Hi All,
I'm just using 0.17 for testing exporting multiindex column dataframe. When i'm pivot table dataframe with X column as index (and without "columns" argument), which will not create multiindex column,
pivot table code (without columns argument):
df.pivot_table(index=["X"], columns=[], aggfunc={"Y": len,"Z":np.sum}, fill_value=0)
df.to_excel(FILE_NAME)
the output using to_excel() follow new format:
But, the question arise when i'm trying to pivot table X column as index (and with "columns" argument), which will create multiindex columns. Then, i'm trying to export it using to_excel() and still follow old format.
pivot table code (with columns argument):
df.pivot_table(index=["X"], columns=["A"], aggfunc={"Y": len,"Z":np.sum}, fill_value=0)
df.to_excel(FILE_NAME)
I don't know if this newest excel export format only applied to single column index, not multicolumn index. Was this case expected or there is something wrong?
Thanks
Comment From: jreback
pls show your code exactly
Comment From: sidoki
@jreback : I'm already update my post with code. Thanks
Comment From: jreback
pls show code that can be copy pasted to reproduce
Comment From: jreback
IOW show how the starting frame was created
Comment From: sidoki
sorry for the misunderstanding @jreback. The following sample code compare output between using multiindex vs singleindex column only.
df = pd.DataFrame(data={"X":["test1","test2","test3","test4","test5","test5", "test2", "test3"],"Y":[0,1,2,2,1,2,10,3], "Z": [1000,300,400,500,2350,100,100,1000], "A":["category1","category2","category2","category3","category4","category4","category5","category1"]})
# pivot df without column argument
df_without_col_arg = df.pivot_table(index=["X"], aggfunc={"Y":np.sum,"Z":np.sum}, fill_value=0)
# pivot df with column argument
df_with_col_arg = df.pivot_table(index=["X"], columns=["A"], aggfunc={"Y":np.sum,"Z":np.sum}, fill_value=0)
# the output will follow new format
df_without_col_arg.to_excel("df_without_col.xlsx")
# the output will follow old format
df_with_col_arg.to_excel("df_with_col.xlsx")
output without multiindex (new format):
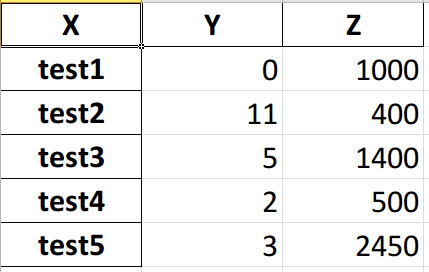
output with multiindex (old format):
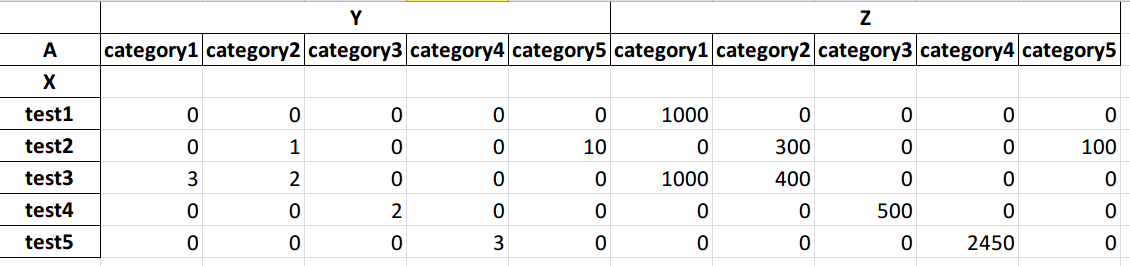
Comment From: jorisvandenbossche
cc @chris-b1
Comment From: chris-b1
@dyngts - you're correct that the format differs by whether or not the columns are a MultiIndex - this was by design and the same way to_csv works. It'd be great if they were consistent, but as far as I can figure out, it's the only way to keep the data unambiguous for read_excel (e.g. see here for more discussion https://github.com/pydata/pandas/pull/10967)
Looks like I should have been a little clearer in the whatsnew note.
