Bug description
Hi everyone, I'm opening this issue because I've been trying to solve it myself for a few days by looking for solutions and explanations on the Internet and documentation but nothing seems to work.
Problem: I have a dashboard created on Apache Superset which presents several filters on some columns of the dataset used by the charts present in the dashboard itself. These columns are already indexed on Postgres database table. The dashboard presents approximately 21 charts, all referring to the same dataset (table).
A query (executed on pgadmin) to return all the data in the table, filtered on an indexed column uses: 2 seconds.
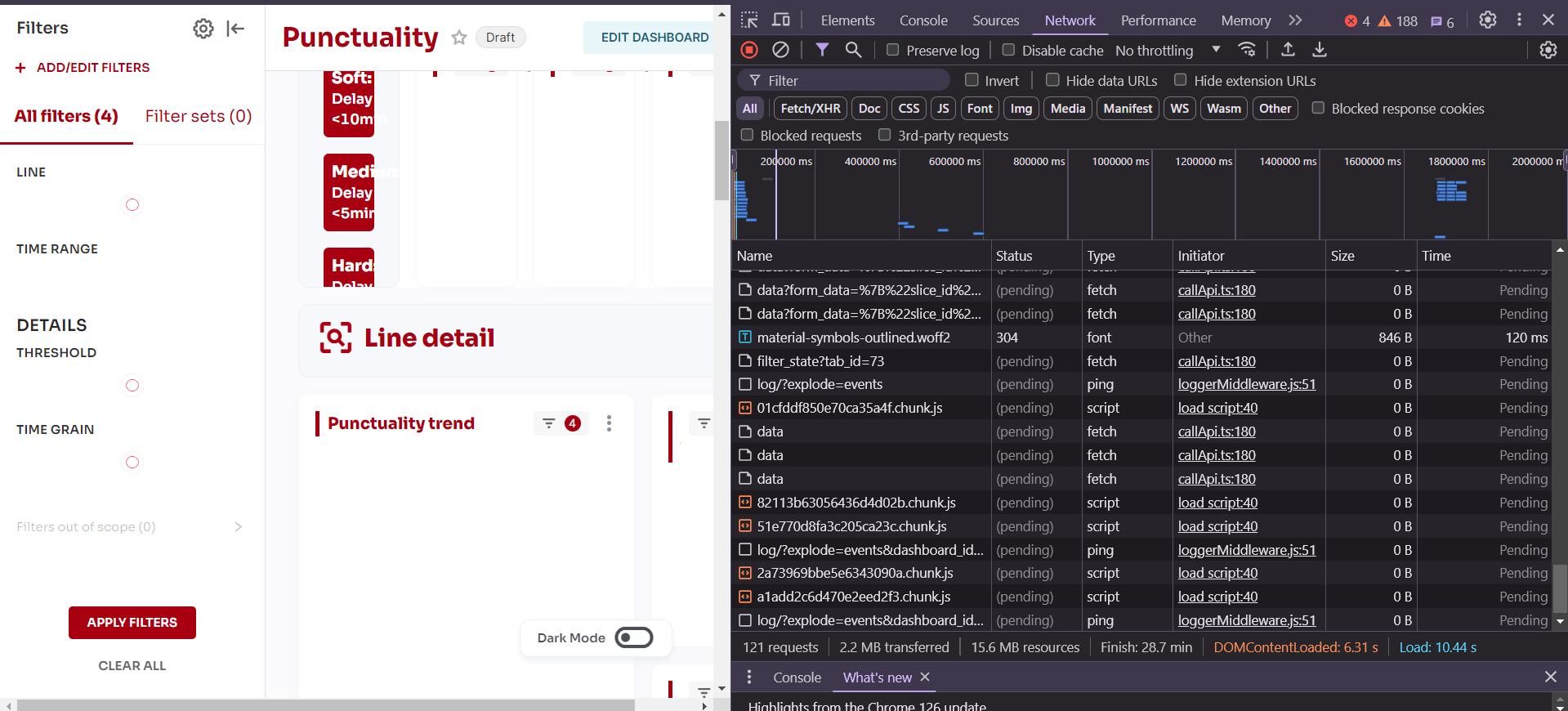
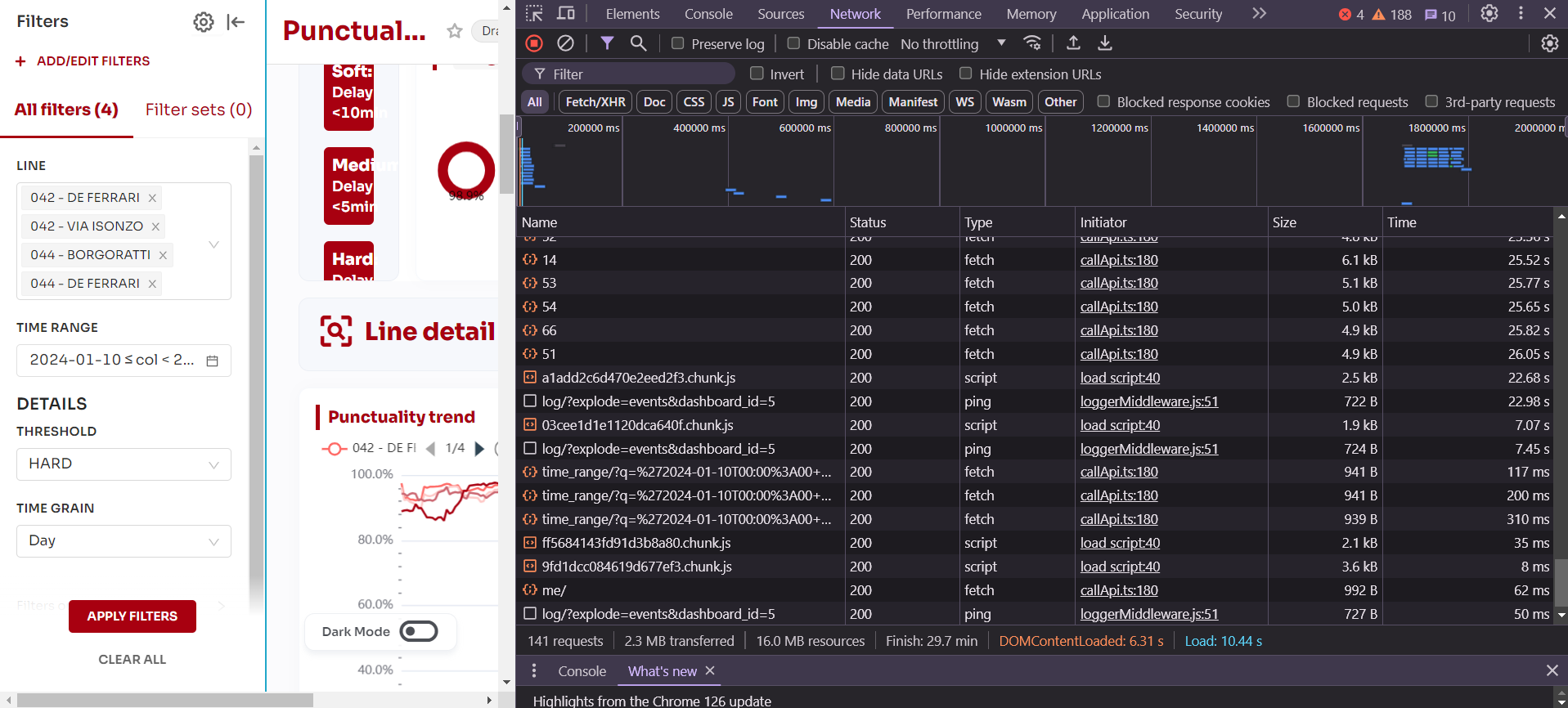
The problem is that the dashboard loading times are at least an order of magnitude higher than the times returned to me on pgadmin: what I perceive as making everything worse is that if I start inspecting the API calls made by the superset front-end it seems to me that the charts are rendered only AFTER the filters value data have been retrieved, which happens to be the longest, so the dashboard remains frozen for up to 30-40 seconds before anything can be displayed.
I also changed these settings on Postgres, hoping to help the parallelization process: max_worker_processes = 32 # Sets the maximum number of total worker processes allowed for the entire PostgreSQL instance, default: 8 max_parallel_maintenance_workers = 16 # max_parallel_workers_per_gather = 32 # Specifies the maximum number of workers that can be started by a single query. Default: 2 max_parallel_workers = 32 # Sets the maximum number of parallel query worker processes allowed for the entire PostgreSQL instance, default: 8
But this also doesn't seem to have worked as it always seems to me to be a lack of parallelization of Superset and that instead the calls are executed in series and for this reason the times are huge. On the internet I read that some people have speeded up this problem by setting DASHBOARD_VIRTUALIZATION = True in the Superset configurations, but it doesn't seem to change anything to me.
