It appears that the support for @Retryable is not complete.
The RetryListener API is defined but is not actually used in conjunction with @Retryable.
A new instance of RetryTemplate is created each time in AbstractRetryInterceptor when a retryable operation is called but without setting a RetryListener.
RetryPolicy retryPolicy = RetryPolicy.builder()
// ...
.build();
RetryTemplate retryTemplate = new RetryTemplate(retryPolicy);
try {
return retryTemplate.execute(new Retryable<>() {
Comment From: sbrannen
Hi @alexey-kadyrov,
Thanks for raising this issue.
The @Retryable annotation from the Spring Retry project does indeed have a listeners attribute, but the @Retryable annotation in Spring Framework does not currently have such support.
Note, however, that RetryListener is supported for programmatic usage with the RetryTemplate.
Thus, we will discuss this within the team to decide if we wish to introduce similar functionality in @Retryable.
Comment From: sbrannen
As I alluded to above, the RetryListener API is tied directly to implementation details of the RetryTemplate, such as RetryPolicy, Retryable, and RetryException.
As such, the RetryListener API does not map directly to all @Retryable use cases, some of which may be reactive (based on the Reactor Retry support).
Thus, there is no straightforward option for supporting the RetryListener API with @Retryable in Spring Framework.
We would like to know what your "listener" requirements are when using @Retryable.
In light of that, can you please share your concrete use case with us?
Thanks
Comment From: alexey-kadyrov
In light of that, can you please share your concrete use case with us?
The use case is to add support for micrometer metrics for the retries caused by using @Retryable.
In overall I prefer this implementation over the one in spring-retry mostly due that it's more developer friendly (@Retryable has all properties as opposite having @Backoff) considering the limitations of Java's annotations, e.g. absence of inheritance and doesn't require an additional dependency.
Comment From: jhoeller
@bclozel I suppose we could build Micrometer support right into AbstractRetryInterceptor itself, similar to how we have out-of-the-box Micrometer support elsewhere already? Knowing what we need to expose for Micrometer purposes, we could adapt this separately: to RetryTemplate/RetryListener as well as to Reactor's RetryBackoffSpec and its before/after/exhaustion callbacks, covering both code paths in AbstractRetryInterceptor.
Comment From: bclozel
I understand that Spring Retry had Micrometer support, but I am not sure about the main goal here.
Observations should be about a specific, well-defined event: processing an HTTP request, a scheduled method, a JMS message.
Here, a retryable event can happen for all of those things. This is actually quite similar to Cacheable, as it is a cross cutting concern. Looking at "spring.retryable" events will not be very useful as they will be about HTTP, JMS, database calls and more. If retryable wraps a RestClient call, you would already get 3 observations (possibly in a single trace).
Which leads to another question: how are those supposed to be modeled within a trace? I am not seeing anything related to retries in the OTel semantic conventions.
Comment From: jhoeller
Good point, @bclozel. From that perspective, it's not an obvious candidate for out-of-the-box observability instrumentation.
@alexey-kadyrov do you have an existing arrangement for observability that you intend to migrate here?
Comment From: alexey-kadyrov
do you have an existing arrangement for observability that you intend to migrate here?
I don't have anything specific, yet. Just exploring different options, e.g resilience4j, spring-retry, and that one. As I mention I like your implementation more due less dependencies and nice balance between configurability and code defined behaviour but it lacks observability.
Having insights into retries is important as it may give you visibility that your retry policies are achieving something as retries in itself are quite expensive from PoV that that add extra latency so it's worth to get those stats in PROD environments to evaluate.
If retryable wraps a RestClient call, you would already get 3 observations (possibly in a single trace)
Yes, you can observe failure/success but there would be no indications (apart of correlation ids) that there is a relationship between those those requests. So it's more about having additional context what is happening.
Comment From: MahatmaFatalError
Having insights into retries is important as it may give you visibility that your retry policies are achieving something as retries in itself are quite expensive from PoV that that add extra latency so it's worth to get those stats in PROD environments to evaluate.
I double that. One aspect is tracing, where indeed it is open how retries should be modelled best (maybe as spans, maybe not), but for metrics I think something similar to https://resilience4j.readme.io/docs/micrometer#retry-metrics is relatively straight forward, is it? Just to keep track of the utilization of your retry mechanism.
Comment From: bclozel
@MahatmaFatalError those are Gauges, this is not possible to achieve with the Micrometer Observation API. I guess a custom listener is a better option.
Comment From: alexey-kadyrov
@MahatmaFatalError , @bclozel my personal preference would be similar as in spring-retry but with the measured latency for overall time, e.g. when eventually succeed or fail - instead of the each individual attempt
Comment From: SuganthiThomas
Hi, I’m interested in working on this issue. I have experience with Java and Spring Boot. Could I take this up?
