on accuracy and overflow behavior or version stability, they should use a more specialized implementation."
Comment From: earthboundkid
This suggest a math.Equal(a, b, ε float64) bool function that says whether a and b are within ε of each other. It could be an independent proposal.
Comment From: gabyhelp
Original Post Summary
This proposal suggests adding several fundamental statistical functions to Go's standard library math package (specifically, to math/stats.go). These functions include: Mean, Median, Mode, Variance, and StdDev, with the possibility of more in the future. (issue)
The motivation behind this proposal is to provide Go developers with readily available tools for statistical analysis within the standard library, reducing reliance on external dependencies. The author argues this addition would lead to more comprehensive statistical analysis, reliable behavior, optimized performance, and increased utility within the Go ecosystem. (issue)
The proposed design involves adding these functions to the math package, accompanied by comprehensive documentation and examples. (issue)
Discussion Themes
Package Location and Scope
There's significant discussion regarding the appropriate location and scope of the proposed statistical functions. @ianlancetaylor points out that the math package typically mirrors C++'s <cmath>, implying that statistical functions might not fit within its scope. (@ianlancetaylor, issue comment) This leads to the suggestion of a new math/stats package to house these functions and prevent clutter in the core math package. (@jimmyfrasche, issue comment) There's general agreement to keep the initial scope limited to the basic functions proposed, with additions like Percentile, Quartiles, etc., potentially considered later. (@adonovan, issue comment; @hemanth0525, issue comment) @jimmyfrasche suggests that the Python statistics library, which focuses on "what you'd find on a calculator," could serve as a good model for scope. (@jimmyfrasche, issue comment)
Generics and Input Types
The use of generics and the type of input for these functions are also discussed. While @hemanth0525 initially doesn't see a need for generics, suggesting users can convert integers to floats, others argue for generic support for float32 and float64. (@ianlancetaylor, issue comment; @doggedOwl, issue comment) The discussion also touches on using iterators (iter.Seq) as input versus slices ([]float64). While iterators offer flexibility, slices are considered more efficient and convenient for the common use cases of these functions. (@Merovius, issue comment; @adonovan, issue comment)
Specific Function Behavior and API Design
Several comments address the specific behavior and API design for the proposed functions. @randall77 raises concerns about handling rounding, overflow, and the order of operations for the Mean function. (@randall77, issue comment) For the Mode function, there's agreement that a Modes function returning a slice is more suitable to handle cases with multiple modes or no mode at all. (@adonovan, issue comment; @hemanth0525, issue comment) Discussions around the Quantile/Percentile function touch on the specific algorithm to use and how to handle out-of-range quantile values. (@aclements, issue comment) It is also suggested that a list of quantiles should be accepted as an argument, mirroring the API of Python and R. (@CAFxX, issue comment).
Need for Population vs Sample Statistics
There is discussion around the inclusion of both population and sample-based calculations for standard deviation and variance. @glycerine suggests only including sample statistics as they are the most common and useful. (@glycerine, issue comment). It is generally agreed to simplify the API by offering only MeanAndStdDev, calculating both the mean and sample standard deviation in a single pass over the data. (@aclements, issue comment).
Next Steps
The proposal has been added to the active column for review. (@aclements, issue comment) While a concrete implementation is not yet decided upon, the discussions indicate a likely direction: a new math/stats package with a limited scope focusing on basic descriptive statistics. Open questions remain regarding specific algorithms for functions like Quantiles, the handling of edge cases (empty slices, NaN, Inf values), and whether to include a combined MeanAndStdDev function for improved efficiency. The proposal is under active review, but given the number of proposals already in queue, a final decision may take several weeks to months. (@ianlancetaylor, issue comment). A language change to allow explicit []T -> []U conversion if T and U have the same underlying type is being considered as a separate proposal to address type conversion concerns raised by some commenters. (@aclements, issue comment)
(Emoji vote if this was helpful or unhelpful; more detailed feedback welcome in this discussion.)
Comment From: aclements
Which quantile algorithm should we use?
[!WARNING]
I swapped the meanings of "inclusive" and "exclusive" here. See my corrections below.
I am not an expert on this, but my sense is that we should use method R-7 from the Hyndman and Fan taxonomy. This is the default algorithm for R, Julia, and NumPy. Excel provides a few different methods, but this is the one named simply PERCENTILE. Python's standard library provides two algorithms, corresponding to R-6 and R-7; R-6 is the default, but R-7 is the only other built-in one.
I do find it interesting that Microsoft considers the PERCENTILE function to be deprecated in favor of using either PERCENTILE.INC (R-7) or PERCENTILE.EXC (R-6). These are also the two methods provided by Python. This suggests that these two methods are much more valuable in practice than the full spread, and that neither of these two is significantly more valuable than the other. Python's documentation gives a pretty good description of why you would chose one method or the other.
