Bug description
Preconditions: Be connected to a Slack workspace with thousands of channels and even more archived channels.
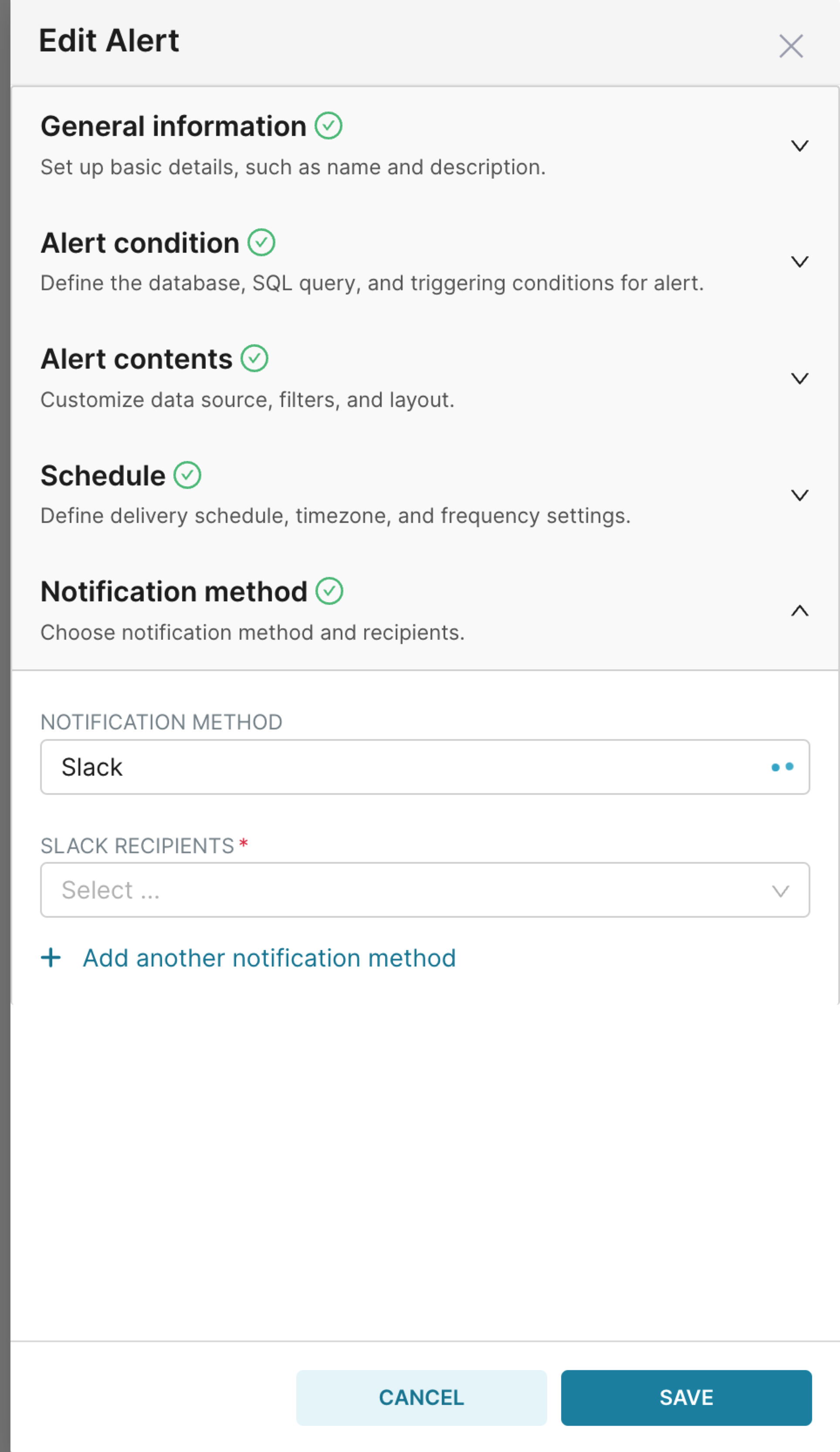
- Make sure Slack is connected (v1 or v2)
- Edit an alert and open the "Notification method" section
- Select Slack
Actual: The request to /api/v1/report/slack_channels/?... errors out with a rate-limit error from the Slack client.
Expected: User can select a channel/group without much delay.
Screenshots/recordings
Superset version
4.1.1
Python version
3.11
Node version
Not applicable
Browser
Chrome
Additional context
Why?
From what I could see this is due to Slack's implementation of the conversation.list endpoint. When the connected workspace has lots of archived channels, then the cursor will return far less conversations than specified in the request (using limit=999). This means we end up doing a lot of requests to fully iterate all conversations, eventually running into the rate-limit.