Comment From: ah1508
@bclozel : following up on your message on issue #35526 : the main use case is to track the retry activity.
Retries are useful for calls to remote resources, network failures may occur or the resource (database, third party API) may be unavailable. If the resource is unavailable people responsible for this resource (db admin for instance) should be already aware of the problem. Less likely for a network failure, the retry interceptor may be the only one to "know" that the call failed.
The goal for an organisation should be to minimize the network failures and thus the retries, but it is hard to do without statistics. Here a listener can help.
The log itself could be enough but requires parsing, setting log level to debug for o.s.core.retry.RetryTemplate will show (for an invocation of @Retryable foo() method")
Preparing to execute retryable operation 'com.example.demo.FooImpl.foo'
Retryable operation 'com.example.demo.FooImpl.foo' completed successfully
or, if a retry occured:
Preparing to execute retryable operation 'com.example.demo.FooImpl.foo'
Execution of retryable operation 'com.example.demo.FooImpl.foo' failed; initiating the retry process
Backing off for 1000ms after retryable operation 'com.example.demo.FooImpl.foo'
Preparing to retry operation 'com.example.demo.FooImpl.foo'
Retryable operation 'com.example.demo.FooImpl.foo' completed successfully after retry`
With a property, the log level for failure could be WARN.
But with a listener the developper have better option to track retries (better than log parsing).
Comment From: bclozel
Thanks for the feedback @ah1508, if I understand correctly you would like to collect data about runtime failures and better understand where they come from. This sounds a lot like a bespoke observability system, so I guess we're back to the original use case here.
Instrumenting @Retryable
I have reconsidered instrumenting @Retryable-annotated methods for observability. There are several challenges for this.
First, observations should be about a specific, well-defined event: processing an HTTP request, a scheduled method, a JMS message. Here, a retryable event can happen for all of those things. We cannot describe properly what we observe, besides saying "some operation that might be retried".
Considering a "spring.retryable" observation, we would time the entire operation (including all retries) and would have to compile information in keyvalues. The operation could look like this:
{
"name": "spring.retryable",
"operation": "com.example.retry.RemoteService#helloClient",
"time": "2.3sec",
"retryCount": 2
}
We would miss critical information like the timing of each attempt, what kind of failures we met. Storing multiple values within a keyvalue is not an option, as this would not work with observability collectors and dashboards. Without looking at the code, we have no idea where the failure is, as our remote service might be failing itself because of another service it is calling.
I think the main goal here is to track operations with remote services and how they (negatively) impact the service we are running in production.
Existing observability support
I wrote an application with the new @Retryable support and our existing Observability support.
In our main application, we implement a controller that calls a remote service:
@RestController
public class TestController {
private final RemoteService remoteService;
public TestController(RemoteService remoteService) {
this.remoteService = remoteService;
}
@GetMapping("/hello")
public String hello() throws Exception {
return this.remoteService.helloClient();
}
}
This RemoteService class uses a RestClient to call a remote application:
@Service
public class RemoteService {
@Retryable(delay = 500)
public String helloClient() {
//...
I tweaked the helloClient() implementation to fail twice for the first calls, on purpose.
Looking at the application metrics on /actuator/metrics/http.client.requests, we can see how our some of our HTTP client requests are failing. We can even zoom in and see failures for particular remote hosts, filter by status, and more.
{
"availableTags": [
{
"tag": "exception",
"values": [
"InternalServerError",
"none"
]
},
{
"tag": "method",
"values": [
"GET"
]
},
{
"tag": "error",
"values": [
"InternalServerError",
"none"
]
},
{
"tag": "uri",
"values": [
"/remote/error",
"/remote/success"
]
},
{
"tag": "outcome",
"values": [
"SUCCESS",
"SERVER_ERROR"
]
},
{
"tag": "client.name",
"values": [
"remoteservice.local"
]
},
{
"tag": "status",
"values": [
"500",
"200"
]
}
],
"baseUnit": "seconds",
"measurements": [
{
"statistic": "COUNT",
"value": 3.0
},
{
"statistic": "TOTAL_TIME",
"value": 1.3424341649999998
},
{
"statistic": "MAX",
"value": 0.602282958
}
],
"name": "http.client.requests"
}
Server observations can even warn us that the "/hello" endpoint is particularly slow; checking /actuator/metrics/http.server.requests?tag=uri:/hello helps. But we don't get the full picture as we don't see how retries were involved. If we had retry metrics we could see that "com.example.retry.RemoteService#helloClient" had many retries, but we would probably see a lot of other retries completely unrelated.
