Overview
Meta widely uses CGo, allowing Gophers to access a vast array of C++ libraries.
We previously advocated for the defer Close() pattern for C++ bounded objects; however, this defer call was frequently overlooked, leading to memory leaks as these objects resemble regular Go objects.
Consequently, we adopted automated memory management through runtime.AddCleanup.
Unfortunately, adding these cleanups incurs a performance penalty, specifically during the execution of the runtime.AddCleanup function.
Benchmark
Before implementing this change, we aimed to understand its performance implications.
Several online blog posts compare manual deallocation with runtime.SetFinalizer, highlighting the poor performance of finalizers. We conducted a similar benchmark using the brand new runtime.AddCleanup, introduced in Go 1.24.
While runtime.AddCleanup shows a 2x performance improvement, it still lags behind manual deallocation.
The following benchmark results on Go 1.25.0 on a MacBookPro M1 14" indicate approximately a 5x slowdown compared to manual deallocation (benchmarking on a Linux server yielded similar results):
BenchmarkAllocateFree-8 15169078 73.42 ns/op
BenchmarkAllocateDefer-8 15890224 75.04 ns/op
BenchmarkAllocateAddCleanup-8 3516811 359.7 ns/op
BenchmarkAllocateWithFinalizer-8 1739244 676.9 ns/op
For the benchmark code and additional results, please refer to podtserkovskiy/slow-addcleanup-repro
Further investigation
Delving deeper into this issue, we believe the root cause lies in the linear search within the sorted linked list of special objects on mspan, specifically in the *mspan.specialFindSplicePoint function. A CPU profile generated on Go 1.25rc2 with GOGC=off (for a less noisy picture, as it doesn't significantly affect the results) illustrates this:
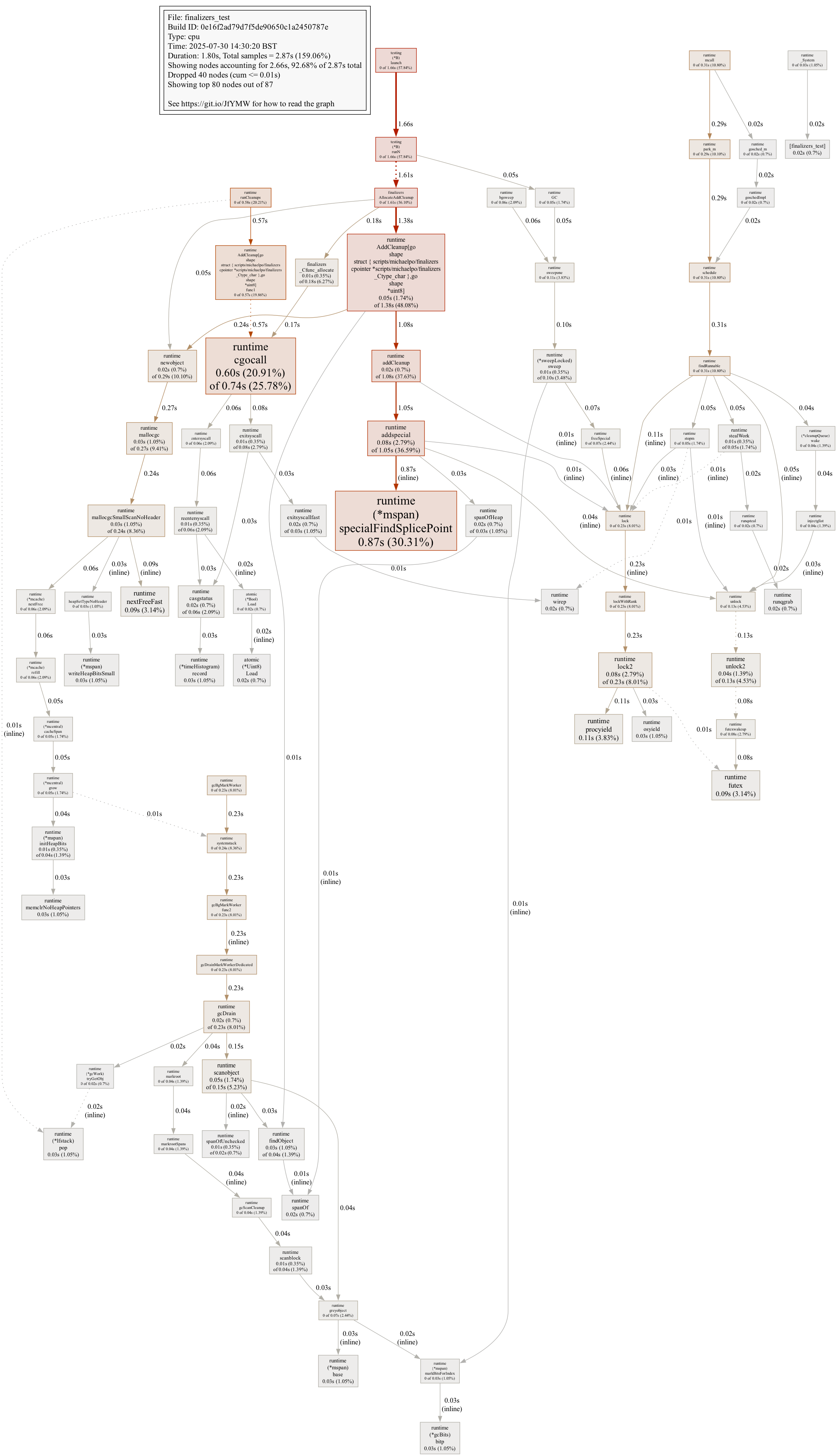
Is there a potential to accelerate the *mspan.specialFindSplicePoint function (e.g., by using a skip-list instead of a plain linked-list)?
Comment From: podtserkovskiy
cc @mknyszek
Comment From: mknyszek
I have some ideas on how to make this faster, at the cost of some memory overhead. What we brainstormed at GopherCon was essentially:
1. Add an optional array of pointers to each mspan which contains a pointer to the first special for each object.
2. Create this array on-demand, when the first object is added.
If the size of the array is a problem (as it might be for, say, 8 byte objects) we can also try compressing it. For example, doing a linked list of chunks with some special compact encoding.
The microbenchmark is maximally pessimal, since it forces a full walk of the linked list. In practice I suspect that it's not quite so bad, since the linked list for each span is going to be fairly short.
That being said, it's still not fast. How big are the objects that you're actually applying the cleanup to in production?