Using the NumPy code sample as a basis, this is what R-6 and R-7 look like on a small data sample:
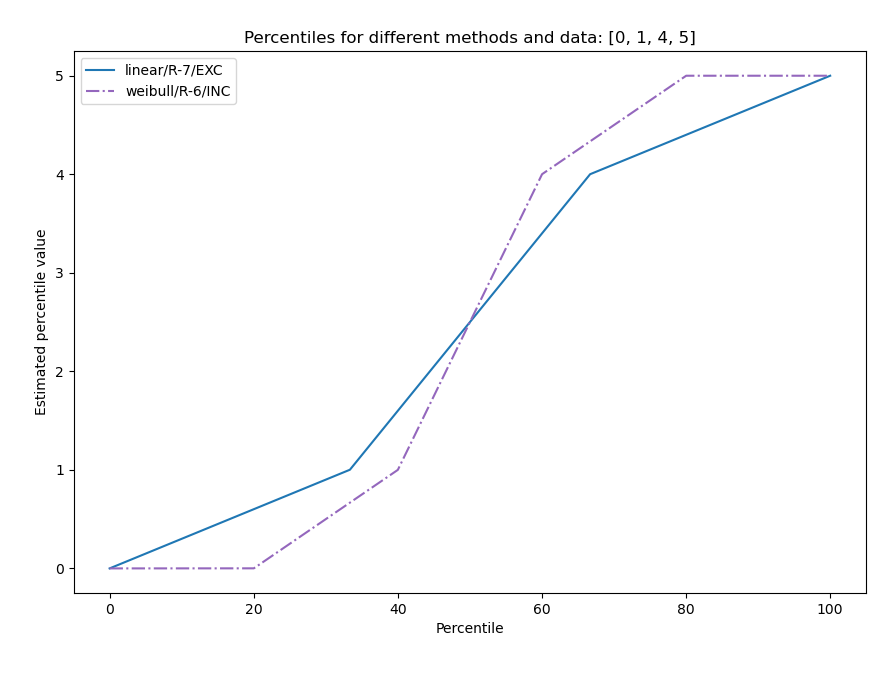
Maybe we want both.
How should we treat quantiles < 0 or > 1?
@adonovan made the compelling argument that this should simply panic. These aren't well defined. I'm always a bit wary of hard cut-offs like this when dealing with floats, but in this particular case the quantiles will almost always be code constants, not the result of some calculation that could have error. If it is the result of a calculation, it's easy enough to cap them to [0, 1]. Finally, panicking will catch nearly any mistaken use of percentiles instead of quantiles.
Comment From: aclements
func Mean[Slice ~[]E, E ~float64](x Slice) E
I think we hadn't really appreciated that for these functions in particular, it's useful for the result type to be the same as the element type. Everyone on the proposal committee is still pretty ambivalent on this, but this realization pushed us from "not worth its weight" to "maybe." Of course, we'd be at the edge of a cliff here: this works for standard deviation, which happens to be the measure of spread in the latest proposal, but this wouldn't generalize if we were to provide a variance function.
We talked a bit about the possibility that gopls and maybe pkg.go.dev could show a "simplified" signature in addition to the full signature as a way to hide the line noise for the vast majority of cases for which the extra parameterization doesn't matter.
Comment From: ncruces
https://github.com/golang/go/issues/69264#issuecomment-2504739523 doesn't specify if the input to Median/Quantiles must be sorted (as the original proposal states); I'm assuming no?
It also doesn't specify (and should, IMO) if they are allowed to modify the slice - i.e.: (partially) sort it - or if they need to make an internal copy of it.
Similar concern for Mode, if it returns from the original proposal.
Comment From: glycerine
This recent review summarizes the literature and covers numerical stability and CPU related issues for the mean and variance computation.
https://ds.ifi.uni-heidelberg.de/files/Team/eschubert/publications/SSDBM18-covariance-authorcopy.pdf
Comment From: glycerine
@ncruces raises a good point that should be documented.
Since these are convenience methods, I was assuming that the user can supply unsorted data, and that Quantiles should have the freedom to sort that data in-place. Perhaps it is best presented up front, and as a feature even. Maybe it should be named SortForQuantiles() to make it clear that getting the quantiles will mean sorting your slice. I would appreciate not having to check the documentation each time to see if I have to sort in advance.
Comment From: aclements
https://github.com/golang/go/issues/69264#issuecomment-2504739523 doesn't specify if the input to Median/Quantiles must be sorted (as the original proposal states); I'm assuming no?
It also doesn't specify (and should, IMO) if they are allowed to modify the slice - i.e.: (partially) sort it - or if they need to make an internal copy of it.
That's a good point. I don't think we should require that they're sorted. These are supposed to be convenience functions, so let's make them convenient. But they can treat an already sorted slice differently.
My inclination is that we should guarantee that these do not mutate the slice. Definitely for Median and possibly for Quantiles, I to allow an implementation using the quick select algorithm. If we do mutate the slice in place, that's not going to result in any useful order for the caller, and may result in confusion. Similarly, if we start with one algorithm and later change it, it's likely to break at least some consumers.
Thus, I propose we guarantee in the documentation that they do not mutate the slice, and also that they allocate asymptotically less if the caller has already sorted the slice (and generally perform better, though I think it's linear either way).
Which quantile algorithm should we use?
It seems like the "exclusive" method (R-7) is the right way to go if we're going to pick just one. It's the default in many languages, and seems more widely applicable than the "inclusive" method (R-6).
We can always add a QuantileInclusive function in the future.
Generics
@jimmyfrasche's argument that these functions should return the same type as the argument has won us over, so we're thinking that the functions should all be of the form:
func Mean[E ~float64](x []E) E
The slices package parameterizes over the slice type as well, but it has many functions that also return a slice that we want to be of the same type as the argument. That's not the case for these functions, so our feeling is that parameterizing over the slice type in addition to the element type is unnecessary.
Comment From: seankhliao
If it's going to be generic, shouldn't it be over both float32 and float64?
