Bug description
In Superset 4.1.1 I have a problems when updating the query of a dataset which is connected to Trino DB.
After the update the connected chart gives me this error message:
Error: error 400: b'Error 400 Bad Request: Schema is set but catalog is not'
When going back to the editing window I can see that the catalog and schema is missing:
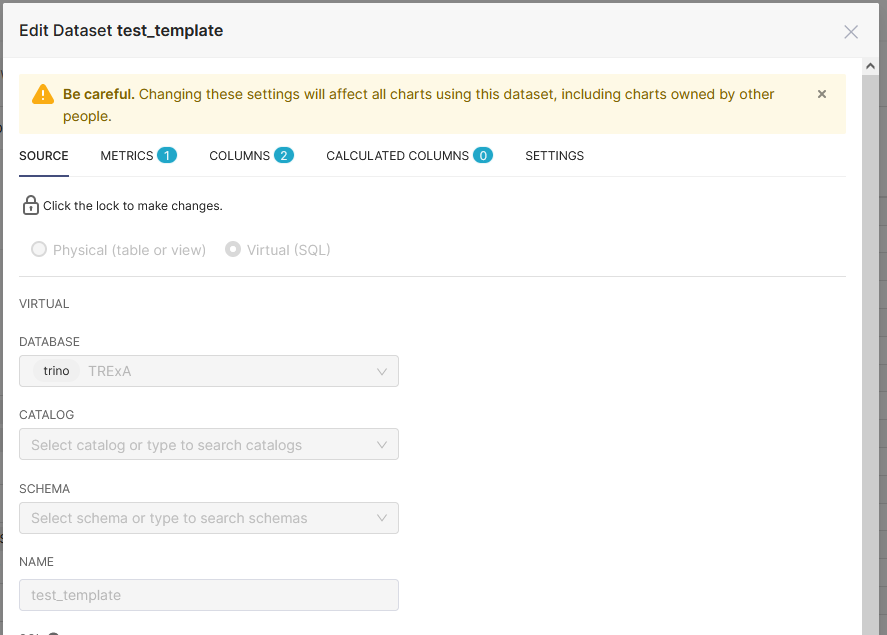
My workaround is to update the catalog in the superset database:
UPDATE tables SET catalog = 'clickhouse' WHERE table_name = 'test_template';
This fixes the schema as well. Maybe because it is the only schema in this catalog.
Screenshots/recordings
No response
Superset version
4.1.1
Python version
I don't know
Node version
I don't know
Browser
Chrome
Additional context
No response
Checklist
- [x] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [x] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [x] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: dosubot[bot]
Hey @scriptbotprime! I'm here to help you with any bugs, questions, or contributions. Let's tackle this together!
To resolve the issue in Superset 4.1.1 where updating a dataset query connected to Trino DB results in the error "Error 400 Bad Request: Schema is set but catalog is not," you need to ensure that both the catalog and schema are specified in the connection URL. The error indicates that a schema is provided without a corresponding catalog, which is required by Trino.
The adjust_engine_params method in the TrinoEngineSpec class handles this by adjusting the engine parameters to include both catalog and schema if they are not fully qualified in the URL. Here is how you can adjust the connection URL:
from sqlalchemy.engine.url import make_url
from superset.db_engine_specs.trino import TrinoEngineSpec
# Example URL with only schema set
url = make_url("trino://user:pass@localhost:8080/system")
# Adjust the URL to include both catalog and schema
uri = TrinoEngineSpec.adjust_engine_params(
url,
{},
catalog="your_catalog", # Set your catalog here
schema="your_schema", # Set your schema here
)[0]
print(str(uri)) # This should print the adjusted URL with both catalog and schema
Ensure that your connection URL in Superset is correctly configured to include both the catalog and schema. If you are setting these values dynamically, make sure they are passed correctly to the adjust_engine_params function [1].
To continue talking to Dosu, mention @dosu.
Help Dosu learn! Give it feedback: Great Response | Irrelevant Answer | Incorrect Sources | Too Verbose | Hallucination | Bug Report | Other
Comment From: rusackas
Can you check master or the 5.0.0 release candidate to see if it happens there? We have a hunch this might be resolved already, but I'll ping @betodealmeida and @sadpandajoe in case they have interest in validating/fixing.
Comment From: annikovk
Same here (Schema is set but catalog is not) while changing the calculated column of a dataset. All the dashboards with this dataset start showing "Unexpected error" Is there a workaround for the versions <5.0.0? I can hardly imagine my company updating BI to a pre-release version.
Comment From: betodealmeida
I'll take a look! Thanks for the report!
Comment From: scriptbotprime
Can you check
masteror the 5.0.0 release candidate to see if it happens there? We have a hunch this might be resolved already, but I'll ping @betodealmeida and @sadpandajoe in case they have interest in validating/fixing.
