Bug description
Hi ,
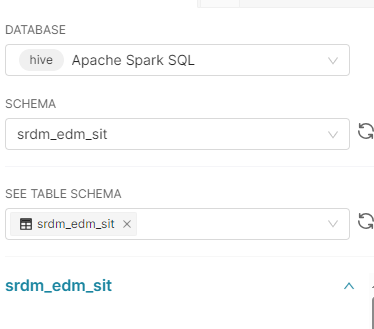
I deployed apache superset 4.0.1 in aws kubernetes cluster. A connection to the Spark Thrift Server was successfully established through Spark SQL via the Superset UI. The connection was confirmed to be working as expected. While executing the SHOW TABLES query in SQL Lab, it successfully retrieved results. However, when attempting to access the table schema section, an error occurred.
{ "message": "(pyhive.exc.OperationalError) TExecuteStatementResp(status=TStatus(statusCode=3, infoMessages=[\"org.apache.hive.service.cli.HiveSQLException:Error running query: org.apache.spark.sql.AnalysisException: Table or view not found: srdm_edm_sit.srdm_edm_sit; line 1 pos 9;\n'DescribeRelation false, [col_name#4361, data_type#4362, comment#4363]\n+- 'UnresolvedTableOrView [srdm_edm_sit, srdm_edm_sit], DESCRIBE TABLE, true\n:37:36\", 'org.apache.spark.sql.hive.thriftserver.HiveThriftServerErrors$:runningQueryError:HiveThriftServerErrors.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute:SparkExecuteStatementOperation.scala:325', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:runInternal:SparkExecuteStatementOperation.scala:216', 'org.apache.hive.service.cli.operation.Operation:run:Operation.java:277', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkOperation$$super$run:SparkExecuteStatementOperation.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:$anonfun$run$1:SparkOperation.scala:45', 'scala.runtime.java8.JFunction0$mcV$sp:apply:JFunction0$mcV$sp.java:23', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:withLocalProperties:SparkOperation.scala:79', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:withLocalProperties$:SparkOperation.scala:63', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:withLocalProperties:SparkExecuteStatementOperation.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:run:SparkOperation.scala:45', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:run$:SparkOperation.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:run:SparkExecuteStatementOperation.scala:43', 'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatementInternal:HiveSessionImpl.java:484', 'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatement:HiveSessionImpl.java:460', 'sun.reflect.GeneratedMethodAccessor142:invoke::-1', 'sun.reflect.DelegatingMethodAccessorImpl:invoke:DelegatingMethodAccessorImpl.java:43', 'java.lang.reflect.Method:invoke:Method.java:498', 'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:77', 'org.apache.hive.service.cli.session.HiveSessionProxy:access$000:HiveSessionProxy.java:35', 'org.apache.hive.service.cli.session.HiveSessionProxy$1:run:HiveSessionProxy.java:62', 'java.security.AccessController:doPrivileged:AccessController.java:-2', 'javax.security.auth.Subject:doAs:Subject.java:422', 'org.apache.hadoop.security.UserGroupInformation:doAs:UserGroupInformation.java:1878', 'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:58', 'com.sun.proxy.$Proxy37:executeStatement::-1', 'org.apache.hive.service.cli.CLIService:executeStatement:CLIService.java:280', 'org.apache.hive.service.cli.thrift.ThriftCLIService:ExecuteStatement:ThriftCLIService.java:456', 'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1557', 'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1542', 'org.apache.thrift.ProcessFunction:process:ProcessFunction.java:38', 'org.apache.thrift.TBaseProcessor:process:TBaseProcessor.java:39', 'org.apache.hive.service.auth.TSetIpAddressProcessor:process:TSetIpAddressProcessor.java:52', 'org.apache.thrift.server.TThreadPoolServer$WorkerProcess:run:TThreadPoolServer.java:310', 'java.util.concurrent.ThreadPoolExecutor:runWorker:ThreadPoolExecutor.java:1149', 'java.util.concurrent.ThreadPoolExecutor$Worker:run:ThreadPoolExecutor.java:624', 'java.lang.Thread:run:Thread.java:750', \"org.apache.spark.sql.AnalysisException:Table or view not found: srdm_edm_sit.srdm_edm_sit; line 1 pos 9;\n'DescribeRelation false, [col_name#4361, data_type#4362, comment#4363]\n+- 'UnresolvedTableOrView [srdm_edm_sit, srdm_edm_sit], DESCRIBE TABLE, true\n:70:34\", 