Comment From: ncruces
@aclements the quick select algorithm is an in place algorithm that needs to mutate the slice. If do you specify that the slice can't be mutated, ISTM you need an O(N) copy.
I'm also not sure which algorithm you're thinking of that allocates less than O(N) if the slice is sorted, unless you mean that you'll check that the slice is already sorted before doing anything else.
PS: the goal is not statistics, but C++'s nth_element goes the opposite way, and specifically specifies that it partially sorts the slice, which means it can be used to implement statistics, including (which I did a while ago) implementing weighted median in O(N).
Comment From: adonovan
If it's going to be generic, shouldn't it be over both float32 and float64?
I don't think it's necessary: float32 is a poor fit for most numerical analysis tasks because its precision is low, and generalizing algorithms over different floating point precisions may be non-trivial: for example, it may require more iterations of Newton's method.
Comment From: aclements
@ncruces , right, I'm saying that these algorithms would first check if the slice is sorted (which can be done very efficiently). If it's sorted, they can then use direct indexing (also very fast! 😄). If not, they do an O(N) copy operation followed by quick select on the copy.
Comment From: aclements
It turns out I swapped the meaning of "exclusive" and "inclusive" in my above discussion of quantile types. Here are the correct meanings:
| Hyndman and Fan | Q6 | Q7 |
|---|---|---|
| R | R-6 | R-7 (default) |
| NumPy | weibull | linear (default) |
| Excel | PERCENTILE.EXC | PERCENTILE / PERCENTILE.INC |
| Python | exclusive (default) | inclusive |
| Julia | α=1 β=1 (default) |
I can see why Python defaults to Q6, since that's better suited to samples. I'm kind of surprised the other environments all default to Q7, which is better suited to populations.
Comment From: aclements
I think I've accounted for all of the comments here:
// Package stats provides basic descriptive statistics.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[Elt ~float64](x []Elt) Elt
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[Elt ~float64](x []Elt) (mean, stddev Elt)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[Elt ~float64](x []Elt) Elt
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[Elt ~float64](x []Elt, quantiles... float64) []Elt
Comment From: glycerine
In Quantiles description, to remove a small ambiguity about which slice is being called unmodified, since there are two ('x' and 'quantiles'), I would simplify
// Quantiles does not modify the slice.
to
// Quantiles does not modify its inputs.
Comment From: ncruces
If we're going to go there, that could be added to every method, to not make it look that Mean modifies the slice.
I know that this is a separate proposal (which I'm too lazy to write atm) but I wish if this goes forward that we consider exposing (quick/n) select to the public. It's a great building block and fundamental algorithm.
Comment From: glycerine
Like the flag and net/http packages, the convenience of calling without having to instantiate a struct first for the default method could be complimented in the stats package by having the default methods defined on a default stats.Tracker struct which would have a useful default value but then also allow fine tuning of the efficiency and precise algorithm used--and not rule out approaches that are more efficient.
Approaches like T-Digest for quantiles and other algorithms that are stateful/online then become viable -- and can be massive efficiency wins, for those that care and do take the extra step to instantiate, and re-use, their Tracker.
Again this mirrors the approach of the standard library in many places.
(Update) Also: this may be a good reason, even if this is not done on the first pass, not to make the functions generic -- since then they cannot become methods on a Tracker, since generic methods are not available, right (my understanding of genetics is still incomplete, but I think that is the case, no?)
Comment From: adonovan
this may be a good reason...not to make the functions generic -- since then they cannot become methods on a Tracker, since generic methods are not available
Your understanding is correct, but the scope of this package is intentionally very narrow (roughly: concepts familiar to a high-schooler), with the aim that it provides just enough for the overwhelming majority of common statistical queries which use simple operations on relatively small data sets. Operations needing a higher degree of mathematical sophistication, or higher performance, should be sought in an industrial-strength stats package.
Comment From: rsc
Have all remaining concerns about this proposal been addressed?
// Package stats provides basic descriptive statistics.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// Mean does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[F ~float64](x []F) F
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// MeanAndStdDev does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[F ~float64](x []F) (mean, stddev F)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[F ~float64](x []F) F
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[F ~float64](x []F, quantiles... float64) []F
Comment From: jimmyfrasche
Quantiles could return a default set of quantiles when len(quantiles) == 0 instead of a slice of len 0. It would be a friendlier experience more inline with the premise of being easy to use for simple cases. It could default to [0 .25 .5 .75 1].
Comment From: adonovan
Quantilescould return a default set of quantiles whenlen(quantiles) == 0instead of a slice of len 0. It would be a friendlier experience more inline with the premise of being easy to use for simple cases. It could default to [0 .25 .5 .75 1].
Seems very arbitrary. I always want 50 90 95 99 99.9.
Comment From: jimmyfrasche
You can always ask for others. Defaulting to the quartiles seems sensible given their prevalence and the goal to stick to the high school version of things.
Comment From: btracey
1) Flagging that gonum has both MeanStdDev and MeanVariance because I found wanting the variance came up frequently (and seemed silly to square root and then re-square). My use cases are skewed from normal, but wanted to mention now so there was discussion when/if you get future requests.
2) Should there be a CDFs function, i.e. the inverse of the Quantiles function? It lets you know know how rare a specific occurrence is ("this was a 97th percentile event"). It might be worth inclusion due to the specific relation to Quantiles
Comment From: earthboundkid
Quantilescould return a default set of quantiles whenlen(quantiles) == 0instead of a slice of len 0. It would be a friendlier experience more inline with the premise of being easy to use for simple cases. It could default to [0 .25 .5 .75 1].
