Bug description
This is the 3.1.2 iteration of the this issue While using the superset app, I sometimes face two issues which might be related: - The superset app is stuck on the loading screen until refreshed manually. - When a dashboard is opened it gives an unexpected error.
How to reproduce the bug
Host the latest version of the superset app deployed using docker, in an EC2 instance. Connect the superset with a database and create multiple dashboards. Use it continuously for a while. In our case this issue can be raised after the redeployment process.
Screenshots/recordings
SQL Lab example:
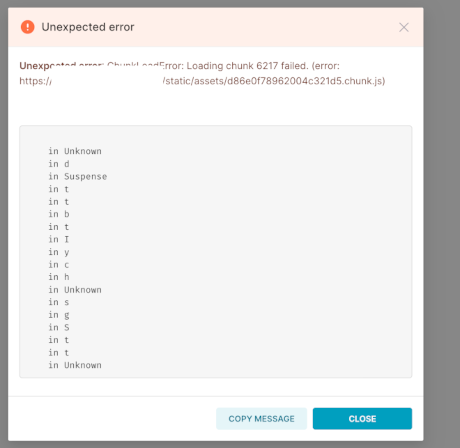
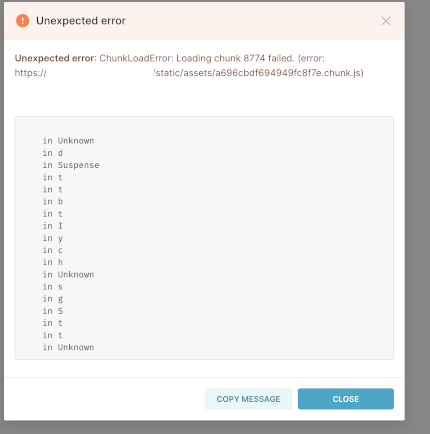
Superset version
3.1.2
Python version
3.9
Node version
16
Browser
Chrome
Additional context
No response
Checklist
- [X] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [X] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [X] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: rusackas
It's not able to load a chunk of the javascript built by webpack. I'm not sure how you're deploying, but is npm run build part of the process, if you're making any frontend changes? That compiles all the JS/TS into bundles as a static asset for Superset to serve. I suspect somehow your deployment is only getting part of the JS updated somehow.
Comment From: Sabutobi
It's not able to load a chunk of the javascript built by webpack. I'm not sure how you're deploying, but is
npm run buildpart of the process, if you're making any frontend changes? That compiles all the JS/TS into bundles as a static asset for Superset to serve. I suspect somehow your deployment is only getting part of the JS updated somehow.
Yep, @rusackas npm run build is there. I've mentioned deployment as one of the factors, but these chunk errors are met without deploy as well.
Comment From: mistercrunch
This is pointing towards a backend/frontend being out of sync. The backend is made aware of a manifest at /static/assets/manifest.json , and there many reasons why this can/could get out of sync (though it's not common AFAIK). But normally if you're on a clean npm run build where manifest is defined and published, and a fresh backend that read the latest manifest, you should be fine.
I'm unclear what happens if the client (browser is out of sync) as it may ask for an old/expired asset while hot-loading (?). I'm guessing at Preset we may persist the older build chunks on the CDN or have some other way to tell the client to refresh its manifest
In your case does a client force-refresh fix the issue? Could you have zombie pods serving an older version of the app?
Comment From: Sabutobi
Hey @mistercrunch and @rusackas . I think I've found the solution for my case.
I've added this code snippet into the superset-frontend/src/setup/setupApp.ts file.
window.addEventListener('error', e => {
// prompt user to confirm refresh
if (/Loading chunk [\d]+ failed/.test(e.message)) {
window.location.reload();
}
});
Can be done as PR by myself if needed.
Comment From: mistercrunch
Looks like a band-aid. It makes me wonder how Superset manages a new manifest and hot loading of obsolete assets (?) If we don't do this already it seems we should generally look for a manifest version and force a refresh of the manifest/assets when the client is behind. I'm wondering if there's anything like that in the code base (?)
@Sabutobi do you only see this on new deploys?
Comment From: rusackas
If it is the client caching pointers to chunks that no longer exist on the server, it does seem like we might have a few options * tell the browser to refresh itself on error (the above suggestion) so it becomes aware and loads chunks... but that does seem glitch-prone in its own way, and does feel like a bandaid. * Keep older chunks around in a directory, with a certain TTL on them that's longer than the client cache. This seems like the safest/smoothest option I can think of. * Have the browser load from cache or not based on data in the JWT. When the site is redeployed, the JWT could effectively invalidate the cache. Probably not straightforward with a SPA... it'd have to do a check on route change or something. * Set up a health check endpoint (I think we might already have one, actually) that responds with a build SHA/UUID. We could check that as a polling operation and/or on SPA route change, and force a reload when it changes... but this also feels like a weird bandaid.
This feels like there should be a best practice, and we're reinventing a wheel here. I'll try to do some digging.