Here, @Retryable instrumentation would not help.
Tracing support
Here, tracing support saves the day as we get a complete picture of a "/hello" endpoint call. We can see multiple HTTP client calls, with the first two failing because of HTTP 500 errors. The timeline neatly represents the delays, no matter which @Retryable configuration you chose.
I don't think that adding a "spring.retryable" would only clutter the trace, as we are already seeing multiple calls in a row and where failures or timeouts happen.
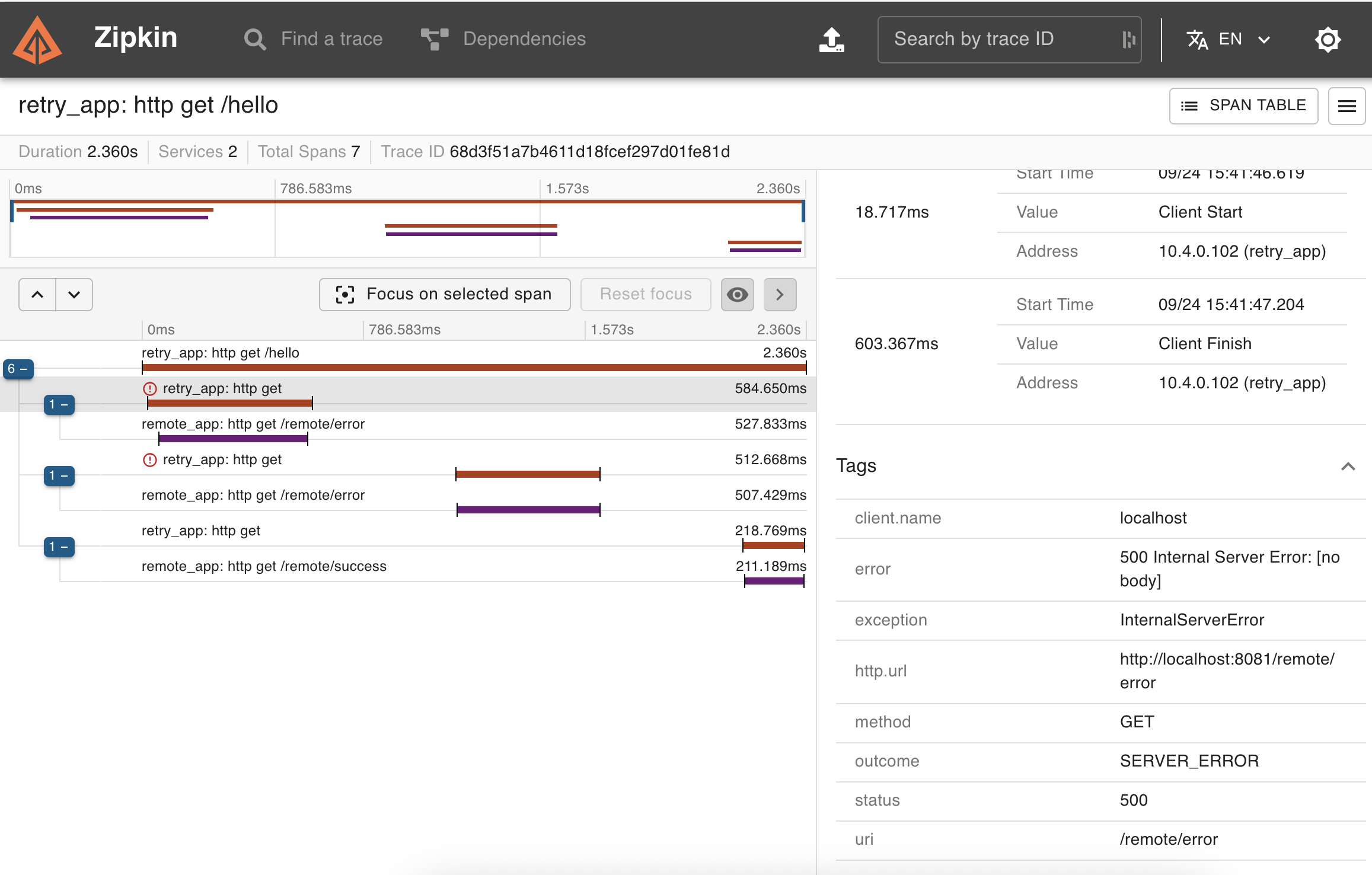
RetryListener registration via annotations
I think this experiment shows that observability support in @Retryable is not a feature we should implement. Now there might be other use cases for RetryListener registration. If you have one, please comment here and describe as precisely as possible the use case and whether the listener should be registered against specific annotated methods, all methods, a subset, etc.