Is your feature request related to a problem?
Calling pd.read_stata on a DTA file with a bad date format code leads to a minimally useful error message. The error is raised from this line.
What I see:
>>> import pandas as pd
>>> pd.read_stata("date_overflow.DTA")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/miker985/lib-code/pandas/pandas/io/stata.py", line 1933, in read_stata
data = reader.read()
File "/home/miker985/lib-code/pandas/pandas/io/stata.py", line 1682, in read
data[col], self.fmtlist[i]
File "/home/miker985/lib-code/pandas/pandas/io/stata.py", line 333, in _stata_elapsed_date_to_datetime_vec
conv_dates = convert_delta_safe(base, days, "d")
File "/home/miker985/lib-code/pandas/pandas/io/stata.py", line 294, in convert_delta_safe
values = [base + relativedelta(days=int(d)) for d in deltas]
File "/home/miker985/lib-code/pandas/pandas/io/stata.py", line 294, in <listcomp>
values = [base + relativedelta(days=int(d)) for d in deltas]
File "/home/miker985/.virtualenvs/tmp-3c950d2b6b7b8c2/lib/python3.7/site-packages/dateutil/relativedelta.py", line 405, in __radd__
return self.__add__(other)
File "/home/miker985/.virtualenvs/tmp-3c950d2b6b7b8c2/lib/python3.7/site-packages/dateutil/relativedelta.py", line 392, in __add__
microseconds=self.microseconds))
OverflowError: date value out of range
Describe the solution you'd like
I'd like a clearer message indicating the problem column. It would be easy to catch the OverflowError in the loop doing the date conversion and include the column name.
Desired detailed error: OverflowError: Failed converting column tiempo_gen for format %dD_m_Y: date value out of range
Alternative error: OverflowError: date value out of range for column tiempo_gen
date_overflow.DTA.gz
I would be happy to submit a patch for this if the solution is approved.
API breaking implications
I don't believe this would break or alter any APIs
Describe alternatives you've considered
- Add a flag
skip_invalid_dateswhich changes behavior to skip converting dates IFF they would error. Instead of raising an exception it would be caught and a warning emitted along the lines of"date value out of range for column tiempo_gen - skipping date conversion". This would allow users access to as much converted data as possible. This flag would default toFalseand be backwards compatible with the APIs. -
I would be happy to submit a patch for this if approved
-
Refactor the
pandas.io.stataAPI to allow for manual date conversion without using private functions.
Additional context
Output of pd.show_versions()
This was the test I put together to hammer out all the details so I knew what was happening with the file
tl;dr
- The column contains values in the millions
- The date units are days, meaning the dates occur after the year 56,000
import pandas as pd
def test_loading_bad_format():
"""
Demonstrate OverflowError is raised with pd.read_stata
"""
dta = "date_overflow.DTA"
try:
pd.read_stata(dta)
except OverflowError as e:
assert len(e.args) == 1
# this message is minimally useful.
# it should include at minimum the column causing the error
assert e.args[0] == "date value out of range"
# demonstrate cause
reader = pd.io.stata.StataReader(dta, convert_dates=False)
# date conversion is the cause here
df = reader.read()
# for one column
assert len(df.columns) == 1 and 'tiempo_gen' in df
min_val = df['tiempo_gen'].min()
# with very large values ...
assert min_val > 20_588_866
assert min_val < 20_588_867
# ... and a format indicating the units are days
# (20.5 million days is ~56,000 years)
assert len(reader.fmtlist) == 1 and reader.fmtlist[0] == '%dD_m_Y'
Example file - a subset of a real life file I ran into this issue with: date_overflow.DTA.gz
Comment From: TomAugspurger
cc @bashtage if you have thoughts.
Comment From: bashtage
The flag would be OK but it should only be part of Stata Reader, read stata. Read stata api is already quite crowded and adding a rarely used feature would just make things worse.
Would it skip entire columns or just observations? If entire columns, would the columns raw values be returned? If single. Observations presumably these would be converted to NAT.
Also, what produced this dta file? Is the date really out of range or does Stata not comply with its own specification (I've seen this once before, so not impossible).
Finally, another option would be to
Comment From: bashtage
The other option, possibly better would be to return object columns with datetime, when it data is out of range.
Comment From: miker985
The flag would be OK but it should only be part of Stata Reader, read stata. Read stata api is already quite crowded and adding a rarely used feature would just make things worse.
