The performance of array reductions in nanops/bottleneck can be significantly improved upon for large data using numba. The improvements are due to two factors:
- single-pass algorithms when null values are present and avoiding any copies.
- multi-threading over chunked of array or over an axis in a single axis reduction.
This screenshot demonstrates a potential 4x improvement on a DataFrame of 10-million rows and 5 columns of various types.
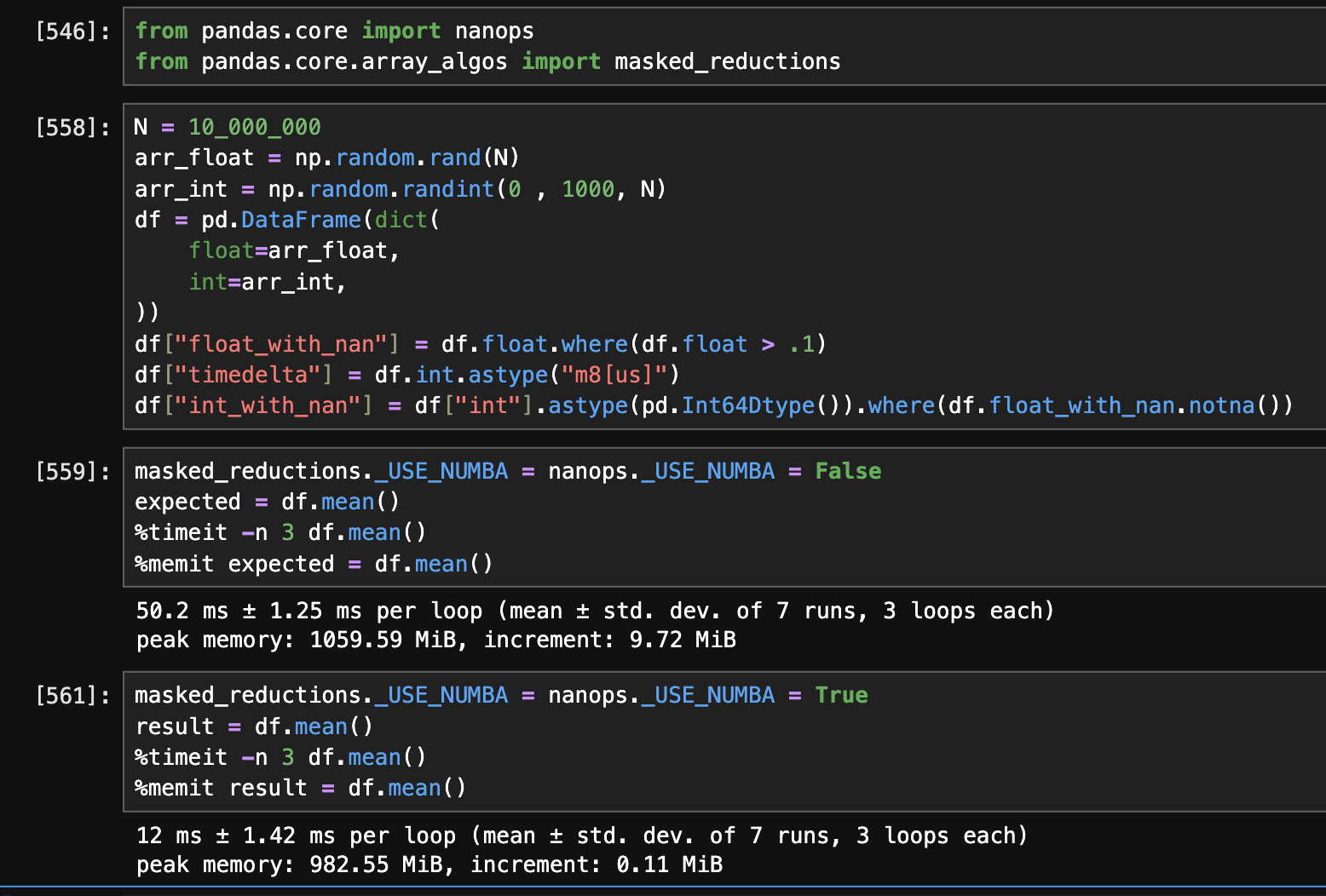
I am running the code on a features branch, and all unit tests for the feature branch are passing locally. https://github.com/eoincondron/pandas/tree/nanops-numba-implementation
The hardware is a new MacBook Pro with 8 cores.
The performance is still slightly better at 1-million rows and is even greater at larger magnitudes (8x at 100 million rows). The caveat is that all JIT-compilation is already completed. I have carried out a more comprehensive performance comparison and these results hold up.
Similarly to bottleneck, these codepaths can be toggled on and off.