Proposal Details
The Framer has an unexported field that holds a closure responsible for allocating byte slices for reading frame payloads. The existing implementation keeps re-using the same slice, requiring users to copy the contents of data frames before reading the next frame. gRPC Go has a buffer pool which is used to recycle byte slices used during different parts of an RPC. The existing sequence of events when reading a data frame is as follows: 1. The framer reads to its own buffer. 2. gRPC copies framer's buffer to a new slice from its buffer pool, incurring a copy. 3. The buffer from the pool is passed around without needing any further copies. 4. The buffer is returned to the pool after it’s contents are processed.
I propose the addition of a method to the Framer to allow setting a custom allocator.
// SetBufferAllocator sets a custom buffer allocator that will be called for
// getting a buffer slice for each frame payload. The allocator must return a
// slice of the requested length. For data frames, calling DataFrame.Data() will
// always return a prefix of the slice returned by the allocator.
func (fr *Framer) SetBufferAllocator(allocator func(uint32) []byte) {
fr.allocator = allocator
}
For gRPC, the allocator will return a buffer from the shared buffer pool every time. To make it easy for callers to re-use the entire slice, I also propose changing the data framer parsing code to read the optional padding length byte to a different buffer than the one from the allocator. This ensures calling DataFrame.Data() returns a prefix of the allocator’s buffer, without reducing its capacity.
