Feature Type
-
[x] Adding new functionality to pandas
-
[ ] Changing existing functionality in pandas
-
[ ] Removing existing functionality in pandas
Problem Description
I wish to pass an argument to the skew calculation method like (ddof or bias) that allows calculation of the skew of a population instead of a sample (default).
Feature Description
Example:
df.skew(bias=True)
Note: I think it can be implemented using the kwargs of the method _stat_function or _stat_function_ddof
Alternative Solutions
Using scipy.stats.skew(df, bias=True) is an alternative, but it's better if the method of pandas can handle it.
Additional Context
No response
Comment From: lithomas1
This seems reasonable to me. Not at all an expert in this area though.
Do you know what would be the advantages of using ddof as opposed to a bias keyword?
Comment From: Alain-Godo
Hi @lithomas1 thanks for the quick reply!!! Well, there is not a big difference between bias and ddof in this context, the first two degrees of freedom (0 and 1) describe if the collection of data is a population or a sample, and scipy used the parameter bias for the same two things instead of ddof. I also see that this parameter is missed in kurtosis too.
I check it out looking at the code behind and I think it's not so difficult to add the feature. I would like to contribute my grain of sand :pray: , if you allow me I can make the modifications so that it accepts this parameter and do a MR.
Comment From: Alain-Godo
By the way, sorry if my English is not the best, it's not my mother tongue. I do my best.
Comment From: lithomas1
No worries, I think your English is fine :).
