Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[X] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
def flatten_json(data: dict):
sr = pd.Series(data)
df = pd.DataFrame()
df["jsonData"] = sr
flat = pd.json_normalize(df['jsonData'])
return df.join(flat)
expectedData = {
0: {'Field1': 'SomeValue'},
1: {'Field1': None},
2: {},
}
expectedDf = flatten_json(expectedData)
display(expectedDf)
buggedData = {
0: {},
1: {'Field1': None},
2: {},
}
buggedDf = flatten_json(buggedData)
display(buggedDf)
Issue Description
When using pd.json_normalize I expected to keep the distinction between None and NaN cells (or at the very least for the behaviour to be the same regardless of the input.
There are 2 scenarios in the example I gave:
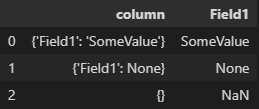
Scenario 1 - At least one value for a specific key (resultant column in the df) in the json is not None or NaN.
In this case the cells containing None are preserved in the final df
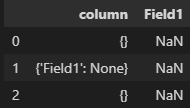
Scenario 2 - All the values for a key (resultant column in the df) in the json payload are None or NaN.
In this case the cells containing None are not preserved in the final df, rather None is converted to NaN
The handling of None should at the very least be consistent in both scenarios. In my opinion it should retain as much information as possible, so the output of scenario 1 makes the most sense to me.
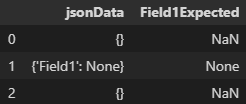
Expected Behavior
I expect to still see a NoneType value even when all the cells are either None or NaN
Installed Versions
Comment From: nguyen-tien-tung
take
Comment From: a-theron
After reviewing the documentation, I think this might not be a bug. I think it is a result of how Pandas handles none types. In Panda's none type documentation it states
pandas uses different sentinel values to represent a missing (also referred to as NA) depending on the data type.
Which means that the different none types (None, NaN, NaT) are used depending on the dtype of the column. So when a column only has missing values (as shown in the "bug"), Pandas has no reference dtypes so all missing values are represented by the default (NaN) none type.
So correct me if I am wrong, but I believe this might actually part of the Panda's feature set, rather than a bug.