Comment From: jreback
In [47]: df_with_col_arg
Out[47]:
Y Z
A category1 category2 category3 category4 category5 category1 category2 category3 category4 category5
X
test1 0 0 0 0 0 1000 0 0 0 0
test2 0 1 0 0 10 0 300 0 0 100
test3 3 2 0 0 0 1000 400 0 0 0
test4 0 0 2 0 0 0 0 500 0 0
test5 0 0 0 3 0 0 0 0 2450 0
In [49]: df_with_col_arg.to_excel('test.xls')
In [50]: pd.read_excel('test.xls',header=[0,1])
Out[50]:
Y Z
A category1 category2 category3 category4 category5 category1 category2 category3 category4 category5
X
test1 0 0 0 0 0 1000 0 0 0 0
test2 0 1 0 0 10 0 300 0 0 100
test3 3 2 0 0 0 1000 400 0 0 0
test4 0 0 2 0 0 0 0 500 0 0
test5 0 0 0 3 0 0 0 0 2450 0
@dyngts this looks correct
Comment From: sidoki
@chris-b1 : Correct, the concern is more to the feature consistency. I assume if new format will be applied to both single column and multi index column. Thanks for clarifying this!!
@jreback : Yeah, it's perfectly works for doing both write and read from excel. But, it seems more elegant if the index column going up one level, see the following example:
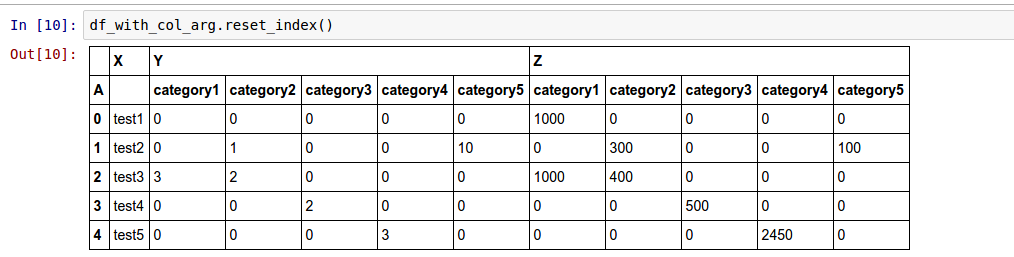
But then, i found new error (i don't know if this already fixed or not). When i'm trying to write excel with not including index (index = False), it throw exception.
NotImplementedError: Writing to Excel with MultiIndex columns and no index ('index'=False) is not yet implemented.
The code is like this
df = pd.DataFrame(data={"X":["test1","test2","test3","test4","test5","test5", "test2", "test3"],"Y":[0,1,2,2,1,2,10,3], "Z": [1000,300,400,500,2350,100,100,1000], "A":["category1","category2","category2","category3","category4","category4","category5","category1"]})
# pivot df with column argument
df_with_col_arg = df.pivot_table(index=["X"], columns=["A"], aggfunc={"Y":np.sum,"Z":np.sum}, fill_value=0)
# resetting index
df_with_col_arg.reset_index(inplace=True)
# write to excel with no index
df_with_col_arg.to_excel("excel-with-no-index.xlsx", index=False)
Any idea?
Comment From: chris-b1
That's not a new error, as the message says, it's simply not implemented yet. I don't think there's any reason it can't be, just some care so the format is unambiguous for reading back in, which may be tricky.
The problem with exporting to Excel in that format is that it's ambiguous - is 'A' the index name or the column level name? more discussion here #10967. Definitely open to suggestions on a better format, but I think the default needs to be able to be round-tripped.
It might be nice to support more customized output, as in #1663 or many of the other output formatting issues.
Comment From: chris-b1
I suppose another way to handle this whole thing could be to store some metadata in the Excel file (like in a hidden sheet) so you could always read and write the "nicest" format, but that might be a bit much.
Comment From: mhooreman
Hi,
Do you have an idea of when it will be fixed?
Thanks a lot.
Comment From: chris-b1
@mhooreman - AFAIK no one is actively working on this, so the quickest way to see a fix will be to submit a PR! See also some discussion here - https://github.com/pandas-dev/pandas/pull/10967#issuecomment-247327566
Comment From: hsheikha1429
Had the same error issue and writing here as a reference to tell what fix it in my case:
Having the index=True fixed my case, the export from df to excel showed the multi Indexing in perfect understood position.
filename = os.path.join(outputDir, "named_df.xls") # .xls or .xlsx doesn't matter
df.to_excel(filename, ### index=True)
Comment From: paulabrudanandrei
Is anyone still working on this?
Comment From: mahammadodj
I am having the same issue, anyone working on this ?