Another way to do it would be to define stats.Quartiles as [0 .25 .5 .75 1] and do stats.Quantiles(nn, stats.Quartiles...). That said, I think I prefer quartiles as the default. Otherwise you just have to panic, so having a reasonable default is more useful.
Comment From: jimmyfrasche
It says that "The returned slice has the same length as the quantiles slice" so presumably it would returns a slice of length 0 rather than panic. That's logical but not especially user friendly.
Comment From: dfinkel
I'd say that either panicking or returning a 0-length slice make sense if len(quantiles) == 0 any sort of defaulting is likely to induce bugs someplace downstream when someone indexes to pull out a quantile they didn't expect.
In a lot of cases both a 0-length slice or a direct panic will eventually panic, but there are some cases where a config file or request parameter can specify a set of quantiles and it would be natural to have stats.Quantiles return an empty slice, which would naturally translate to an empty table. (it would be super-surprising if I needed to manually suppress a loop because of some stdlib defaulting when rendering a status page)
Comment From: glycerine
I'm fine with the design, but I think there needs to be a strong setting of expectations up front in the introduction; as the design is a departure from the rest of the Go standard library.
I wrote up an appropriate "warning label on the tin" below, and concluded, in the process, that it should probably be called "testing/stats" rather than "math/stats".
Proposed introduction:
On the surprising scope of Go's math/stats package:
Despite its location in math/stats suggesting generality, and the common expectation that the Go standard library provides best-in-class functionality, the Go math/stats package aims for neither.
Arguably it should be called testing/stats.
Instead, this package is deliberately narrow in scope, and is aimed at convenience on small data sets during testing and benchmarking, where maximally efficient algorithms would be overkill, or need multiple setup steps.
Users with big, or even medium sized data, should look to 3rd party packages. Users who need to periodically report statistics are better served elsewhere--you should look into specialized online statistics packages.
There is a natural tension between generality and convenience, and the design of this package leans heavily towards convenience rather than generality and efficiency.
As a prime example to keep in mind, these methods do not modify their input data, and so can, and indeed must--in the common case of unsorted input-- make a copy of all input data to sort it before providing Quantiles. As another example, the errors were omitted from the API and mis-use will result in panics. As a result, these functions are probably not suitable for your production code.
(Edit: add "in the common case of unsorted input" for strict correctness).
Comment From: aclements
Based on the discussion above, this proposal seems like a likely accept. — aclements for the proposal review group
// Package stats provides basic descriptive statistics.
//
// This is not intended as a comprehensive statistics package, but is
// intended to provide common, everyday statistical functions.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// Mean does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[F ~float64](x []F) F
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// MeanAndStdDev does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[F ~float64](x []F) (mean, stddev F)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[F ~float64](x []F) F
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[F ~float64](x []F, quantiles... float64) []F
Comment From: andig
It‘s not clear to me why this has to be in the standard library instead of a third party high quality package.
Comment From: cespare
I write code which uses simple summary statistics like this from time to time, so I think I should be in the target audience for this package. But these days I nearly always write the code so that I don't have to materialize an entire slice of values before computing, say, the mean. So I would find a slice-based API somewhat off-putting. Perhaps I would still end up using it anyway out of convenience from time to time, but it definitely feels wrong. It's like encouraging people to read entire files and pass around []bytes rather than reading data as needed.
For the same reason, I rarely compute precise median or quantiles -- instead, I tend to use a (work-internal) package which estimates quantiles using log-sized buckets. This gives very good approximations while using a tiny amount of memory.
Yes, in many cases all the data could probably fit into a slice without OOMing. But it seems like a naive and fragile approach, and we can do much better.
IOW, I think I fundamentally disagree with @aclements's point upthread:
In this case, if people have enough data that they must stream it, they should probably be using something more specialized.
Comment From: aclements
Given the popularity of gonum/stat, which is entirely slice-based, I'm not convinced that this needs to support streaming. But I'm hearing a lot of arguments that making this slice-based limits the applicability of this package, so I'm open to the possibility of streaming. Let's explore what the API would look like.
Since this would have to be stateful, I think there would have to be a type to collect the streaming sketch. Several people proposed a type earlier in the discussion; it didn't hold its weight for offline statistics, but it is necessary for online statistics. It should still be convenient to use if you have all of the data in a slice.
// Sample collects a sketch of a sample of data for computing basic
// descriptive statistics.
//
type Sample struct { ... }
// NewSample returns a new Sample, populated with data.
// The data argument may be nil.
// NewSample does not modify or retain the data slice.
func NewSample(data []float64) *Sample
// Add adds data to this Sample.
// Add does not modify or retain the data slice.
func (s *Sample) Add(data []float64)
// Merge merges another Sample into this Sample.
func (s *Sample) Merge(other *Sample)
// Mean returns the arithmetic mean of s.
//
// If s is empty, it panics.
// If s contains NaN or both Inf and -Inf, it returns NaN.
// If s contains Inf, it returns Inf. If s contains -Inf, it returns -Inf.
func (s *Sample) Mean() float64
// StdDev returns the standard deviation of the Sample.
//
// If s is empty, it panics.
// If s contains NaN, it returns NaN.
// If s contains Inf or -Inf, it returns Inf.
func (s *Sample) StdDev() float64
// Median returns an approximation of the median of s.