With the new framer API, a sample implementation of gRPC’s allocator function will look as follows:
func (b *bufferAllocator) get(size uint32) []byte {
// Try to re-use a buffer if possible.
if b.curBuf != nil && cap(*b.curBuf) >= int(size) {
return (*b.curBuf)[:int(size)]
}
// Can't re-use, recycle the buffer.
if b.curBuf != nil {
b.bufferPool.Put(b.curBuf)
}
// Get a new buffer.
b.curBuf = b.bufferPool.Get(int(size))
return *b.curBuf
}
The new sequence of events when reading a data frame will be: 1. Framer requests the allocator for a buffer. The allocator gets a buffer from the pool. 2. The framer reads to the allocator's buffer. 3. gRPC takes ownership of the allocator's buffer by saving the buffer and setting the allocator’s buffer to nil, avoiding a copy.
Benchmarks
When running a Google Cloud Storage benchmark that runs on a Compute Engine VM and downloads 10 MB objects in a loop until it’s downloaded a fixed amount of data, we’re seeing a ~4% reduction in CPU time.
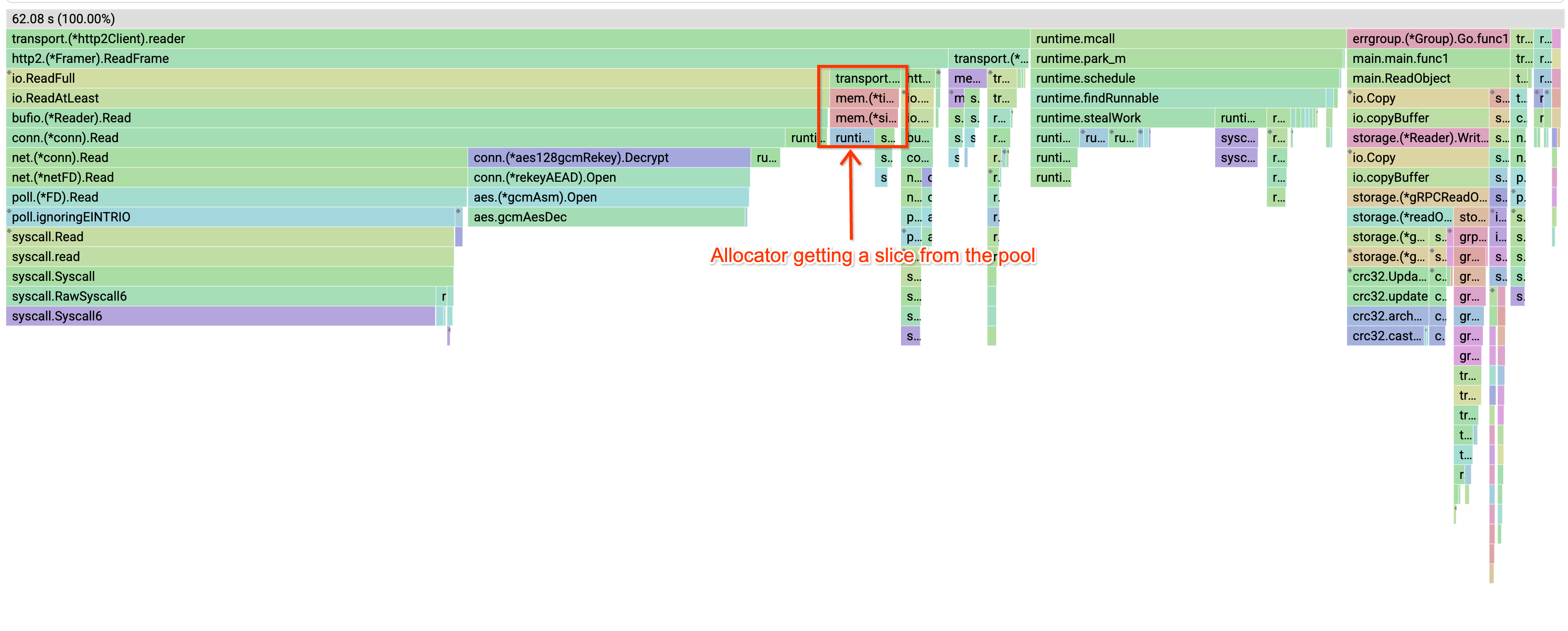
Profiles
Before
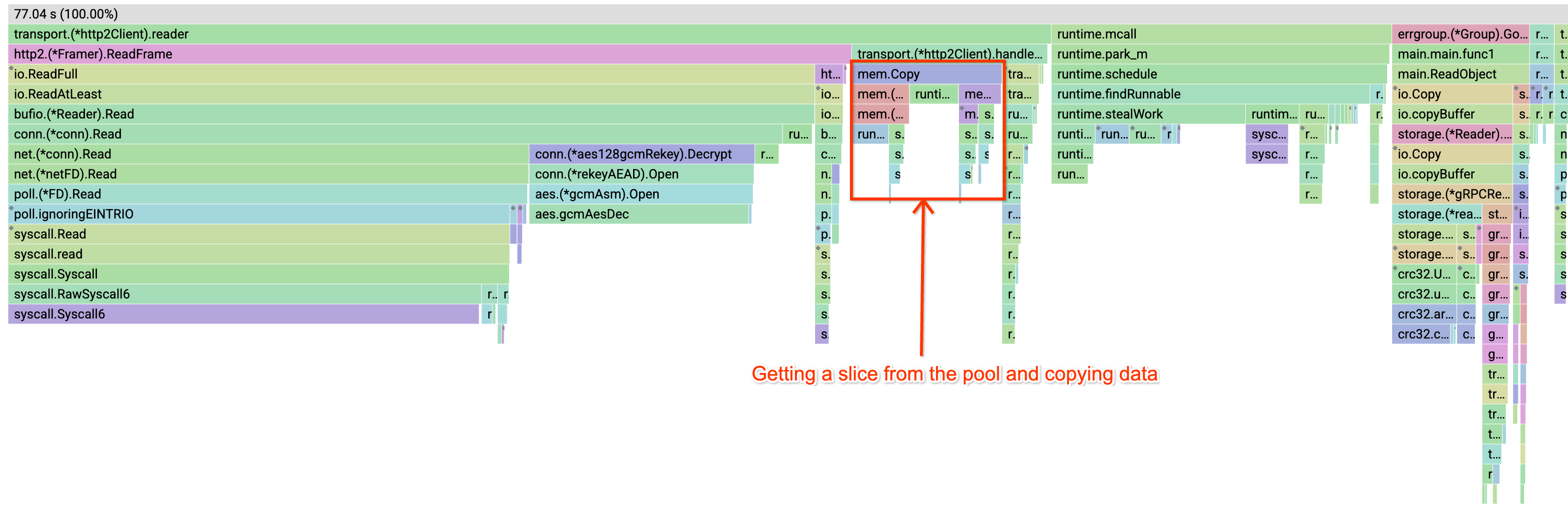
After
cc @dfawley @easwars
Comment From: gabyhelp
Related Issues
- x/net/http2: reduce Framer ReadFrame allocations #18502 (closed)
- x/net/http2: add Framer.WriteDataN method #66655
(Emoji vote if this was helpful or unhelpful; more detailed feedback welcome in this discussion.)