Comment From: mistercrunch
Health check seems would be best and could handle a variety of things: - check auth hasn't expired and potentialy try to refresh the token if it's implemented, otherwise send to login screen - check manifest version (frontend/backend synchronicity) and either refresh the manifest client-side of tells the user to refresh the page or do it on their behalf
Comment From: Sabutobi
Health check seems would be best and could handle a variety of things:
- check auth hasn't expired and potentialy try to refresh the token if it's implemented, otherwise send to login screen
- check manifest version (frontend/backend synchronicity) and either refresh the manifest client-side of tells the user to refresh the page or do it on their behalf
Thanks for the fresh ideas. I'll try to implement that somehow...
Comment From: mistercrunch
Are we sure this is a hot-loading issue (where js bundles are loaded dynamically)? If so it could just be we need better error handling on hot-load and that's it. Like if we get a 404 on hot-load, then you could check the manifest version and pop something to the user "The frontend has gone out of sync from the backend, refresh? Refresh / Cancel"
Comment From: IamJeffG
Just chiming into say that we are getting reports and screenshots of this exact same error (we are on 3.0.2). I have nothing constructive to add here, other than validation that @Sabutobi is not the only one!
Possibly relevant to the questions posed above:
* Yes we are building our own Docker image that just inherits from apache/superset image to overwrite our own superset_config.py; it makes no frontend changes.
* We deploy on Azure App Service, using a burstable instance, which, anecdotally, I feel like may occasionally serve up from older images when cold start.
Comment From: Sabutobi
Hey y'all. I know that's not the solution,but:
const origin = console.error;
console.error = error => {
if (/Loading chunk [\d]+ failed/.test(error.message)) {
alert(
'A new version released. Need to relaod the page to apply changes.',
);
window.location.reload();
} else {
origin(error);
}
};
I've added this code snippet into the superset-frontend/src/setup/setupApp.ts file additionally and I do have this now
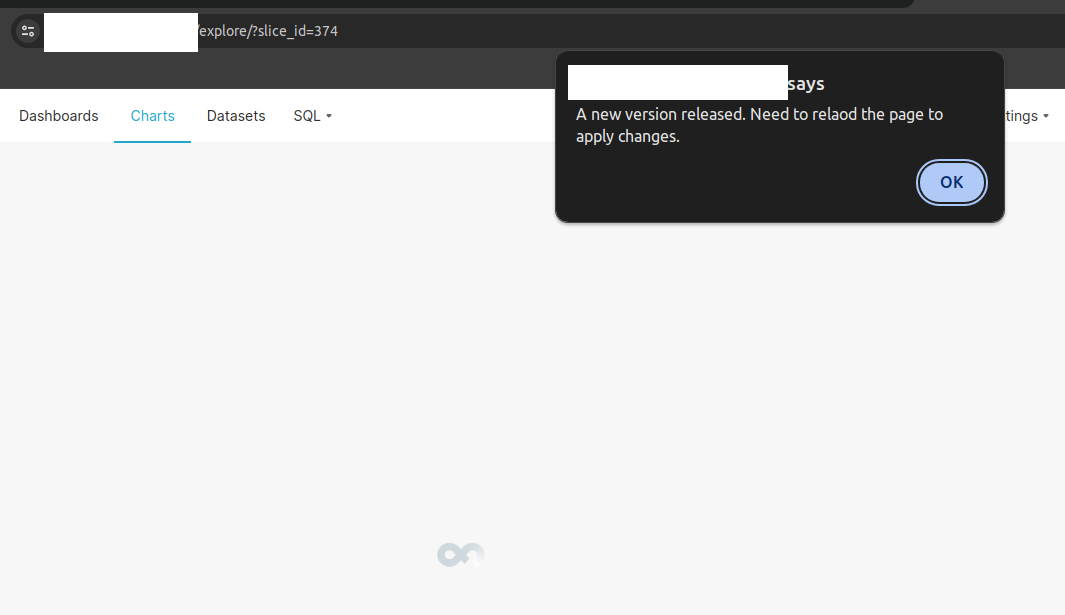
Comment From: rusackas
It's better than nothin'! I guess if it doesn't resolve the problem (like the chunk is really not there) then you're stuck in a loop... but that's an edge case to an edge case, and it's kinda busted either way then.
Comment From: etadelta222
If it is the client caching pointers to chunks that no longer exist on the server, it does seem like we might have a few options
- tell the browser to refresh itself on error (the above suggestion) so it becomes aware and loads chunks... but that does seem glitch-prone in its own way, and does feel like a bandaid.
- Keep older chunks around in a directory, with a certain TTL on them that's longer than the client cache. This seems like the safest/smoothest option I can think of.
- Have the browser load from cache or not based on data in the JWT. When the site is redeployed, the JWT could effectively invalidate the cache. Probably not straightforward with a SPA... it'd have to do a check on route change or something.