'org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt:failAnalysis:package.scala:42', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:$anonfun$checkAnalysis$1:CheckAnalysis.scala:123', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:$anonfun$checkAnalysis$1$adapted:CheckAnalysis.scala:97', 'org.apache.spark.sql.catalyst.trees.TreeNode:foreachUp:TreeNode.scala:263', 'org.apache.spark.sql.catalyst.trees.TreeNode:$anonfun$foreachUp$1:TreeNode.scala:262', 'org.apache.spark.sql.catalyst.trees.TreeNode:$anonfun$foreachUp$1$adapted:TreeNode.scala:262', 'scala.collection.Iterator:foreach:Iterator.scala:943', 'scala.collection.Iterator:foreach$:Iterator.scala:943', 'scala.collection.AbstractIterator:foreach:Iterator.scala:1431', 'scala.collection.IterableLike:foreach:IterableLike.scala:74', 'scala.collection.IterableLike:foreach$:IterableLike.scala:73', 'scala.collection.AbstractIterable:foreach:Iterable.scala:56', 'org.apache.spark.sql.catalyst.trees.TreeNode:foreachUp:TreeNode.scala:262', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:checkAnalysis:CheckAnalysis.scala:97', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:checkAnalysis$:CheckAnalysis.scala:92', 'org.apache.spark.sql.catalyst.analysis.Analyzer:checkAnalysis:Analyzer.scala:182', 'org.apache.spark.sql.catalyst.analysis.Analyzer:$anonfun$executeAndCheck$1:Analyzer.scala:205', 'org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$:markInAnalyzer:AnalysisHelper.scala:330', 'org.apache.spark.sql.catalyst.analysis.Analyzer:executeAndCheck:Analyzer.scala:202', 'org.apache.spark.sql.execution.QueryExecution:$anonfun$analyzed$1:QueryExecution.scala:75', 'org.apache.spark.sql.catalyst.QueryPlanningTracker:measurePhase:QueryPlanningTracker.scala:111', 'org.apache.spark.sql.execution.QueryExecution:$anonfun$executePhase$1:QueryExecution.scala:183', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:775', 'org.apache.spark.sql.execution.QueryExecution:executePhase:QueryExecution.scala:183', 'org.apache.spark.sql.execution.QueryExecution:analyzed$lzycompute:QueryExecution.scala:75', 'org.apache.spark.sql.execution.QueryExecution:analyzed:QueryExecution.scala:73', 'org.apache.spark.sql.execution.QueryExecution:assertAnalyzed:QueryExecution.scala:65', 'org.apache.spark.sql.Dataset$:$anonfun$ofRows$2:Dataset.scala:98', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:775', 'org.apache.spark.sql.Dataset$:ofRows:Dataset.scala:96', 'org.apache.spark.sql.SparkSession:$anonfun$sql$1:SparkSession.scala:618', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:775', 'org.apache.spark.sql.SparkSession:sql:SparkSession.scala:613', 'org.apache.spark.sql.SQLContext:sql:SQLContext.scala:651', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute:SparkExecuteStatementOperation.scala:291'], sqlState=None, errorCode=0, errorMessage=\"Error running query: org.apache.spark.sql.AnalysisException: Table or view not found: srdm_edm_sit.srdm_edm_sit; line 1 pos 9;\n'DescribeRelation false, [col_name#4361, data_type#4362, comment#4363]\n+- 'UnresolvedTableOrView [srdm_edm_sit, srdm_edm_sit], DESCRIBE TABLE, true\n\"), operationHandle=None)\n[SQL: DESCRIBE srdm_edm_sit.srdm_edm_sit]\n(Background on this error at: https://sqlalche.me/e/14/e3q8)" }
How to reproduce the bug
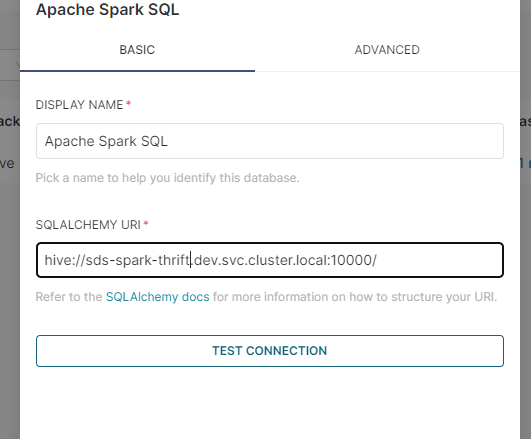
1.Added a database connection to Spark Thrift. During the connection test, it indicated that "the connection looks good."

Screenshots/recordings
No response
Superset version
master / latest-dev
Python version
3.9
Node version
Not applicable
Browser
Firefox
Additional context
No response
Checklist
- [X] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [ ] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [ ] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: dosubot[bot]
Hello, @aswathinj-pai! I'm here to help you with any bugs, questions, or contributions. Let's tackle this issue together!
I found a similar issue related to database connections and schema fetching in Apache Superset. In one case, users were unable to view tables under a specific schema due to the need to set the schema parameter in the Edit Tables form (Sources > Tables > Edit record) [1].
To address your issue, try the following steps:
- Set the Schema Parameter:
- Go to Sources > Tables in the Superset UI.