Feel free to give a shot (I think using bias should be fine for now, since there doesn't seem to be a need to specify arbritrary ddof if I undertand correctly).
Comment From: Alain-Godo
Thanks, I will try to add the parameter bias to both functions (skew and kurtosis) 😄 Let u know.
Comment From: Alain-Godo
Hi, @lithomas1 !!! Well, I spend a little time today and find the problem.
These two calculations (skew and kurtosis ) need a special method like _stat_function_ddof, maybe can be called _stat_function_bias:
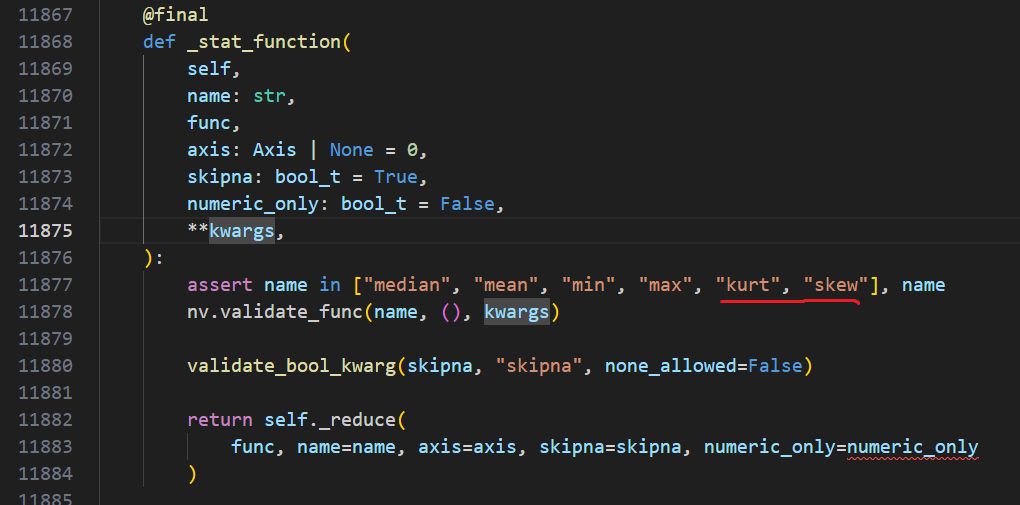
Both functions are implemented using the nanops respectively:
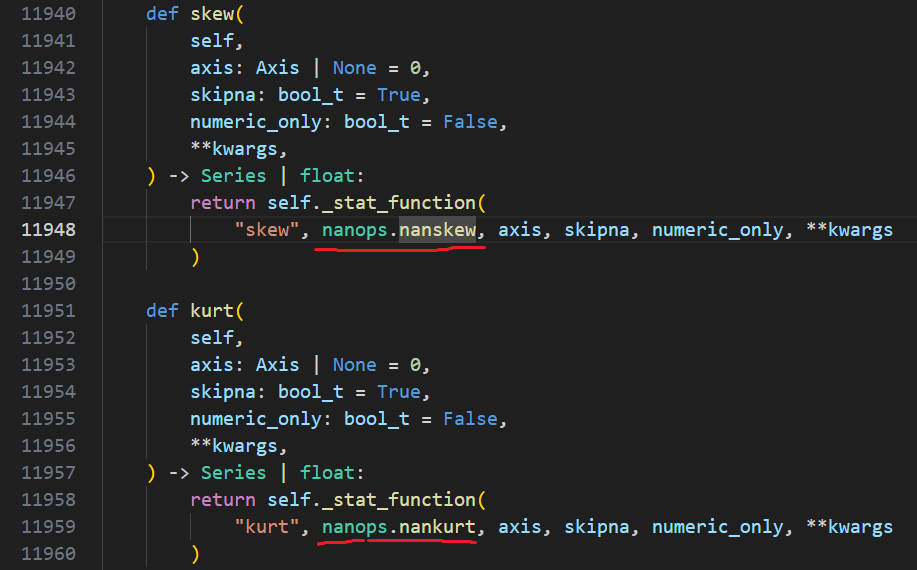
And the problem is there, the implementation in both cases is for "sample" data ( I used to think that pandas use Scipy for the calculation behind 😄 ).
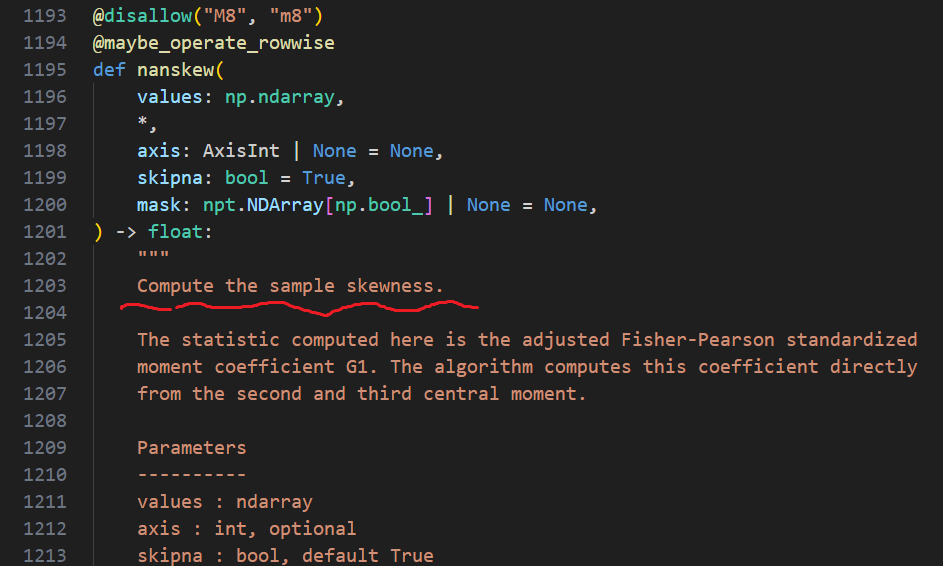
I can modify both functions for sample/population and add a new parameter bias and fix the problem, with the possibility of selecting True or False like Scipy does, also add a _stat_function_bias too, to handle the new parameter. What do u think?
Comment From: Alain-Godo
Hi @lithomas1 and anyone interested !!!, I made the changes for DataFrames and Series, but I can see that the thing with methods like .rolling() is different, the calculation functions are written in Cython. Can you tell me the main sites where I need to add this functionality like in rolling() that I'm not seen yet?
Comment From: lithomas1
Not sure about rolling, I haven't touched that code ever 🤣 , but maybe it's here https://github.com/pandas-dev/pandas/blob/main/pandas/_libs/window/aggregations.pyx#L482 (I haven't double checked this)