Using the latest pandas main (and also happens on released version 2.1.1):
In [1]: pd.to_datetime(["2012-01-01"] * 49 + ["2012-01-02 09"])
...
ValueError: unconverted data remains when parsing with format "%Y-%m-%d": " 09", at position 49. You might want to try:
- passing `format` if your strings have a consistent format;
- passing `format='ISO8601'` if your strings are all ISO8601 but not necessarily in exactly the same format;
- passing `format='mixed'`, and the format will be inferred for each element individually. You might want to use `dayfirst` alongside this.
In [2]: pd.to_datetime(["2012-01-01"] * 50 + ["2012-01-02 09"])
...
ValueError: unconverted data remains when parsing with format "%Y-%m-%d": " 09", at position 1. You might want to try:
...
In the first case, it correctly says "position 49", while in the second case (n > 50), it confusingly says "position 1".
Comment From: KartikeyBartwal
starting to brawl with this issue
Comment From: KartikeyBartwal
no issues on my machine:
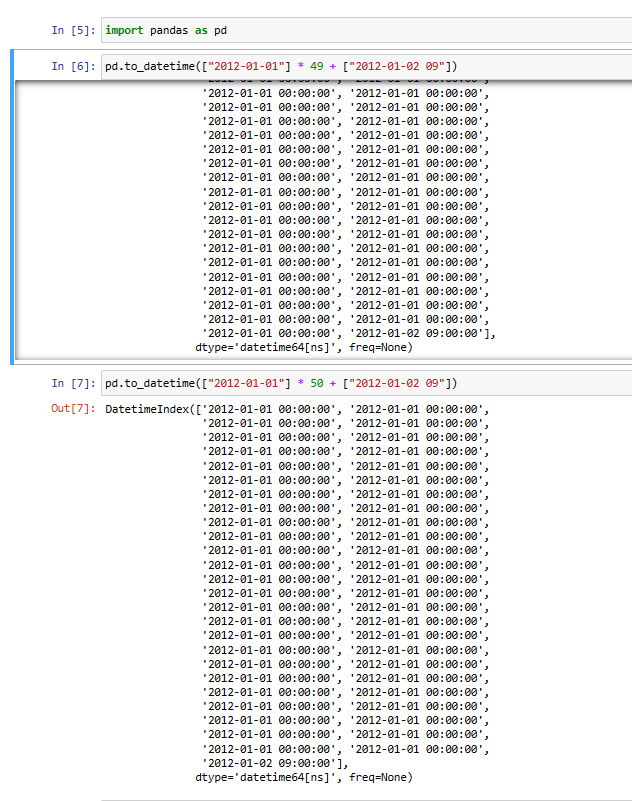
Comment From: paulreece
I can confirm this occurs on the main development branch: ```Python
pd.to_datetime(["2012-01-01"] * 50 + ["2012-01-02 09"]) Traceback (most recent call last): ... ValueError: unconverted data remains when parsing with format "%Y-%m-%d": " 09", at position 1. You might want to try: ...
pd.to_datetime(["2012-01-01"] * 49 + ["2012-01-02 09"]) Traceback (most recent call last): ... ValueError: unconverted data remains when parsing with format "%Y-%m-%d": " 09", at position 49. You might want to try: ... ``
Comment From: KartikeyBartwal
Might be clashing with some other package. Could you share your requirements.txt content files?
Comment From: jorisvandenbossche
@KartikeyBartwal my guess is that you are using an older version of pandas (starting with pandas 2.0, the datetime parsing got stricter, and we now parse all values using the same format by default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html)
Comment From: rsm-23
take
Comment From: Kartikey-Bartwal
@KartikeyBartwal my guess is that you are using an older version of pandas (starting with pandas 2.0, the datetime parsing got stricter, and we now parse all values using the same format by default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html)
You got it right! My version was '1.3.4'
Comment From: jbrockmendel
I suspect this is due to caching. With more than 50 elements, we factorize and pass the unique values to array_to_datetime. The message in this case would reflect the position within the unique elements. If this guess is right, then a fix would require catching the exception, finding the element in question, then finding its position in the original sequence, and patching the exception message.