- Set up a health check endpoint (I think we might already have one, actually) that responds with a build SHA/UUID. We could check that as a polling operation and/or on SPA route change, and force a reload when it changes... but this also feels like a weird bandaid.
This feels like there should be a best practice, and we're reinventing a wheel here. I'll try to do some digging.
Hi @rusackas , @mistercrunch will the solution be part of a future release?
Comment From: mistercrunch
Yup open a PR and we can see what it'd take to push this through. Some things that would be nice:
- having a way to assess more clearly that it's a version/manifest issue, maybe there's another call to compare versions/manifest, and get more metadata about it
- an antd-powered modal popup, with relevant information as to what exactly is happening
- maybe a more targetted approach hooked to a hot-loading event or callback.
setupApp.tsmay not be the most targeted approach ...
Comment From: Sabutobi
Hey @rusackas and @mistercrunch . FYI: The PR has been opened
Comment From: philicious
Since upgrading to 4.x, the JS Chunk load errors have become so severe we had to downgrade to latest 3.x again. (We have several dozen users and use auto-refreshing dashboards alot)
Comment From: mistercrunch
the JS Chunk load errors have become so severe
I thought the JS Chunk load errors would be corollated to [how many users have an active browser open updates] * [how often you deploy]. Any other theory ln why they would be more frequent in your context? Partly defective or overwhelmed CDN/server * number of chunks to serve?
Comment From: poiema72
Hi all, I'm observing this issue on version 3.1.3 as well. (Unexpected error, Browser is Edge.) I believe no superset docker image customization from our side.
Comment From: rusackas
This last comment is bringing up an old thread that should actually be closed since we no longer support 3.x. Is anyone experiencing this in 4.x?
Comment From: cezudas
We are experiencing the same issue with 4.1.1
Comment From: yashgangrades
Any update on the issue, we are experiencing in latest version also.
Comment From: mistercrunch
In your cases, does a hard refresh (CMD-SHIFT-R) of the page fix the issue for the user?
Comment From: luciesmrckova
Hi, I am using Superset version 4.0.2, and I am facing the same unexpected error message sometimes - unfortunately quite often e.g. 3 cases of 15. The CMD-R page refresh fixes the issue for the user, but the error appears in up to 20% of cases! That is not cool.
Comment From: mistercrunch
Are you continously deploying or deploying a lot behind the scene? Do these errors seem to correlate with deploys? Clearly it seems there's an issue with the single-page-app hot-loading asserts that are now-gone after a redeploy. This is all related to the frontend build "manifest" artifact that changes at each build/deploy.
I'm going to guess that the reason why we don't have issues with this at Preset is that our CDN keeps older assets/builds for a moment across deploys, but can't confirm for sure. Also I think we have something checking whether the user-session/login/token has expired proactively addresses it when that happens, whether it's about auto-recreating a session or redirecting the user to a login page. Maybe this thing does more and takes action on out-of-date frontend assets.
Not sure how other single-page-app handle this or the best practices around it, but one way would be to have some sort of process on a timer that checks whether the app is in sync, and refreshes what needs to be refreshed (the manifest? the web page?) when it realizes the build id is out-of-sync. This could potentially happen on-error, like if/when a hot-loaded asset is MIA, you could check the version and refresh what needs to be refreshed. Just spitballing here.
Comment From: jeanpommier
Hey there, I was too having the problem, it was really inconvenient. But I think I found the solution this week end: increasing the gunicorn keepalive setting to 40 seconds gets rid of those errors.
My Superset instance is integrated in a geOrchestra platform, behind a Spring cloud gateway doing routing & authentication. On a kubernetes infrastructure, so I also have an ingress reverse-proxy (traefik in my case).
Looking at the gateway logs, I indeed had PrematureCloseException or similar exceptions everytime a chunk load error happened.
Digging into this (thanks also to a video about Netty server from violetagg), I figured out that my issue was Superset/gunicorn closing connections while upstream reverse-proxies were still thinking them active.
Setting the env var GUNICORN_KEEPALIVE to 40 (seconds) did the trick. Maybe we don't need to increase them that much, but the default, 2s, seems really too short (and is documented in https://docs.gunicorn.org/en/stable/settings.html#keepalive).
In any case, taking my situation as an example, as far as I understand it, we need to make sure that: gunicorn keepalive > gateway max-idle-time > traefik idleConnTimeout.
I also have the impression that adjusting gunicorn workers and thread numbers improves a bit the latency, but that's just a feeling.
While playing with connection timeout and more specificly with Spring Cloud Gateway, it might be also be interesting to consider changing the leasing-strategy to lifo (see config reference) and possibly disabling the response-timeout for the superset route to cover long-lasting queries.
Hope this helps
Comment From: rusackas
Did the above advice work for others? If so, we should close this. If anyone's experiencing this in 5.0/master as of now, we can keep it open. Please advise :D
Comment From: Sabutobi
@rusackas I was an author of this issue. I've just patched-up my codebase with code from the PR. So that's not relevant for me now. If community have no questions. Feel free to close this one. Thanks for your advices above once more.