I attach some screenshot of the evaluation process.
(Pending request (no charts displayed, even if loading circle is stopped)
How to reproduce the bug
Configuration: Superset docker image: apache/superset:0ddc0a6738bbffc86739a485169e2d5d23ad14e4 postgres db (docker) : cpus: '0.50' memory: 1536M app superset (docker): cpus: '0.50', memory: 1536M superset worker (docker): cpus: '0.50', memory: 2G superset worker beat (docker): cpus: '0.50', memory: 512M
run_server.sh modified: gunicorn \ --bind -0.0.0.0:8088 \ --access-logfile $HYPHEN_SYMBOL \ --error-logfile $HYPHEN_SYMBOL \ --workers 30 \ --worker-class gevent \ --threads 50 \ --timeout 60 \ --keep-alive 5 \ --max-requests 3000 \ --max-requests-jitter 50 \ --limit-request-line 0 \ --limit-request-field_size 0 \ "${FLASK_APP}"
Screenshots/recordings
No response
Superset version
master / latest-dev
Python version
3.9
Node version
16
Browser
Chrome
Additional context
No response
Checklist
- [X] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [X] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [X] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: dosubot[bot]
Hey there, @MasMadd! I'm here to help you with the issue you're facing. I can assist with bugs, questions, and becoming a contributor. Let's work together to resolve this issue.
To address the slow loading times of your Apache Superset dashboard, consider the following optimizations:
- Reduce Payload: Filter out unnecessary metrics and columns to reduce the payload when loading the dashboard. This can be achieved by modifying the data processing logic to only include the required metrics and columns. Here is a relevant code snippet:
def reduce_payload(data, slices):
metric_names = set()
column_names = set()
for slc in slices:
form_data = slc.form_data
for metric_param in METRIC_FORM_DATA_PARAMS:
for metric in utils.as_list(form_data.get(metric_param) or []):
metric_names.add(utils.get_metric_name(metric))
if utils.is_adhoc_metric(metric):
column_ = metric.get("column") or {}
if column_name := column_.get("column_name"):
column_names.add(column_name)
column_names.update(
filter_["subject"]
for filter_ in form_data.get("adhoc_filters") or []
if filter_.get("clause") == "WHERE" and filter_.get("subject")
)
column_names.update(
filter_config["column"]
for filter_config in form_data.get("filter_configs") or []
if "column" in filter_config
)
try:
query_context = slc.get_query_context()
except DatasetNotFoundError:
query_context = None
if query_context:
column_names.update(
[
utils.get_column_name(column_)
for query in query_context.queries
for column_ in query.columns
]
or []
)
else:
_columns = [
utils.get_column_name(column_)
if utils.is_adhoc_column(column_)
else column_
for column_param in COLUMN_FORM_DATA_PARAMS
for column_ in utils.as_list(form_data.get(column_param) or [])
]
column_names.update(_columns)
filtered_metrics = [
metric
for metric in data["metrics"]
if metric["metric_name"] in metric_names
]
filtered_columns = []
column_types = set()
for column_ in data["columns"]:
generic_type = column_.get("type_generic")
if generic_type is not None:
column_types.add(generic_type)
if column_["column_name"] in column_names:
filtered_columns.append(column_)
data["column_types"] = list(column_types)
del data["description"]
data.update({"metrics": filtered_metrics})
data.update({"columns": filtered_columns})
verbose_map = {"__timestamp": "Time"}
verbose_map.update(
{
metric["metric_name"]: metric["verbose_name"] or metric["metric_name"]
for metric in filtered_metrics
}
)
verbose_map.update(
{
column_["column_name"]: column_["verbose_name"]
or column_["column_name"]
for column_ in filtered_columns
}
)
data["verbose_map"] = verbose_map
return data
- Enable Dashboard Virtualization: Ensure that the
DASHBOARD_VIRTUALIZATIONfeature flag is set toTrueto help parallelize API calls and improve loading times:
DEFAULT_FEATURE_FLAGS: dict[str, bool] = {
...
"DASHBOARD_VIRTUALIZATION": True,
...