//
// If s is empty, it panics.
// If s contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func (s *Sample) Median() float64
// Quantiles returns approximate quantiles of the sample.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in s and
// a quantile of 1 corresponds to the maximum value in s.
// A quantile of 0.5 is the same as the value returned by [Sample.Median].
//
// To compute quartiles, pass 0.25, 0.5, 0.75.
//
// If s is empty, it panics.
// If s contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func (s *Sample) Quantiles(quantiles... float64) []float64
(This whole API could of course be made generic in the sample type. I think that's a separable question, so I'm not exploring it here.)
I'm assuming that Sample uses a sketching method in order to support computing quantiles.
There are a lot of trade-offs between sketching and a slice-based approach. If all you want are mean or standard deviation, sketching is dramatically less efficient, both space- and time-wise, than a simple slice-based API. Of course, if you only want mean or standard deviation, there are simple streaming approaches, and all that space and time is wasted. Accuracy also becomes much more complicated. For mean and standard deviation, I think if all of the data is presented in a single slice, the result could be just as accurate, but I think there would be a gap if it isn't in a single slice. For median and quantiles, streaming would certainly sacrifice accuracy. For state-of-the-art sketching algorithms at recommended compression settings, the typical relative rank error seems to be around 0.1–1%.
This suggests to me that bundling mean and standard deviation with median and quantiles in a streaming API would be a mistake. Sometimes you do want all of these; sometimes you don't. I'm not sure how to make a clean API out of this.
Background research on sketching
There are several methods for space- and time-efficient sketching while maintaining good accuracy. @glycerine has mentioned t-digests. There are also KLL sketches, which appear to perform similarly to t-digests while generally achieving better accuracy. In particular, while t-digests are remarkably accurate at the tails, they are less accurate for the median. I haven't fully wrapped my head around either t-digests or KLL, but I believe both are constant space and allocation-free once they've reached a certain digest size.
This is certainly not my area of expertise, but I found various overviews that were helpful: an empirical comparison of KLL sketch vs t-digest from Apache DataSketches, and A Review of Recent Results in Streaming Quantiles is a nice literature review of recent algorithms, though it does not include t-digests.
Comment From: andig
Since gonum/stat has been mentioned with 7.8k stars it's even less clear why this should be part of the standard library.
Comment From: ianlancetaylor
If we follow this route, I think it would be better if NewSample and Add take ...float64 rather than []float64. For Add in particular it's easy to imagine cases in which we have just one number to add to the sample, and the syntax of building a slice is unhelpful.
I know nothing about how these kinds of things are implemented, but I think it would be fairly important for at least NewSample(s...).Median() to return an accurate result for that slice. If that is hard then I think we would still need Median([]float64).
Comment From: apparentlymart
@andig the topic of whether this is or is not worthy of inclusion in the standard library was discussed extensively at the start of this discussion -- just about everything before https://github.com/golang/go/issues/69264#issuecomment-2341885234 was about that, and it was touched on again at a few points in later discussion -- so I'd suggest that if you want to revisit that discussion it'd be better to ask a more specific question or present a new argument that takes into account what was already discussed, since otherwise we'll just be retreading discussion points that were already made.
Comment From: andig
Thank you. The core of the argument seems to be
These are basic but essential tools that many developers need in day-to-day tasks, and having them in the standard library could save developers from importing an entire external library like Gonum for simple calculations.
Imho this is a weak argument: - it assumes many developers need these day-to-day (I never did except for trivial mean, see https://github.com/golang/go/issues/69264#issuecomment-2332466631) - it assumes that these selected functions are typical (and that user may not need more which again forces the use of an external library) - it assumes that consuming them from an external library (and that may well be one of smaller scope than gonum) is an issue that warrants having it maintained as part of std
Inclusion into std is obviously not as strict as language changes but it still feel opinionated.
I think there are may parts of Go that would profit from more love (oauth2 for example being one). My preference as long-time Go user would be to focus on problems worth solving in std and this one- for the arguments above- is not one in my (very personal) opinion.
Comment From: seankhliao
Do people need streaming or just a way to sample data?
Aside: When I read streaming I thought it was going to be a window over a time series....
Comment From: aclements
Do people need streaming or just a way to sample data?
I'm not sure, but I will say these are not equivalent. Streaming mean and standard deviation don't require sampling at all, and modern algorithms for streaming quantiles generally don't work by sampling the data.
Aside: When I read streaming I thought it was going to be a window over a time series....
Ah, interesting. I don't think the word "streaming" would necessarily have to appear in the API. That's really describing the "how" rather than the "what".
Comment From: meling
Should it have been as in the slice-based variant:
func (s *Sample) MeanStdDev() (mean, stddev float64)
Comment From: aclements
@meling , the reason for MeanStdDev in the slice-based API was because there's a lot of shared computation between mean and standard deviation. Combining them avoids having to make two passes over the slice and having to compute the sum twice. A stateful, streaming API does not have this same consideration, so API simplicity wins out.
Comment From: glycerine
I like the Sample-based API, as it allows for efficiency.
Is there a way to have this library/proposal not subject to the immediate freeze of the "Go 1 Compatability" guarantee?
It just seems... premature. That is, it seems premature to propose and the immediately freeze an API before there has been implementation, let alone real world use of it.
Experience, feedback and polish generally make a library much more usable, friendly, and robust.