I used the docker image: apache/superset:15cf066, created another dataset, created a chart on top of it and then changed the dataset. The catalog information was lost again. The error message is different and less informative:
Network Error: Check your network connection
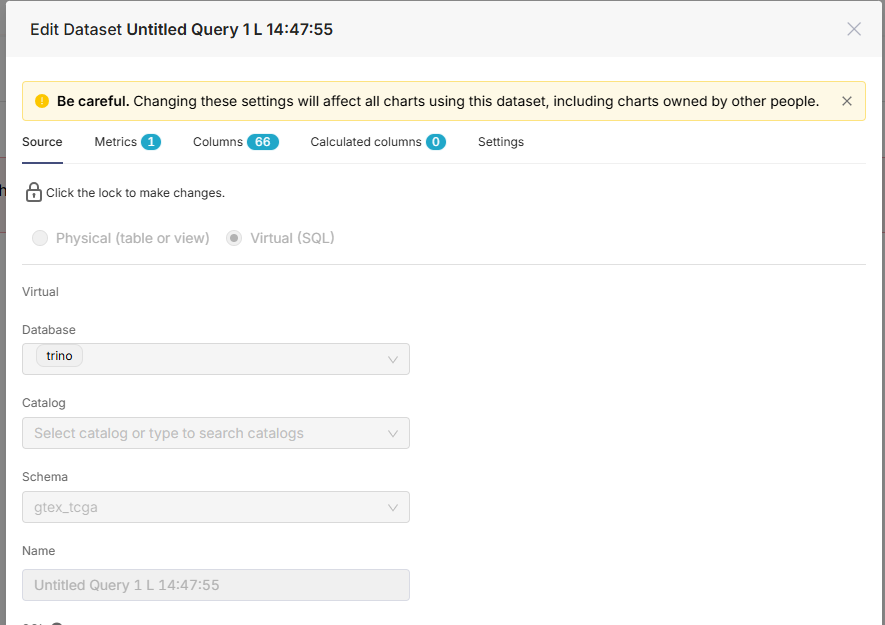
P.S. I pip installed pillow because the container log was complaining.
Comment From: ErikAhlund
Any update on this? We are also running into the same problem. Is there a workaround or temporary fix?
Comment From: ErikAhlund
Update: For now I am creating a different database connection for the two catalogs we have. This is fine for now but it would be great to have multiple catalogs working correctly.
We changed our connection to: trino://<username>:<password>@<host>:<port>/<catalog>/<schema> and unchecked the box Allow changing catalogs in Edit database -> Advanced -> Other
Dashboards are working after a few changes
Comment From: ziggekatten
We have the same issue with trino. The workaround does not work for us as we have some joins between catalog. This is a pain, as we would like to change some labels an metrics.
Comment From: ErikAhlund
We have the same issue with trino. The workaround does not work for us as we have some joins between catalog. This is a pain, as we would like to change some labels an metrics.
We also needed to do joins between catalogs and change some of the data structure. We ended up using dbt to generate these view tables with all the joins (dbt connects to trino and uses its catalogs) and we stored these view in a hive instance which is also a catalog in trino (we started with a memory catalog for testing, but that only lives in memory and we of course need a permanent catalog).
So dbt connects to trino and uses its catalogs to generate views which are stored in the hive instance via trino as well. Then in superset we connect to trino.hive which has all the views with all the joins ready. The good thing about this is that we can use these views outside of superset and they are managed through different sql files (that dbt executes). There is a performance hit but we are currently working on that.
If someone has a better approach don't hesitate to comment. This is the best I could come up with.
Comment From: ziggekatten
We have the same issue with trino. The workaround does not work for us as we have some joins between catalog. This is a pain, as we would like to change some labels an metrics.
We also needed to do joins between catalogs and change some of the data structure. We ended up using dbt to generate these view tables with all the joins (dbt connects to trino and uses its catalogs) and we stored these view in a hive instance which is also a catalog in trino (we started with a memory catalog for testing, but that only lives in memory and we of course need a permanent catalog).
So dbt connects to trino and uses its catalogs to generate views which are stored in the hive instance via trino as well. Then in superset we connect to trino.hive which has all the views with all the joins ready. The good thing about this is that we can use these views outside of superset and they are managed through different sql files (that dbt executes). There is a performance hit but we are currently working on that.
If someone has a better approach don't hesitate to comment. This is the best I could come up with.
Ohhh....good point. We use dbt and Nessie as a catalog. Time to experiment!
Comment From: drummerwolli
i just hit this as well in my databricks SQL set up with 5.0.0. but then i tried the latest master (https://github.com/apache/superset/commit/f4754641c836913820df668e2afb2de409701641 to be specific) and there everything works as expected 🥳
Comment From: rusackas
Oh... interesting! ~~If we can identify the PR that fixed it,~~ we can close this out, and 5.1 or 6.0 (whichever comes first) will include ~~it~~ https://github.com/apache/superset/pull/34125 for sure since it's a cut from master
Comment From: betodealmeida
This was fixed by the amazing @Vitor-Avila in https://github.com/apache/superset/pull/33384.