}
- Optimize Gunicorn Configuration: Adjust your Gunicorn server settings to handle high loads more efficiently. Here is an example configuration:
-w 10 \
-k gevent \
--worker-connections 1000 \
--timeout 120 \
-b 0.0.0.0:6666 \
--limit-request-line 0 \
--limit-request-field_size 0 \
--statsd-host localhost:8125 \
"superset.app:create_app()"
- Caching: Configure caching to improve performance. For example, use Redis for caching filter states:
FILTER_STATE_CACHE_CONFIG = {
'CACHE_TYPE': 'RedisCache',
'CACHE_DEFAULT_TIMEOUT': 86400,
'CACHE_KEY_PREFIX': 'superset_filter_cache',
'CACHE_REDIS_URL': 'redis://localhost:6379/0'
}
- Resource Allocation: Ensure your Superset instance has adequate resources. For a moderately-sized instance, 8GB RAM and 2 vCPUs are typically adequate [1].
By implementing these strategies, you should see an improvement in the loading times of your Apache Superset dashboard.
To continue talking to Dosu, mention @dosu.
Comment From: MasMadd
To everyone, the solutions proposed by @dosu are already implented and do not solve my issues.
Comment From: dosubot[bot]
@rusackas, this one's a bit out of my wheelhouse, could you step in and provide your guidance?
To continue talking to Dosu, mention @dosu.
Comment From: rusackas
It looks like you might have made some customizations to your instance of Superset. Is there anything besides dashboard CSS templating going on there? Pinging @kgabryje as he's looking at (probably unrelated) performance improvements, but might spot something here.
Comment From: MasMadd
It looks like you might have made some customizations to your instance of Superset. Is there anything besides dashboard CSS templating going on there? Pinging @kgabryje as he's looking at (probably unrelated) performance improvements, but might spot something here.
Hi! Apart from changing fonts and importing some icons for dashboard styling, I haven't changed anything as I'm launching supersets through a docker image which has the source code pre-installed and not editable, I'm also attaching the docker image version: apache /superset:0ddc0a6738bbffc86739a485169e2d5d23ad14e4 (available on Docker hub)
Comment From: kgabryje
Hey @MasMadd, as far as I know the charts should wait for filters only if some of your filters have "Select first filter value by default" checked. Could you confirm if that's the case? If not, that could be a bug. However, that doesn't explain why those queries are taking so long. I don't know what might be causing those delays, but maybe @villebro or @betodealmeida have some ideas?
Comment From: MasMadd
