Bug description
We found a very ugly issue when connecting superset (version 4.0.2) to trino (476). A user has reported that superset is very slow and no query is processed sometimes. We found out that superset does not finish its queries when somebody selects a table (iceberg via trino) in the "SEE TABLE SCHEMA" dropdown. Combined with our resource pools (users can submit only 5 queries at a time, 6th will be queued) that's definitely a customer facing problem for us, so I'm seeking for help.
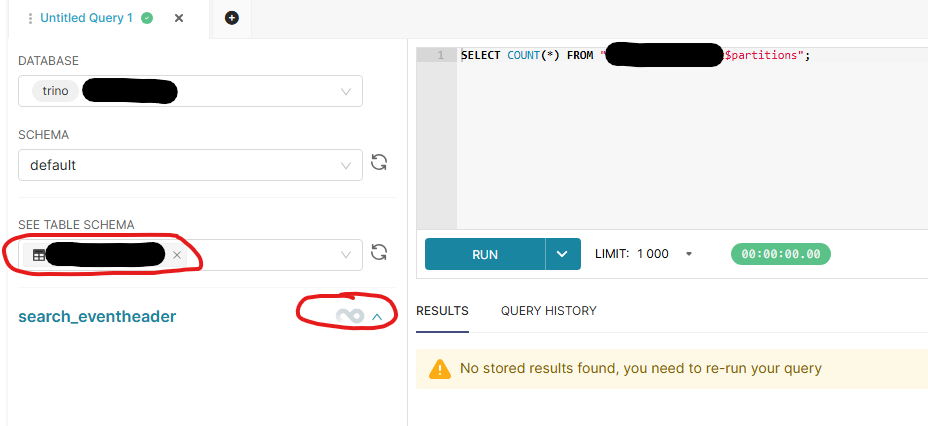
3 Queries to trino are fired from superset which are all the same. That's a thing I don't understand as well. Why 3 times the same query?
SELECT * FROM default."tablename$partitions"
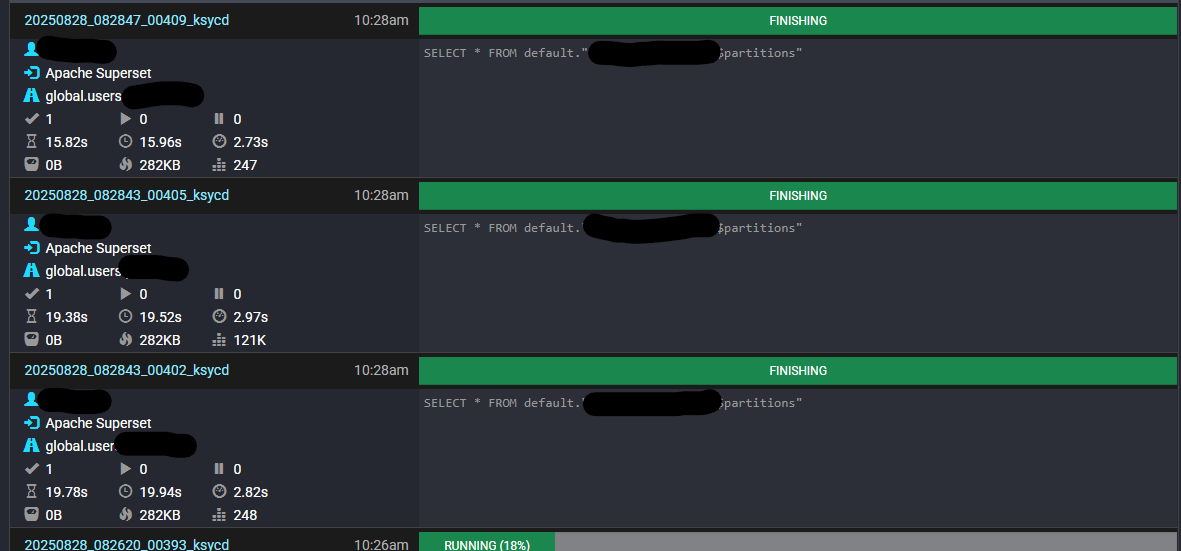
Superset already gets a result after couple of seconds and displays the table schema but the query stays in state "FINISHING" until a timeout of ~5mins is hit (which is the default query.client.timeout of trino). The query then is abandoned by trino itself.
io.trino.spi.TrinoException: Query 20250828_082847_00409_ksycd was abandoned by the client, as it may have exited or stopped checking for query results. Query results have not been accessed since 2025-08-28T08:28:49.874Z: currentTime 2025-08-28T08:33:50.786Z
at io.trino.execution.QueryTracker.failAbandonedQueries(QueryTracker.java:275)
at io.trino.execution.QueryTracker.lambda$start$0(QueryTracker.java:83)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.base/java.util.concurrent.FutureTask.runAndReset(Unknown Source)
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.base/java.lang.Thread.run(Unknown Source)
The tables have a bigger amount of partitions, we didn't manage to optimize them yet. Some of the tables have ~10.000 partitions (there are ugly reasons for that). Maybe that's relevant, but I don't think so because superset displays the schema just in time - it feels like just a thing of non terminating queries. According to trino, superset fetches ~10000 rows and 5mb from those queries within seconds.
We already checked with cilium-hubble for outgoing traffic from superset to trino while the query is still listed as FINISHING but it seems like the query becomes a zombie right after superset dissplays the table schema.
Please let me know if I can provide any further details
Screenshots/recordings
No response
Superset version
4.0.2
Python version
3.9
Node version
I don't know
Browser
Not applicable
Additional context
No response
Checklist
- [x] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [x] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [x] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: dosubot[bot]
Hi @maxgruber19! I'm Dosu and I’m helping the superset team.
This behavior happens because Superset, when introspecting Trino/Iceberg tables for schema info, issues partition metadata queries like SELECT * FROM ...$partitions as part of its engine-specific metadata fetching logic. The reason you see three identical queries is that Superset's schema introspection calls several metadata routines in sequence (such as fetching columns, indexes, and keys), each of which may trigger the same expensive partition query via SQLAlchemy reflection and the Trino engine spec. This is not unique to your setup and is a side effect of how Superset gathers table metadata for complex backends like Trino/Iceberg1.
The lingering "FINISHING" state in Trino is due to Superset fetching the results and then closing the connection without explicitly closing or cancelling the Trino query. Trino expects the client to either fetch all results or explicitly close the query; otherwise, it keeps the query alive until its timeout is reached. Superset relies on SQLAlchemy/DBAPI context managers for cleanup, which may not force a query kill on the Trino side, especially for large result sets or metadata queries1.
There is currently no explicit mechanism in Superset to close or cancel these metadata queries after schema introspection, and no recent changes in the codebase address this. The issue is more pronounced with large-partition Iceberg tables, as the partition metadata queries are expensive and can quickly exhaust Trino's resource pools if not cleaned up promptly1.
If this is causing operational issues, you might consider: - Reducing the number of partitions in your Iceberg tables if possible. - Increasing Trino's resource pool limits or lowering the query timeout. - Exploring if you can patch Superset's Trino engine spec to avoid redundant partition queries or to explicitly cancel them after fetching metadata.
To reply, just mention @dosu.
How did I do? Good | Irrelevant | Incorrect | Verbose | Hallucination | Report 🐛 | Other 


Comment From: sadpandajoe
@maxgruber19 do you get the same issues with Superset 4.1.X or 5.0.X?
Comment From: maxgruber19
@sadpandajoe I'll try upgrading the deployment and come back here again, thank you.
I was scanning the changelogs but didn't find anything related to my issue. Are there relevant changes you have in mind?
You will here from me!