Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[x] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
df = (pd.DataFrame({'a': list('ABBAAAB'),
'b': [-1,1,1,-2,float('nan'),3,-4]})
.assign(b_bin = lambda x:
pd.cut(x.b, bins=[-float('inf'), 0, float('inf')]))
.groupby(['b_bin', 'a'], as_index=False, observed=True, dropna=False)
.agg(b_sum = ('b', 'sum'), b_prod = ('b', 'prod'))
.pivot(index='a', columns='b_bin', values=['b_sum', 'b_prod'])
)
print(df)
df.to_excel('test.xlsx')
Issue Description
Hi,
I came across this issue at work when binning data (using pd.cut), then pivoting (creating a multi-level column structure) and finally writing to excel: If there are NaNs present in the categorical that is produced by pd.cut, in the print and .to_csv, the column structure is correct, while in the excel output the NaNs in the column labels are replaced by the last entry of the second-level column labels:

vs
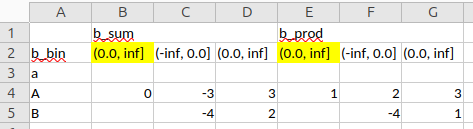
I have highlighted the buggy cells in the excel screenshot, note the difference to the screenshot above. It seems that the NaN gets replaced but whatever is in the last position of the second level column labels.
This bug does not occur when there is only a single level in the columns.
I came across this issue on a Windows machine at work but recreated the same behavior at home under Ubuntu. I tested on pandas 2.1.4, 2.3 and 3.0.
All the best Niclas
Expected Behavior
See the screenshot of the print(df) in the description.
Installed Versions
Comment From: justine202429
I'll take a look at this issue and see if I can come up with a fix with @mathbruu
Comment From: justine202429
take