Maybe there can be a "standard library staging" area, where libraries that are eventually going to go in are worked up, evolved, and hardened and made robust and fast?
Thinking of the concerns outlined at https://go.dev/doc/faq#x_in_std
Comment From: Merovius
@glycerine The staging area exists and it is in the golang.org/x repositories. I agree that it is probably a good idea to start this in x/exp/stats (and kind of surprised no one has suggested this before), given how much we've argued about even relatively broad API questions.
Comment From: earthboundkid
I'm also on the fence about this being in the standard library. Putting it in x for a couple of years and seeing if it gets a lot of imports before putting it in std strikes me as very reasonable.
Comment From: doggedOwl
Unfortunetly putting it in golang.org/x these days has become same as putting it in standard library. see for example: https://github.com/golang/go/issues/53427 where x/sync/singleflight can not have breaking changes because people depend on it although it is an experimental package. I think that decision is wrong because it removes the only real playground go has.
Comment From: Merovius
Unfortunetly putting it in golang.org/x these days has become same as putting it in standard library. see for example: https://github.com/golang/go/issues/53427 where x/sync/singleflight can not have breaking changes because people depend on it although it is an experimental package. I think that decision is wrong because it removes the only real playground go has.
Not really. First, x/exp is not x/sync. And second, even if we accept your premise, we can still use the experience from an API in x/exp/stats to eventually put a different API into math/stats. That is, we do get one breakage based on experience either way.
Comment From: jimmyfrasche
If there isn't a good way to make the cumulative moving and sketching code work together maybe just split them up?
type X struct { ... }
func (*X) Add(datum float64)
func (*X) Mean() float64
func (*X) StdDev() float64
and
type Y struct { ... }
func (*Y) Add(datum float64)
func (*Y) Median() float64
func (*Y) Quantiles(quantiles... float64) []float64
They could also be re-unified easily if needed:
type Sample struct {
X
Y
}
func (s *Sample) Add(datum float64) {
s.X.Add(datum)
s.Y.Add(datum)
}
Comment From: glycerine
How about a friendly competition, time boxed to like 6 months; so things don't linger forever.
Nominate judges and put out a "call for design and implementation". Anyone can submit a their (must be public) implemenation repo until the deadline. At the end of the period, the judges evaluate the implementations based on merit (or the defined criteria in the call for design) -- and not on popularity (which is overly influenced by backwards compatibility concerns). Promote the winning design to the standard library, with credit to all who participated, even if their design was not chosen.
It's a small carrot -- bragging rights of having one's design go into the standard library -- but why not use it as a force for good?
edit: Judges can reserve the right to combine, alter, re-do, or discard them all and redo the contest, at their sole discretion. edit2: part of the aim here is to address some of scalability concerns around what goes into the standard library. If you want maintenance work done, just put out another call, e.g. "call for v2 design with these issues addressed."
Comment From: aclements
@glycerine , maybe I'm not understanding your proposal, but choosing the best design is the point of the proposal process. Anyone can submit new designs, either on this issue or as a new proposal. I think the difficulty here is not one of process but one of policy: a math/stats package does not rise to the level of an API that must be in the standard library; rather, it's in the much grayer area of widely-used functionality. Making that call is ultimately the responsibility of the proposal committee, drawing on input from the community. (Unfortunately, much like how it's impossible to build a perfect bounded-time arbiter, no matter how you define that line, there will always be proposals where it takes an arbitrary amount of time to determine which side of that line it's on!)
Comment From: aclements
I think it was worth doing the exercise of exploring a streaming API, but we don't want the perfect to be the enemy of the good here. The much simpler slice-based API seems like a worthwhile addition that covers many bases for simple statistics. For streaming statistics, we encourage people to explore APIs and implementations and propose additions to this package.
Given all of the discussion that happened over the past week, I'll leave this in likely accept for another week.
Thanks everyone!
Comment From: ldemailly
Calculating stats one at a time (or 2 at a time) seems a bit short sighted. I always need min,max,avg,stddev together personally (and often p50, p75, p99,… too) and wouldn’t go over a slice of data N times to do so, even for a small slice.
here is what I use and wrote ages ago: https://github.com/fortio/fortio/blob/master/stats/stats.go#L46
Comment From: ncruces
I know that this is the final comment period, and I'm now late to the party. Sorry.
But it has occurred to me that, given we're specifying that the APIs cannot modify the slices, couldn't/shouldn't these take an iter.Seq[E] instead of an []E?
I mean, now that we have a standard iteration API, does it make sense to continue to pile up APIs that work exclusively on slices? Also, I'm putting this out as a general principle, even if you decide this API should really have slices: always at least consider if a immutable slice based API can use iter.Seq[E] instead.
Comment From: earthboundkid
Using iter.Seq[E] also has the advantage of not needing to specify in the docs that it will/won't clone/modify the slice, since it obviously will clone it.
Comment From: Merovius
I'll note that I suggested iter.Seq above and it's been already rejected.
Comment From: josharian
I've been watching and mulling over this conversation. Though I was initially 👍🏽, it now appears to me:
- There isn't a clean composable API for the simple stuff (min, max, mean, variance, stddev). Both the correct shape of the inputs and the correct shape of the outputs vary meaningfully based on your precise needs.
- There isn't an appetite for the complicated stuff (t-digest, etc.), which might warrant the cost of some abstraction difficulties.
- Any modern LLM can more or less perfectly write the simple functions the first time, in whatever form is most useful to you, in situ.