:+1:
Would it skip entire columns or just observations? If entire columns, would the columns raw values be returned? If single. Observations presumably these would be converted to NAT.... The other option, possibly better would be to return object columns with datetime, when it data is out of range.
Preference to returning datetime objects (great idea) with raw values second.
Also, what produced this dta file?
The file name indicates it comes from Mexican National Health and Nutrition Surveys (ENSANUT).
Is the date really out of range or does Stata not comply with its own specification (I've seen this once before, so not impossible).
I've opened the file with both Stata 13 and Stata 15. In both cases Stata displays the data as a numeric value in spite of the fact it carries a date format. Using Stata I dropped most rows and all but one column to create the file I uploaded and I received no warnings or errors.
Comment From: bashtage
I've opened the file with both Stata 13 and Stata 15. In both cases Stata displays the data as a numeric value in spite of the fact it carries a date format. Using Stata I dropped most rows and all but one column to create the file I uploaded and I received no warnings or errors.
Does Stata display the other dates in the variable correctly, or is the entire column numeric?
Comment From: miker985
The minimum value is well into the future - they all display as numeric.
Comment From: bashtage
Could you check what happens if you have some valid dates and some large values? Might help decide what return would have the highest fidelity with Stata.
Comment From: miker985
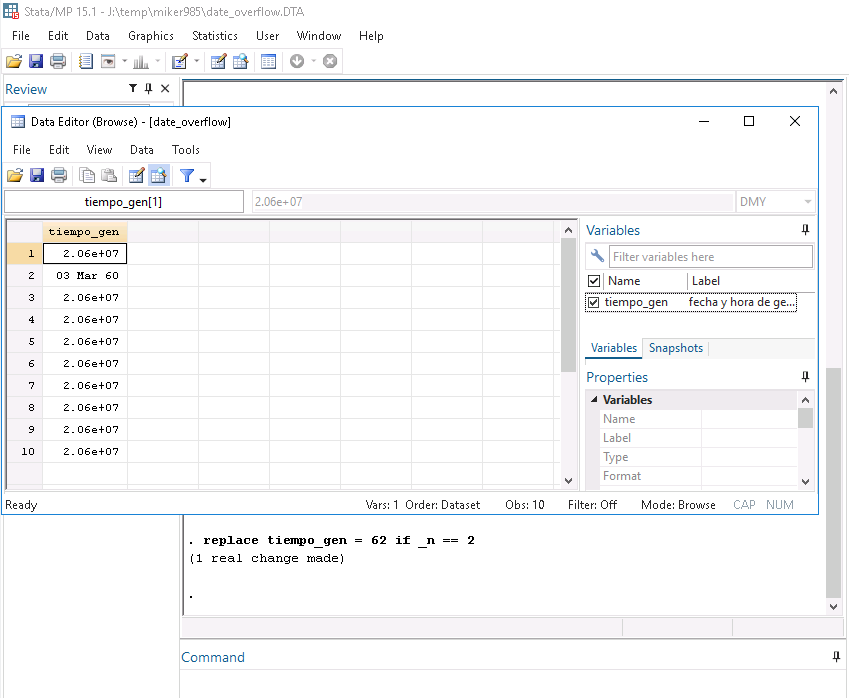
Setting 1 value to a reasonable date results in it displaying as a formatted date.
Comment From: bashtage
This suggests a path where out-of-range are left unmodified and in-range are returned as object. Thinking about the api, it could be a 3-way argument: date_errors with choices "raise" (default), "ignore" (mixed object with datetime and number), "coerce" all converted to dates or NaT if out of range, with a standard datetime column.
Comment From: miker985
How about a fourth argument value that returns regular/slow datetime.datetime objects?
Comment From: bashtage
Do even out-of-range are converted? the hard part is knowing whether this is correct since Stata seems to refuse to convert these values.
Comment From: miker985
Testing indicates STATA will not do date operations on these columns e.g., gen year = year(tiempo_gen) results in missing values for the unformatted distant future dates.
"raise" and "coerce" cover the cases where I don't want to investigate the data manually. As near as I can tell "coerce" most closely mirrors Stata's behavior.
For the case I want to investigate the data "ignore" leaves me wanting. There are no public methods in stata.py to do date conversion and I'm keen to have some way to be able to see what the dates would be in case manual inspection can provide context to correct the data e.g., by consulting the documentation that came with it.
Comment From: bashtage
Well, you can always read the data without converting the dates. What is unclear to me is what sense does it make to convert dates that are outside of the stata spec?
Comment From: jbrockmendel
i suspect with non-nano in place this may be resolved. could use a test.