Hey @MasMadd, as far as I know the charts should wait for filters only if some of your filters have "Select first filter value by default" checked. Could you confirm if that's the case? If not, that could be a bug.
Hi, sorry for the late reply, I have checked but this seems not correct at all, the filters that I have enabled are with 'default value':
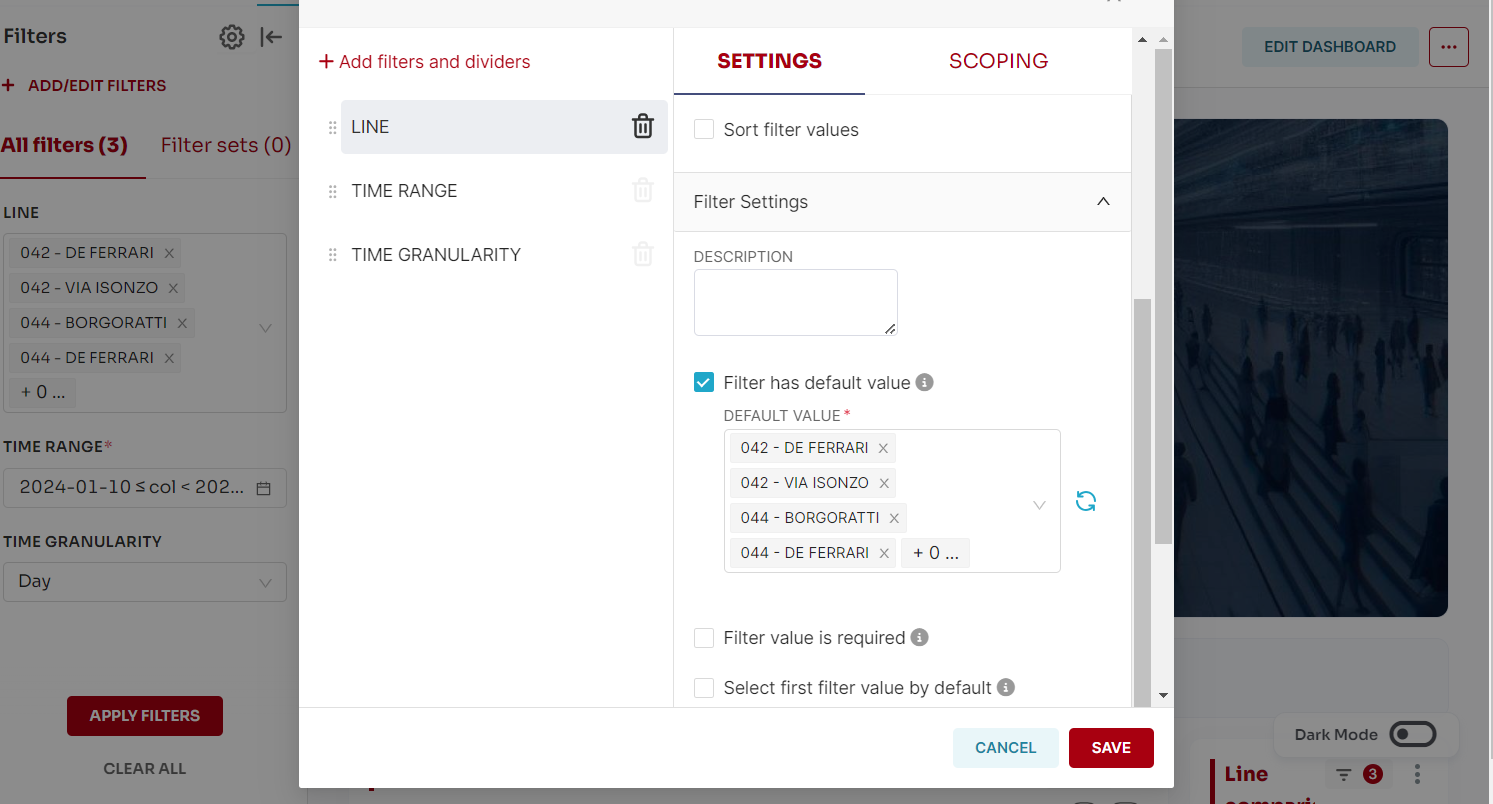
Comment From: kgabryje
@geido Is that something that your PR https://github.com/apache/superset/pull/29632 can help with?
Comment From: rusackas
@MasMadd did you figure out anything here? The thread hasn't been touched in 200+ days, so I'm not sure how to make this one more actionable. Any improvements in newer versions (e.g. 4.1.2/5.0.0)?
Comment From: rusackas
Still wondering if the 5.0 release, or anything thereafter, have improved the situation here. If you think you have some setup/steps we can follow for consistent benchmarking/reproduction, that could help. Otherwise, I could suspect that the shared connection pool might be part of the issue (See https://github.com/apache/superset/issues/31868, https://github.com/apache/superset/issues/27897, for example), but I'm just not sure.
CC @betodealmeida @mistercrunch
Comment From: MasMadd
Still wondering if the 5.0 release, or anything thereafter, have improved the situation here. If you think you have some setup/steps we can follow for consistent benchmarking/reproduction, that could help. Otherwise, I could suspect that the shared connection pool might be part of the issue (See #31868, #27897, for example), but I'm just not sure.
All the information needed to reproduce the bug is in the post itself, unfortunately I don't know what else to provide :/. However, even with this lack of parallelization, I was able to at least reduce the truly long dashboard rendering times by decreasing query execution times, using ad-hoc indexes and materialized views on the database. Unfortunately, for now, I can't follow the advice to update the superset version; I'm currently using the one specified in the post itself and I'm not allowed to modify it in my project.
Comment From: mistercrunch
It would help to see the full "gantt chart" / "piano roll" / timeline view from the chrome dev tools network tab. Wild guess is you're running out of gunicorn workers. Note that anything Celery/workers/async related only affects SQL Lab as all code paths for Explore/Dashboard are executed on web servers.
Ideally you use --async mode in gunicorn (allows for lots of concurrency), otherwise make sure you have lots of "workers"/"threads".
Also possible could be the database queuing up, but piano roll would look different then.