Comment From: neild
A CL demonstrating the change would be useful. In particular, I'd like to see the proposed implementation of the change to how we handle DATA frame padding--the current framer reads an entire frame into a []byte and hands it off to a type-specific parser function, and I don't think that approach works with your requirements.
I'm okay with adding a method to allocate read buffers, but as I said on #66655 I really think gRPC should copy the framer code and adapt it to its needs. The fact that the framer API operates on an io.Reader/io.Writer fundamentally limits its performance, and the need to route changes to the framer through the Go proposal process is an unnecessary impediment to gRPC's ability to make improvements.
Comment From: arjan-bal
Here's a CL that demonstrates the change: https://go-review.googlesource.com/c/net/+/675855
In particular, I'd like to see the proposed implementation of the change to how we handle DATA frame padding
I've moved the padding header parsing logic into ReadFrame, this may not be the cleanest approach though.
Comment From: neild
That CL makes the frame reader quite a bit messier, since it breaks the division between ReadFrame and the individual frame decoding functions.
A possible alternative: Add the ability to read frame headers and bodies separately.
func (fr *Framer) ReadFrameHeader() (FrameHeader, error)
func (fr *Framer) ReadFrameForHeader(h FrameHeader) (Frame, error)
gRPC can then do something like:
fh, err := framer.ReadFrameHeader()
if err != nil {
return err
}
switch fh.Type {
case http2.FrameData:
// read data frame contents directly into whatever buffer is desired
default:
fr, err := framer.ReadFrameForHeader(fh)
// continue usual processing for other frame types
}
Comment From: arjan-bal
@neild I tried implementing the alternate proposal, and it works performance-wise. I realized that during my initial benchmarking, there was another optimization in the feature branch that inflated the results. After re-running the tests, the reduction in CPU time is around 4% (not 15%).
If I understand correctly, in the handling of case http2.FrameData:, gRPC implements its own data frame parsing. A correctness issue may arise if some frame bodies are read without going through the framer. There is a check for frame ordering in ReadFrame that may return incorrect results. It looks like the ordering check relies only on the frame headers of the previous and current frames. So we could move the check into the new ReadFrameHeader() method, since bad ordering results in a connection error, it should be fine to ignore the frame body.
@dfawley what do you think about the alternate above?
Comment From: dfawley
That seems reasonable to me. If we have three read operations on the framer, instead of one, do we need something like the comment on the Write* methods?
It will perform exactly one Write to the underlying Writer. It is the caller's responsibility to not call other Write methods concurrently.
(s/Write/Read/)
Comment From: aclements
This proposal has been added to the active column of the proposals project and will now be reviewed at the weekly proposal review meetings. — aclements for the proposal review group
Comment From: aclements
@prattmic , I'm wondering if this interacts with what you and I were discussing about zero-copy from the kernel.
Comment From: prattmic
@neild In https://github.com/golang/go/issues/73560#issuecomment-2905900700 for the frame data:
switch fh.Type {
case http2.FrameData:
// read data frame contents directly into whatever buffer is desired
Here, when you say "read data frame contents directly", do you mean by directly reading from the io.Reader (presumably net.Conn) passed to NewFramer? i.e., bypassing the Framer and FrameHeader types entirely?
