Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
In [1]: import pandas as pd
pd.
In [2]: pd.__version__
Out[2]: '2.1.4'
In [3]: pd.Series([])
Out[3]: Series([], dtype: object)
In [4]: pd.DataFrame({'a':[]})
Out[4]:
Empty DataFrame
Columns: [a]
Index: []
In [5]: pd.DataFrame({'a':[]}).dtypes
Out[5]:
a float64
dtype: object
Issue Description
There seems to be an inconsistency when creating a Series from empty list via Series & DataFrame constructors. The former yields object dtype, the later returns float64 dtype.
Expected Behavior
Return object in DataFrame constructor
Installed Versions
Comment From: galipremsagar
Same is the behavior for setitem flow too:
In [1]: import pandas as pd
In [2]: df = pd.DataFrame()
In [3]: df['a'] = []
In [4]: df.dtypes
Out[4]:
a float64
dtype: object
Comment From: mroeschke
Thanks for the report. I would also expect this to be object type from these similar constructions
In [4]: pd.DataFrame(columns=["a"]).dtypes
Out[4]:
a object
dtype: object
In [5]: pd.DataFrame([], columns=["a"]).dtypes
Out[5]:
a object
dtype: object
In [6]: pd.DataFrame({}, columns=["a"]).dtypes
Out[6]:
a object
dtype: object
In [7]: pd.DataFrame({"a": []}, columns=["a"]).dtypes
Out[7]:
a float64
dtype: object
In [8]: pd.DataFrame({"a": pd.Series()}).dtypes
Out[8]:
a object
dtype: object
It looks like this goes through sanitize_array where there's this comment
if len(data) == 0 and dtype is None:
# We default to float64, matching numpy
subarr = np.array([], dtype=np.float64)
I'm not sure if there a reason internally why we need to treat this as float64 but I would expect at least via this constructor route that object is still returned
Comment From: srinivaspavan9
I would like to take a look at this issue
Comment From: srinivaspavan9
Thanks for the report. I would also expect this to be
objecttype from these similar constructions```python In [4]: pd.DataFrame(columns=["a"]).dtypes Out[4]: a object dtype: object
In [5]: pd.DataFrame([], columns=["a"]).dtypes Out[5]: a object dtype: object
In [6]: pd.DataFrame({}, columns=["a"]).dtypes Out[6]: a object dtype: object
In [7]: pd.DataFrame({"a": []}, columns=["a"]).dtypes Out[7]: a float64 dtype: object
In [8]: pd.DataFrame({"a": pd.Series()}).dtypes Out[8]: a object dtype: object ```
It looks like this goes through
sanitize_arraywhere there's this comment
python if len(data) == 0 and dtype is None: # We default to float64, matching numpy subarr = np.array([], dtype=np.float64)I'm not sure if there a reason internally why we need to treat this as float64 but I would expect at least via this constructor route that object is still returned
I have debugged and observed that for all the cases except pd.DataFrame({'a': []}) we are getting the length of the data argument in sanitize_array to be 1.
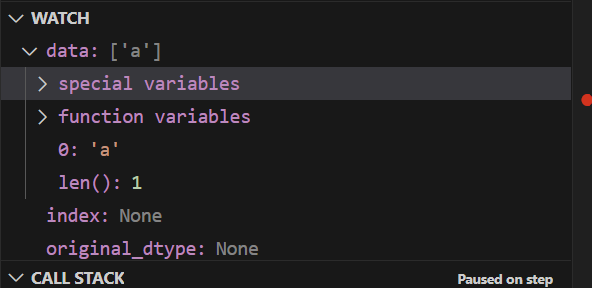
does that mean there is inconsistency with only when an empty dictionary with specified column is passed. and i think sanitize_array is being called twice for when its Dataframe, and in the second time we are getting float64. As you can see below in the call stack. The first time during initialising we are getting the data to be ['a'] but the second time its empty. when its being called from arrays_to_mgr() which you can see in second call stack.
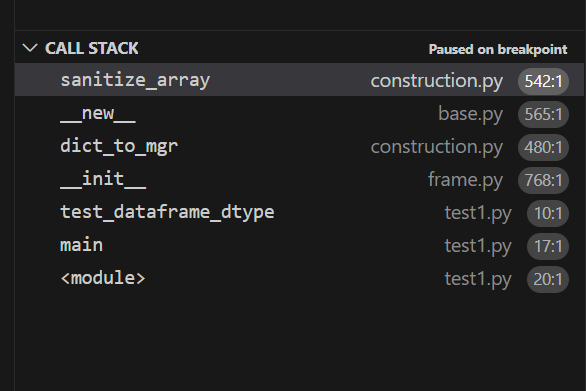
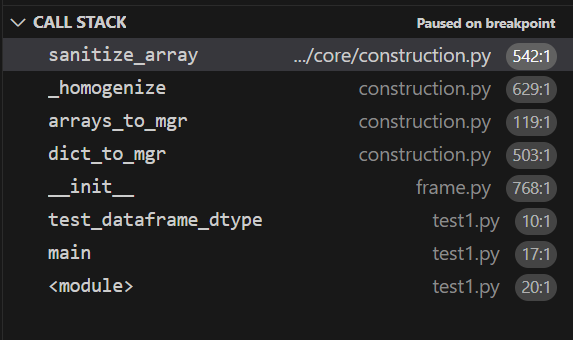
Comment From: rhshadrach
Related: on an empty DataFrame, .values and ._values is a float whereas I'd expect object.
print(pd.DataFrame().values.dtype)
# float64
due to this line:
https://github.com/pandas-dev/pandas/blob/1bf86a35a56405e07291aec8e07bd5f7b8b6b748/pandas/core/internals/managers.py#L1802
I ran into this because DataFrame.stack uses ._values to determine the result dtype, and on an empty frame we wind up with float whereas I'd expect object.
Comment From: rhshadrach
I'm not sure if there a reason internally why we need to treat this as float64 but I would expect at least via this constructor route that object is still returned
With both changes (handling the OP and the one I mentioned above), I'm seeing 35 tests fail in the expected way (i.e. there isn't some functionality we definitely don't want to change that breaks). It seems clear to me these changes would make dtypes on empty objects more consistent. The only question on my mind is if this is a bug fix or needs deprecation.
Comment From: mroeschke
Especially with 3.0 as the next release I would be OK treating this as a "bug fix"
Comment From: rhshadrach
In starting to work on this, one of the things I noticed is that pd.array has the same "default to float" behavior, albeit slightly different.
print(pd.array([]).dtype)
# Float64
I'm thinking this should also be a NumPy object array?
Comment From: mroeschke
I'm thinking this should also be a NumPy object array?
cc @jbrockmendel thoughts?