When increasing the number of keys in IN clauses, the runtime of the query is sgnificantly increased. This means that queries with large numbers of keys are running for a very long time (several seconds for 200 keys), even though a direct query on the underlying database will terminate within milliseconds.
See discussion in Slack: https://apache-superset.slack.com/archives/C014LS99C1K/p1633448327074000
How to reproduce the bug
Precondition: Load an example dataset
- Go to 'Data' and open "Explore" your example dataset (e.g., birth_names from the example data)
- Click on 'Query Mode' > 'Raw Records' and add at least one column
- In Filters, click the Plus-button to add a new Filter - Custom SQL
- Enter a short
INquery with several keys, e.g. `name IN ("Liam", "James", "Noah", "Wyatt", "Gabriel", "Lucas", "Ethan", "Alexander", "Joseph", "Benjamin") - Enter a long
INquery with at hundrets of keys, e.g.,name IN ("Liam","James", "Noah", "Wyatt", "Gabriel", "Lucas", "Ethan", "Alexander", "Joseph", "Benjamin", "William", "Logan", "Mason", "Jack", "John", "Asher", "Elijah", "Daniel", "Henry", "Jacob", "Jaxon", "Michael", "Oliver", "Hunter", "David", "Levi", "Matthew", "Landon", "Aiden", "Isaac", "Jackson", "Caleb", "Ryan", "Elias", "Connor", "Evan", "Joshua", "Samuel", "Christian", "Jayden", "Jeremiah", "Cooper", "Eli", "Robert", "Ryder", "Christopher", "Colton", "Josiah", "Andrew", "Austin", "Carson", "Jaxson", "Jonathan", "Luke", "Malachi", "Nathan", "Owen", "Blake", "Lincoln", "Ezra", "Gavin", "Thomas", "Dylan", "Grayson", "Kai", "Ryker", "Zachary", "Anthony", "Isaiah", "Jase", "Jason", "Micah", "Sebastian", "Silas", "Titus", "Bentley", "Brody", "Cameron", "Carter", "Chase", "Gideon", "Jace", "Sawyer", "Tristan", "Tyler", "Weston", "Adam", "Charles", "Everett", "Wesley", "Xander", "Brandon", "Brayden", "Nathaniel", "Theodore", "Xavier", "Ashton", "Avery", "Dominic", "Easton", "Finn", "George", "Hudson", "Ian", "Jasper", "Kayden", "Marshall", "Max", "Maxwell", "Miles", "Orion", "Richard", "Timothy", "Abel", "Drake", "Garrett", "Jameson", "Jayce", "Joel", "Kenneth", "Maximus", "Nicholas", "Parker", "Travis", "Cody", "Dean", "Declan", "Elliot", "Ezekiel", "Karter", "Nolan", "Patrick", "Riley", "Seth", "Solomon", "Steven", "Victor", "Waylon", "Aaron", "August", "Bradley", "Braxton", "Bryce", "Calvin", "Camden", "Cayden", "Charlie", "Cole", "Damian", "Dawson", "Eric", "Greyson", "Jake", "Jeffrey", "Jesse", "Jonah", "Julian", "Kaiden", "Killian", "Kingston", "Maddox", "Matthias", "Maverick", "Odin", "Paul", "Peter", "Roman", "Trevor", "Zane", "Alex", "Archer", "Caden", "Collin", "Colt", "Edward", "Gage", "Gunner", "Harrison", "Ivan", "Jax", "Leo", "Lukas", "Marcus", "Paxton", "Soren", "Sullivan", "Tanner", "Trenton", "Troy", "Tucker", "Vincent", "Walter", "Warren", "Adrian", "Augustus", "Axel", "Beckett", "Cade", "Clayton", "Dante")(see a list of baby names here - Compare the computation times. Even though an in clause would return the data almost instantly
Expected results
Computation time is roughly similar, within a few milliseconds.