I think that works, but I believe that would also preclude NewFramer from ever wrapping the io.Reader with any sort of buffering. Is that a concern? (maybe that is already precluded for other reasons?).
Comment From: neild
Yes, the idea would be that you read the frame header with the Framer and the frame contents from the io.Reader.
This does preclude NewFramer from adding any buffering, but it's already the case that you need to pass it a buffered reader if you care about performance. (The uses of Framer in x/net/http2 pass it a *bufio.Reader.) Given that it implicitly expects to be given a buffered reader, I don't think we'd ever want to add additional buffering in Framer.
I also suspect that Hyrum's Law dictates that making Framer read past the end of the current frame would break some existing user.
Comment From: prattmic
Regarding https://github.com/golang/go/issues/73560#issuecomment-3137340976:
The context here is that I was brainstorming with @kevinGC about whether it's possible to create a net.Conn (ideally integrated directly into net) which uses Linux's "TCP zerocopy receive" (TCP_ZEROCOPY_RECEIVE) [1]. The context was around enabling use for improving gRPC performance, so that part is certainly relevant.
In a traditional socket, data is written to kernel-owned buffers, and then the read system call in net.Conn.Read copies from the kernel-owned buffer to the slice passed to net.Conn.Read.
In TCP zerocopy receive, the application mmaps pages from the socket, which provide a view into the kernel-owned buffers. The application then makes a getsockopt(TCP_ZEROCOPY_RECEIVE) syscall to tell the kernel to write to the previously mmap'd buffers. Once done, the application can then directly process data in the mmap'd buffer without requiring a copy to an application-allocated buffer [2].
Note that for this to be useful in Go, we need some way of giving a reference to the mapped buffer to the caller of net.Conn.Read. Sure, technically we could internally use zerocopy receive and then have net.Conn.Read copy from the mmap'd buffer to the slice passed to Read. But that doesn't really help, it just moves the copy from the read syscall part of Read to the Go part of Read.
Assuming we do work that API out, I think that zerocopy receive is relevant here. The Framer would parse frames directly out of the mmap'd buffer rather than copying the existing pooled buffer. Then if Framer in turn could provide a reference into the mmap'd buffer to the caller [3], the caller may also be able to process directly without a copy.
Even if the caller needs to make a copy, I think you would still get the same effect as this proposal.
i.e., copies today:
kernel buffer -> Framer buffer -> gRPC buffer
With this proposal:
kernel buffer -> gRPC buffer (by having gRPC bypass Framer and call net.Conn.Read directly for the data frames)
With zerocopy receive:
kernel buffer (mmap'd) -> gRPC buffer (when gRPC copies DataFrame.Data to its own buffer)
I think zerocopy receive probably has a higher potential peak benefit because gRPC may be able it avoid its copy, and so on for further later copies. On the other hand, zerocopy receive is more complex on pretty much every dimension than this proposal.
[1] I hate the term "zero copy". Applications have so many copies, it will rarely be zero copies. I like to translate as "one less copy", but that sounds less cool.
[2] Extreme paraphrasing here, there is apparently lots of fiddly complexity, such as when there is less than one page of data to read.
[3] I think this is already possible via DataFrame.Data 🎉.
Comment From: neild
A point to consider in zerocopy (or one-less-copy) receive is that most of the time the underlying data source is a TLS connection, so the data being provided from the kernel needs to go through the TLS stack before it makes its way to the Framer.
Comment From: prattmic
Ah, good point. I suppose that zerocopy would still be useful to eliminate one copy in the TLS layer, but TLS would obviously need to write the decrypted version elsewhere.
Comment From: neild
I think it should be possible for TLS to decrypt in place, so you could theoretically avoid the need for multiple buffers, but handling HTTP/2 frames split across TLS records would be...challenging.