Given that, I have a hard time convincing myself that this really pulls its weight in the standard library.
Comment From: aclements
But it has occurred to me that, given we're specifying that the APIs cannot modify the slices, couldn't/shouldn't these take an iter.Seq[E] instead of an []E?
Another potential downside of an iterator is that it cuts off certain implementation strategies. For mean and standard deviation, it makes it very difficult to do pairwise summation for high accuracy, though maybe that's okay. For median and quantiles, it basically forces the implementation to copy large parts of the sequence. (Though, a streaming API using sketching could deal with this better, at the cost of accuracy.)
There isn't a clean composable API for the simple stuff (min, max, mean, variance, stddev). Both the correct shape of the inputs and the correct shape of the outputs vary meaningfully based on your precise needs.
@josharian , could you expand on this? I see three "shapes" of input: a slice, an iterator, or a stream. Is that what you mean? By the shape of the output, do you mean which subset of stats the caller wants?
I really think that making the API convoluted just to avoid a couple passes over the slice is the wrong engineering trade-off. Most deep stats packages don't even do this, and it's fine.
There isn't an appetite for the complicated stuff (t-digest, etc.), which might warrant the cost of some abstraction difficulties.
I'm certainly not opposed to this, I just think we explored it enough here to conclude that it's going to need its own proposed API and probably an example implementation.
Comment From: josharian
@josharian, could you expand on this?
For input, there's slice vs iterator. Orthogonally, there's float64 vs float32 vs integer types. (Folks here dismissed float32 offhand, but when working with ML, there's lots of float32 flying around. And I definitely use stats with integer inputs.) Orthogonally, there's float64 vs ~float64 and []float64 vs ~[]float64.
(For slice vs iterator in particular, this is reminiscent of the xiter API challenges https://github.com/golang/go/issues/61898#issuecomment-2479365115. Feels like there's a deeper language problem lurking here.)
For output, yes, which subset of stats. You risk repeating work, doing unnecessary work, or having an awful "I want these fields populated" API.
Again, all of these are surmountable, if the value provided by the package is high: the code is subtle or error-prone or intricate or non-obvious or large or extremely common. On the flip side, the streamlined API might end up being restrictive enough that people don't/can't end up using it frequently enough to warrant it being in the standard library.
That's the argument, anyway. But I'm not going to die on this hill. :)
Comment From: ncruces
For median and quantiles, it basically forces the implementation to copy large parts of the sequence.
If you want a linear time algorithm, you have to copy anyway (because you can't modify the slice).
Otherwise the best you can do is O(n log n) average (and O(n²) worst case?)
Point taken, though.
Comment From: aclements
There's enough opposition and divergence in opinion that we're going to take this out of "likely accept."
Let's try putting the slices API I proposed above into x/exp/stats. That way we can get some actual experience with implementation and use and see if it's valuable to the ecosystem.
Comment From: aclements
(And I want to acknowledge that @Merovius suggested exactly this approach of trying it out in x/exp.)
Comment From: aclements
Have all remaining concerns about this proposal been addressed?
The proposal is to add a golang.org/x/exp/stats package with the following API:
// Package stats provides basic descriptive statistics.
//
// This is not intended as a comprehensive statistics package, but is
// intended to provide common, everyday statistical functions.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// Mean does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[F ~float64](x []F) F
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// MeanAndStdDev does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[F ~float64](x []F) (mean, stddev F)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[F ~float64](x []F) F
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[F ~float64](x []F, quantiles... float64) []F
From here we can get experience and see how widely used this package is and later make a decision one whether this should graduate to a new standard library package math/stats.
Comment From: aclements
This proposal has been added to the active column of the proposals project and will now be reviewed at the weekly proposal review meetings. — aclements for the proposal review group
Comment From: meling
What will be the criteria for inclusion in std lib? How will people discover it? Will it be included in some release notes (as an experiment)? Would be nice to have answers to such questions.
Comment From: ianlancetaylor
I don't think we have any specific criteria for inclusion in the standard library. It will depend on whether people find it useful, and whether the API works well in practice.
Mentioning it in the Go release notes sounds reasonable. That's what we did for the x/exp/slices and maps packages (https://go.dev/doc/go1.18#generics).
Comment From: glycerine
Generalizing Ian's suggestion, wouldn't it be more general to take ...F arguments, allowing for compact one-liners like
mean := stats.Mean(1, 2, 3, 4, 5, 6)
so:
func Mean[F ~float64](x ...F) F
func MeanAndStdDev[F ~float64](x ...F) (mean, stddev F)
func Median[F ~float64](x ...F) F
Edit: I guess a small drawback of that would be you would have to add ... to slices
a := []float64{4, 5, 6}
m := stats.Mean(a...)
Comment From: aclements
Generalizing Ian's suggestion, wouldn't it be more general to take ...F arguments
It seems far more likely that a call site will have a slice of data than a statically-known, fixed length sequence. Given that either can be transformed into the other, I'd lean toward slices.
Comment From: aclements
Based on the discussion above, this proposal seems like a likely accept. — aclements for the proposal review group
The proposal is to add a golang.org/x/exp/stats package with the following API:
// Package stats provides basic descriptive statistics.