Actual results
In my local setup, the difference is:
Short IN query: 0.34 sec
Long IN query: 1.62 sec
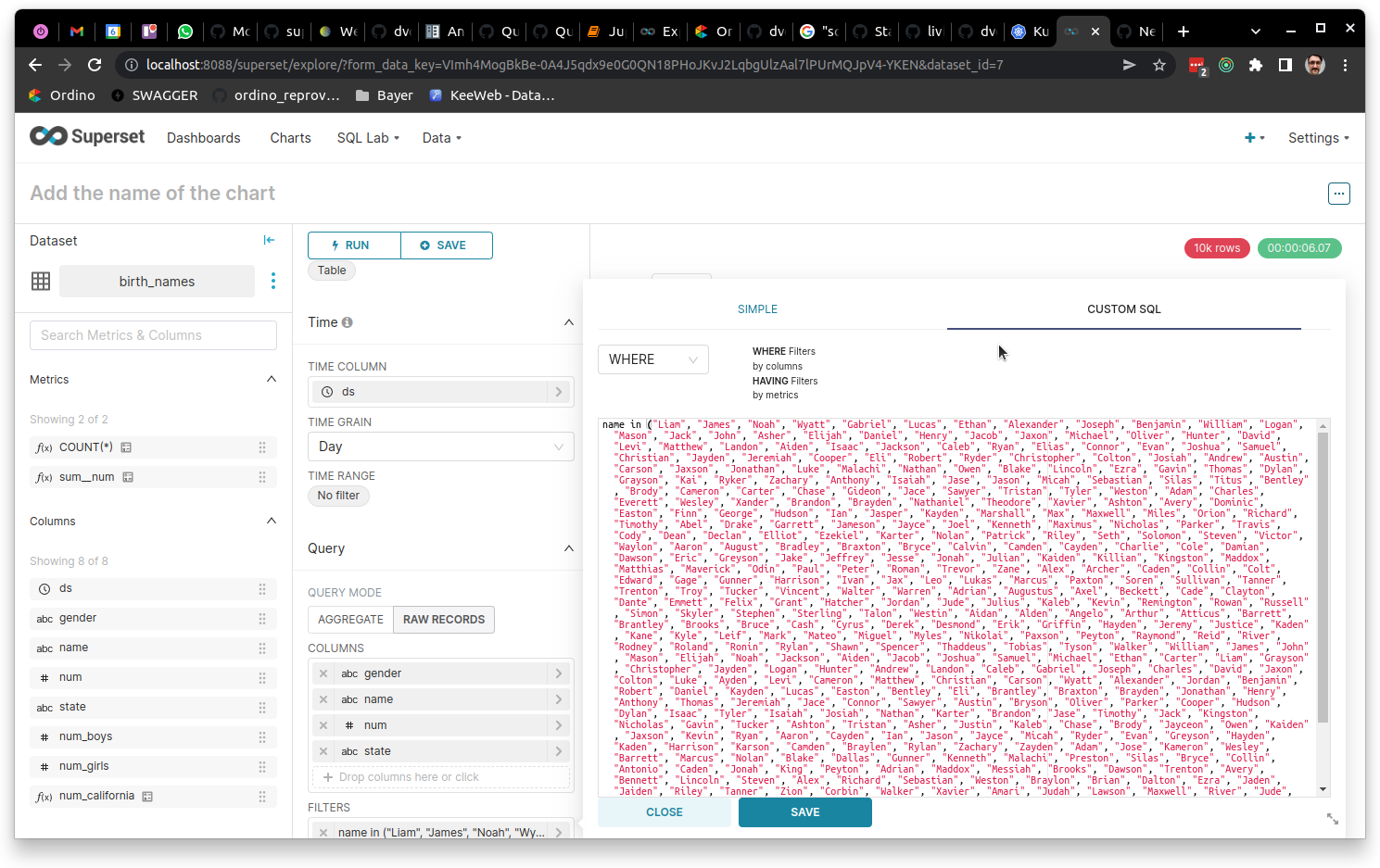
Even longer IN query: 6.07 sec
Upon adding more clauses, the runtime increases in quadratic time.
