Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
Warning an external xlsx file is downloaded I'm not sure how to provide a minimal reproduceable example without an excel file.
import pandas as pd
converters = {
0: lambda v: str(v),
1: lambda v: str(v),
}
df = pd.read_excel("https://finlearn.ro/wp-content/uploads/2025/07/bugreport.xlsx",
header=None,
converters=converters,
engine="calamine")
df.iloc[130:140]
Issue Description
Both convertors and dtype fields are ignored when reading an excel file using the python-calamine engine
Expected Behavior
convertors / data types should be preserved.
Installed Versions
/usr/local/lib/python3.11/dist-packages/_distutils_hack/__init__.py:31: UserWarning: Setuptools is replacing distutils. Support for replacing an already imported distutils is deprecated. In the future, this condition will fail. Register concerns at https://github.com/pypa/setuptools/issues/new?template=distutils-deprecation.yml
warnings.warn(
INSTALLED VERSIONS
------------------
commit : d9cdd2ee5a58015ef6f4d15c7226110c9aab8140
python : 3.11.13.final.0
python-bits : 64
OS : Linux
OS-release : 6.1.123+
Version : #1 SMP PREEMPT_DYNAMIC Sun Mar 30 16:01:29 UTC 2025
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : en_US.UTF-8
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 2.2.2
numpy : 2.0.2
pytz : 2025.2
dateutil : 2.9.0.post0
setuptools : 75.2.0
pip : 24.1.2
Cython : 3.0.12
pytest : 8.3.5
hypothesis : None
sphinx : 8.2.3
blosc : None
feather : None
xlsxwriter : None
lxml.etree : 5.4.0
html5lib : 1.1
pymysql : None
psycopg2 : 2.9.10
jinja2 : 3.1.6
IPython : 7.34.0
pandas_datareader : 0.10.0
adbc-driver-postgresql: None
adbc-driver-sqlite : None
bs4 : 4.13.4
bottleneck : 1.4.2
dataframe-api-compat : None
fastparquet : None
fsspec : 2025.3.2
gcsfs : 2025.3.2
matplotlib : 3.10.0
numba : 0.60.0
numexpr : 2.11.0
odfpy : None
openpyxl : 3.1.5
pandas_gbq : 0.29.2
pyarrow : 18.1.0
pyreadstat : None
python-calamine : None
pyxlsb : None
s3fs : None
scipy : 1.15.3
sqlalchemy : 2.0.41
tables : 3.10.2
tabulate : 0.9.0
xarray : 2025.3.1
xlrd : 2.0.2
zstandard : 0.23.0
tzdata : 2025.2
qtpy : None
pyqt5 : None
INSTALLED VERSIONS
------------------
commit : c888af6d0bb674932007623c0867e1fbd4bdc2c6
python : 3.11.10
python-bits : 64
OS : Linux
OS-release : 6.14.0-24-generic
Version : #24~24.04.3-Ubuntu SMP PREEMPT_DYNAMIC Mon Jul 7 16:39:17 UTC 2
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 2.3.1
numpy : 2.3.1
pytz : 2025.2
dateutil : 2.9.0.post0
pip : 24.0
Cython : None
sphinx : None
IPython : 9.4.0
adbc-driver-postgresql: None
adbc-driver-sqlite : None
bs4 : None
blosc : None
bottleneck : None
dataframe-api-compat : None
fastparquet : None
fsspec : None
html5lib : None
hypothesis : None
gcsfs : None
jinja2 : None
lxml.etree : None
matplotlib : None
numba : None
numexpr : None
odfpy : None
openpyxl : 3.1.5
pandas_gbq : None
psycopg2 : None
pymysql : None
pyarrow : None
pyreadstat : None
pytest : 8.4.1
python-calamine : None
pyxlsb : None
s3fs : None
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : 2.0.2
xlsxwriter : None
zstandard : None
tzdata : 2025.2
qtpy : None
pyqt5 : None
Comment From: khemkaran10
@ramadanomar Converters are not applied to missing values (NaN in this case), so the data from read_excel converts non-missing values to strings but does not change the dtype of NaN. IMO this is the expected behavior in pandas.
import pandas as pd
converters = {
0: lambda v: str(v),
1: lambda v: str(v),
}
df = pd.read_excel("https://finlearn.ro/wp-content/uploads/2025/07/bugreport.xlsx",
header=None,
converters=converters,
engine="calamine")
df.iloc[130:140].map(type)
Output:
Comment From: ramadanomar
It's about not applying the convertors at all:
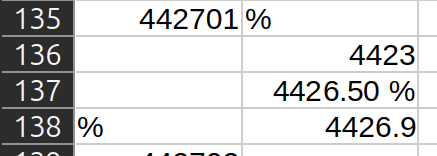
This row is being read as
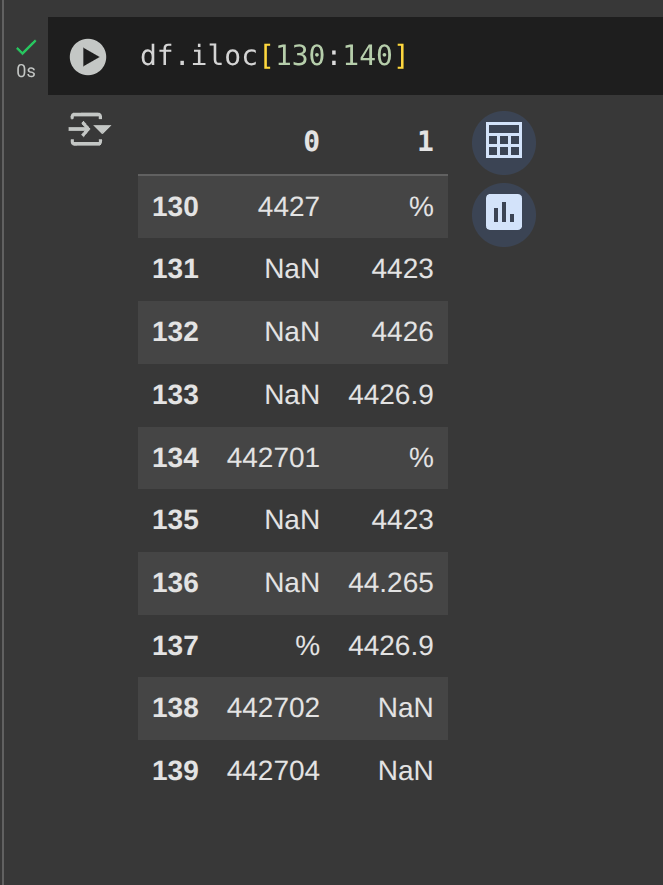
I want to force pandas to read the cell value as a string, without any room for interpretation. If convertors or dtype is not the intended way of achiving this result let me know.
Thanks for the help!