//
// This is not intended as a comprehensive statistics package, but is
// intended to provide common, everyday statistical functions.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// Mean does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[F ~float64](x []F) F
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// MeanAndStdDev does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[F ~float64](x []F) (mean, stddev F)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[F ~float64](x []F) F
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[F ~float64](x []F, quantiles... float64) []F
From here we can get experience and see how widely used this package is and later make a decision one whether this should graduate to a new standard library package math/stats.
Comment From: aclements
No change in consensus, so accepted. 🎉 This issue now tracks the work of implementing the proposal. — aclements for the proposal review group
The proposal is to add a golang.org/x/exp/stats package with the following API:
// Package stats provides basic descriptive statistics.
//
// This is not intended as a comprehensive statistics package, but is
// intended to provide common, everyday statistical functions.
//
// These functions aim to balance performance and accuracy, but some
// amount of error is inevitable in floating-point computations.
// The underlying implementations may change, resulting in small
// changes in their results from version to version. If the caller
// needs particular guarantees on accuracy and overflow behavior or
// version stability, they should use a more specialized
// implementation.
package stats
// Mean returns the arithmetic mean of the values in x.
//
// Mean does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN or both Inf and -Inf, it returns NaN.
// If x contains Inf, it returns Inf. If x contains -Inf, it returns -Inf.
func Mean[F ~float64](x []F) F
// MeanAndStdDev returns the arithmetic mean and
// sample standard deviation of x.
//
// MeanAndStdDev does not modify the slice.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN, NaN.
// If x contains both Inf and -Inf, it returns NaN, Inf.
// If x contains Inf, it returns Inf, Inf. If x contains -Inf, it returns -Inf, Inf.
func MeanAndStdDev[F ~float64](x []F) (mean, stddev F)
// Median returns the median of the values in x.
// If len(x) is even, it returns the mean of the two central values.
//
// Median does not modify the slice.
//
// Median may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
func Median[F ~float64](x []F) F
// Quantiles returns a sequence of quantiles of x.
//
// The returned slice has the same length as the quantiles slice,
// and the elements correspond one-to-one.
// A quantile of 0 corresponds to the minimum value in x and
// a quantile of 1 corresponds to the maximum value in x.
// A quantile of 0.5 is the same as the value returned by [Median].
//
// Quantiles does not modify the slice.
//
// Quantiles may perform asymptotically faster and allocate
// asymptotically less if the slice is already sorted.
//
// There are many methods for computing quantiles. Quantiles uses the
// "inclusive" method, also known as Q7 in Hyndman and Fan, or the
// "linear" or "R-7" method. This assumes that the data is either a
// population or a sample that includes the most extreme values of the
// underlying population.
//
// If x is an empty slice, it panics.
// If x contains NaN, it returns NaN.
// -Inf is treated as smaller than all other values,
// Inf is treated as larger than all other values, and
// -0.0 is treated as smaller than 0.0.
//
// If any quantile value is < 0 or > 1, Quantiles panics.
func Quantiles[F ~float64](x []F, quantiles... float64) []F
From here we can get experience and see how widely used this package is and later make a decision one whether this should graduate to a new standard library package math/stats.
Comment From: meling
I came here to add a reminder that this package should be mentioned in the release notes (#71661), and noticed @adonovan added the help wanted label. Does this mean there is more work to be done on this and does it mean that it won't make it for 1.25? Or does it not require the same three-month freeze as the std lib?
Comment From: adonovan
The x/ repos, including x/exp, are not generally subject to the freeze (except for a few packages vendored into GOROOT), so we can make changes there all year round. More importantly, I don't think the new functions have actually been written yet, so release notes would in any case be premature. ;-)
Comment From: gopherbot
Change https://go.dev/cl/687255 mentions this issue: x/exp/stats: implement basic stats API
Comment From: thatnealpatel
I have implemented x/exp/stats as stipulated in https://github.com/golang/go/issues/69264#issuecomment-2737759168; however, the submitted implementation does not use generics.
After reading the entire comment history linearly, it seems to me that the consensus flapped while other conversations occurred (e.g. iterators, taking int, specific algorithms):
1. https://github.com/golang/go/issues/69264#issuecomment-2578465139 [generics]
2. https://github.com/golang/go/issues/69264#issuecomment-2672219644 [no generics]
3. https://github.com/golang/go/issues/69264#issuecomment-2704758890 [generics]
Additionally, https://go.dev/issue/69264#issuecomment-2578434320 indicates that additions to this package might suffer in generalizing; however, a week later, that same sentiment swayed the other way stating that "same output as input" is valuable: https://github.com/golang/go/issues/69264#issuecomment-2594091760.
It seemed that simplicity of the package and parity with math should be prioritized. I am also unsure that the intersection of (a) implementations that need to type their float64s and (b) the implementations that need quick, non-industrial grade statistics on typed float64s justifies the complexity add.
Should this implementation be deemed unfaithful, I am happy to update it with haste.
cc @aclements @adonovan
Comment From: mpx
@thatnealpatel I think you can update the CL now, I think it has been fairly clearly decided to try the slices API in x/exp:
- 7th March: Proposed: Try the slices API form in x/exp
- 7th March: Proposed API
- 13th March: Likely Accept
- 20th March: Accepted
Comment From: thatnealpatel
Hi, @mpx
You'll find these changes will land shortly.
Comment From: gopherbot
Change https://go.dev/cl/688795 mentions this issue: exp/stats: use ~float64 per proposal spec
Comment From: gopherbot
Change https://go.dev/cl/688795 mentions this issue: x/exp/stats: use ~float64 per proposal spec