Screenshots
Short IN query (20 keys):
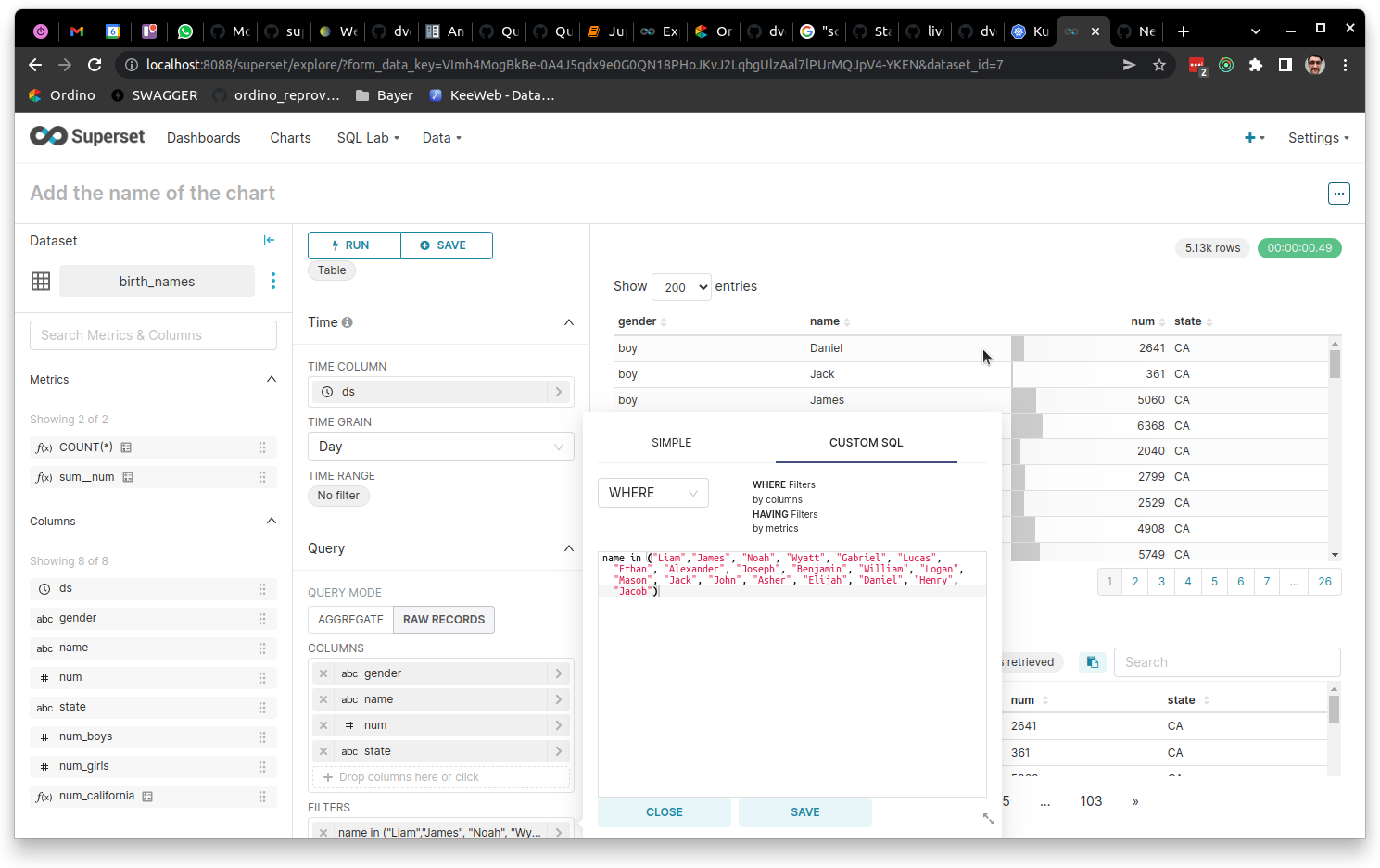
Long IN query (200 keys):
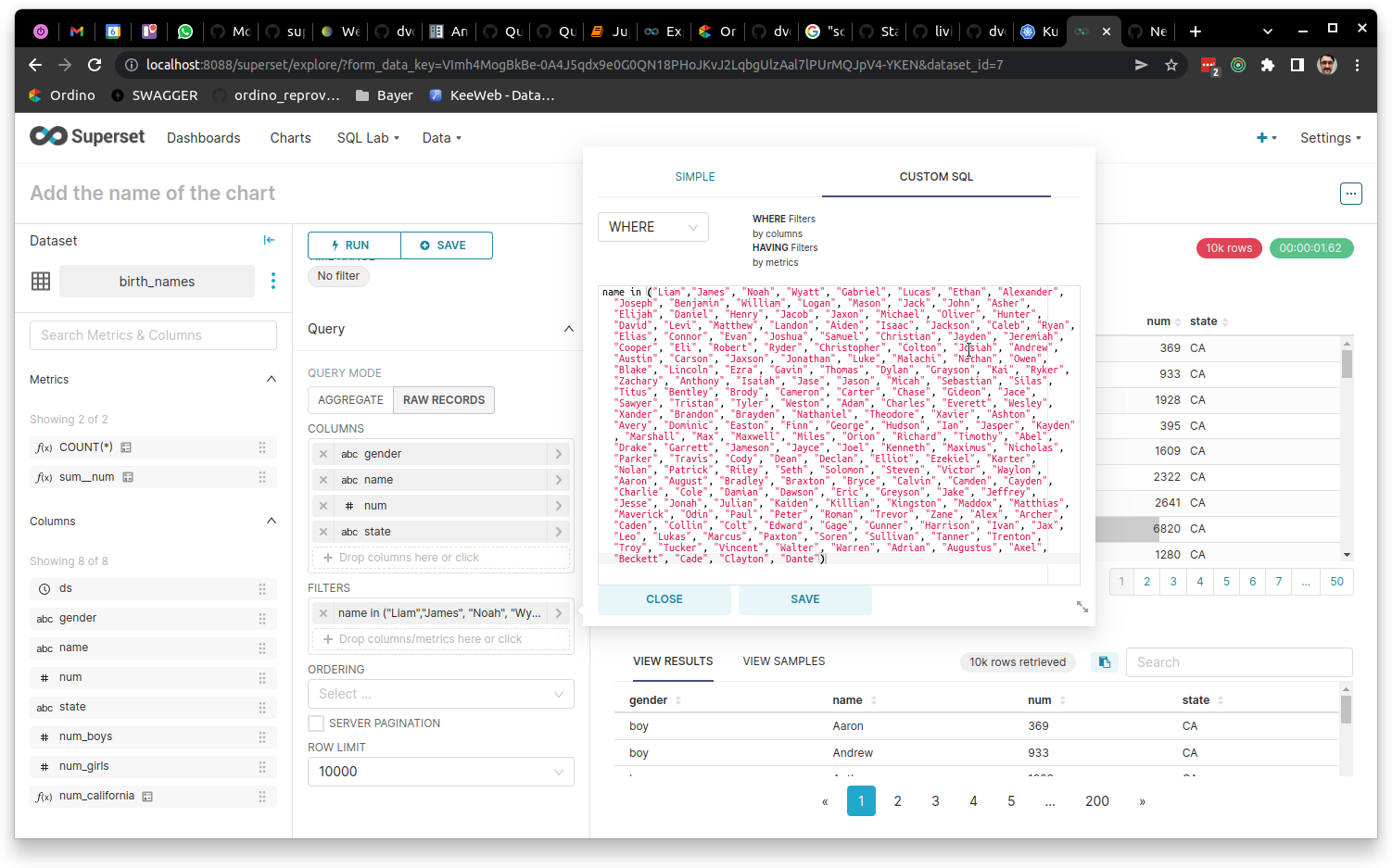
Even longer IN query (500 keys):
Environment
- browser type and version: Tested on Chrome: Version 100.0.4896.60 (Official Build) (64-bit)
- superset version: master branch commit 03d3eaacafc6ebdad7fdbcef6efa4df553468ba1
- python version: 3.8.10
- node.js version: v12.22.9
- any feature flags active: None
Checklist
Make sure to follow these steps before submitting your issue - thank you!
Additional context
The source of this quadratic runtime of the query is caused by both the sqlparse.parse and sqlparse.format functions called in numerous places (/models/core.py, db_engine_specs/base.py, connectors/sqla/models.py, and common/query_object.py)
Comment From: rusackas
Added a couple of reviewers (the folks from the Slack thread) as reviewers on the PR. Hopefully we can get this resolved! Thanks for the Issue and the Contribution!
Comment From: dvchristianbors
Added a couple of reviewers (the folks from the Slack thread) as reviewers on the PR. Hopefully we can get this resolved! Thanks for the Issue and the Contribution!
Thanks! The ticket and PR have been open for quite a while. The PR definitely needs to be revisited to see if it is still viable. There has also been a semi-recent release of the sqlparse package (0.4.3 in Sep 2022), so it could also be evaluated if the performance issues have been resolved.
Comment From: rusackas
I would close this as stale (we're trying to clean house) but maybe we can get that PR across the finish line. Are you able to validate whether things have improved, as of Superset 3.x?
Comment From: dvchristianbors
I have not tried to validate in Superset 3.x, but could try and do so.
Comment From: rusackas
That would be fantastic, thanks in advance!
Comment From: dvchristianbors
I can confirm that this issue still persists with the current main branch (commit 744f68d63784cf90a200db134655147641cef12f). I will work on bringing the PR up to date and re-request review.
Comment From: rusackas
A SIP has been passed to replace Sqlparse, and the work is in progress. We can close this if you'd like, but for the moment, I'll leave it open as long as the work remains in progress.
https://github.com/apache/superset/issues/26786
Comment From: rusackas
Tempted to close this as stale... but can anyone say if this is still an issue in 4.1.2 or 5.0.0?
Comment From: betodealmeida
Tester and this is now fine in master.