-
Edit the table record and set the schema parameter to the specific schema you are trying to access.
-
Verify the Connection String:
- Ensure that your SQLAlchemy URI is correctly formatted for the Spark Thrift Server. It should look something like this:
hive://hive@{hostname}:{port}/{database} -
Replace
{hostname},{port}, and{database}with your actual Spark Thrift Server details [1]. -
Check for Driver Issues:
- Make sure you have the
pyhivepackage installed, as it is required for connecting to Spark SQL via the Hive Thrift Server:bash pip install pyhive
If these steps do not resolve the issue, it might be related to a known limitation or bug in Apache Superset 4.0.1. For example, there are limitations with schema fetching and database connections for certain databases [2].
If the problem persists, you might want to check the Superset logs for more detailed error messages that could provide further insights.
To continue talking to Dosu, mention @dosu.
Comment From: aswathinj-pai
- Am not able to see Sources > Tables section as mentioned by the bot
- Test connection is successful after SQLAlchemy URI is provided.
- pyhive is already installed
Comment From: dosubot[bot]
If you are unable to see the "Sources > Tables" section in Apache Superset despite a successful connection test and having pyhive installed, it could be due to a few reasons:
-
Permissions: Ensure that the user has the necessary permissions to access the "Sources > Tables" section. Specifically, the user needs the can_list and can_show permissions on the Table model [1].
-
Database Configuration: Verify that the database ID (
pk) is correct and that theTablesDatabaseCommandis correctly implemented and executed without errors. Thetablesendpoint in theDatabaseRestApiclass is responsible for fetching the list of tables for a given database [2]. -
Implementation of
TablesDatabaseCommand: Ensure that theTablesDatabaseCommandis properly implemented and that there are no issues with its dependencies. The command should be able to fetch the list of tables and views from the database [3].
If these conditions are met and you still face issues, there might be a deeper configuration or permission problem that needs to be addressed.
To continue talking to Dosu, mention @dosu.
Comment From: aswathinj-pai
Am using admin user which already having all prossible permissions
Comment From: dosubot[bot]
I've hit a roadblock with this one, @rusackas, your insights would be highly valuable.
To continue talking to Dosu, mention @dosu.
Comment From: aswathinj-pai
Hi @rusackas , can you provide an update on this?
Comment From: aswathinj-pai
hi @rusackas , Any update on this?
Comment From: hiteshmusale
Hi @aswathinj-pai I am also stuck on similar issue with spark-sql connection Were you able to resolve it ?
Comment From: aswathinj-pai
@hiteshmusale No its not yet resolved. As an alternative ,used DBeaver to view the table.
Comment From: trongtruong2509
Hi @aswathinj-pai @hiteshmusale Any update on this? I believe I encountered same issue here. I connect Superset with Spark Thrift server, although I can query tables via superset SQL query and thrift beeline but when I tried to create dataset from the database connection, the existing tables did not shown, superset only display the table name AS A TABLE. And off course it will throw the error when the query for the non-existing table.
Comment From: rusackas
Sorry I don't have an answer for this... I don't have any access to Spark Thirft, so I can't reproduce it in order to fix it. If this is still an issue, I'd welcome anyone here to provide context updates, or open a PR. Do the tables show in the GUI (the left bar) or is this issue ONLY when you do a "SHOW TABLES" query?
Comment From: logicsys
im encountering the same problem, the tables drop downs seem to always populate with whatever the schema selected is, ie default.
I can however run SHOW TABLES in the SQL Lab, which works without issue: gives output in the results tab with columns:
namespace, tablename, isTemporary
is it possible theres an issue in parsing these columns? almost seems like superset is interpreting the namespace column only for some reason
Comment From: rodrigomsrocha
Hi! I’d like to share some additional context regarding this issue.
I’m connecting Apache Superset to a Kyuubi server, which exposes a Spark SQL environment via the Spark Thrift Server protocol. I’m using the following connection string (with LDAP authentication):
hive://user:password@host:port/spark_catalog?auth=LDAP
While I can successfully run SQL queries against my tables (both in SQL Lab and by manually creating datasets), Superset is not able to automatically list tables and columns in the database/schema browser. This means I cannot see or select tables/columns from the UI to easily create datasets—I’m only able to create them by writing SQL queries manually.
Additional context: - The same user/connection works perfectly in other BI tools (like Power BI), which are able to list tables and columns without issue, so it doesn’t appear to be a permissions problem. - The Spark/Kyuubi backend supports SHOW TABLES, SHOW DATABASES, and column metadata queries via the Thrift interface. - This seems to be a limitation or incompatibility between Superset’s database engine/driver and Kyuubi/Spark Thrift Server. - The problem occurs both with and without the spark_catalog parameter in the URI.
If you need any specific logs or connection details, I’m happy to provide them!