I applied a diff to properly handle rate-limit errors. This allows the request to eventually finish (6 minutes for our workspace) but it's not a great user experience 😆 (It may still be useful to add the rate-limit handler to preempt other Slack API issues).
diff --git a/superset/utils/slack.py b/superset/utils/slack.py
index 468429fb60..5d0cbfe507 100644
--- a/superset/utils/slack.py
+++ b/superset/utils/slack.py
@@ -22,6 +22,7 @@ from typing import Optional
from flask import current_app
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
+from slack_sdk.http_retry.builtin_handlers import RateLimitErrorRetryHandler
from superset import feature_flag_manager
from superset.exceptions import SupersetException
@@ -43,7 +44,12 @@ def get_slack_client() -> WebClient:
token: str = current_app.config["SLACK_API_TOKEN"]
if callable(token):
token = token()
- return WebClient(token=token, proxy=current_app.config["SLACK_PROXY"])
+ client = WebClient(token=token, proxy=current_app.config["SLACK_PROXY"])
+
+ rate_limit_handler = RateLimitErrorRetryHandler(max_retry_count=2)
+ client.retry_handlers.append(rate_limit_handler)
+
+ return client
def get_channels_with_search(
Options
- Update the Slack conversations asynchronously with a configurable Celery task and then use the cached conversation list when a user makes it to the edit alert window? Make sure rate-limiting errors are handled.
- Allow users to enter any string as recipient and map to a channel ID asynchronously?
- ...?
Checklist
- [x] I have searched Superset docs and Slack and didn't find a solution to my problem.
- [x] I have searched the GitHub issue tracker and didn't find a similar bug report.
- [x] I have checked Superset's logs for errors and if I found a relevant Python stacktrace, I included it here as text in the "additional context" section.
Comment From: dosubot[bot]
Hey there, @Usiel! I'm here to assist you with any bugs, questions, or contributions you have for Superset. Let's tackle this issue together!
To address the rate-limiting issue when retrieving Slack channels in large workspaces, you can consider the following approaches:
-
Implement Rate-Limit Handling: As you've already done, adding a
RateLimitErrorRetryHandlerto the Slack client is a good start. This will help manage rate-limit errors by retrying requests a limited number of times. You can adjust themax_retry_countto balance between retry attempts and user experience. -
Asynchronous Retrieval with Caching: Implementing a Celery task to fetch Slack channels asynchronously and cache the results can significantly improve performance. This way, when a user accesses the alert configuration, the application can quickly retrieve the cached list of channels without hitting the Slack API repeatedly. Ensure that the cache is updated periodically to reflect any changes in the Slack workspace.
-
User Input for Channel Selection: Allow users to manually enter a channel name or ID, which can then be validated and mapped to the correct channel asynchronously. This approach reduces the need to fetch all channels upfront and can be particularly useful in large workspaces.
-
Optimize API Calls: Consider optimizing the API calls by reducing the number of requests. For example, you can fetch only active channels or limit the number of channels retrieved per request to avoid hitting the rate limit quickly.
These strategies can help mitigate the rate-limiting issue and improve the user experience when configuring Slack notifications in Superset.
To continue talking to Dosu, mention @dosu.
Help Dosu learn! Give it feedback: Great Response | Irrelevant Answer | Incorrect Sources | Too Verbose | Hallucination | Bug Report | Other
Comment From: sadpandajoe
@Usiel how many channels does your slack workspace have. Unfortunately some of this is limited by the slack api itself since they only allow 1k in their api response with pagination and from the internet, it sounds like it may be rate limited to about 20 requests per minute. I think we don't currently look at archived channels but if we do, we can probably just add a flag, but if we aren't doing that a quick fix might be to add the flag as true according to the doc: https://api.slack.com/methods/conversations.list
Comment From: Usiel
We have around 20k channels, half of them archived. Interestingly, just now when I wanted to do some more probing, iterating all conversations took just a few seconds and only 16 requests. I can see in the logs that yesterday iterating all channels took 6 minutes and more than 200 (successful) requests, each with a distinct cursor (so these were not retried due to connectivity or similar). We saw this issue on 2 different Superset deployments in different datacenters owned by different teams (but connecting to the same Slack workspace).
Assuming this was just a temporary issue with Slack's API, the more extensive changes listed under "Options" are probably not necessary. Imo, the improvement to Superset's slack.utils.get_slack_client using Slack's rate-limit handler may still be a good addition. I can see about opening a PR for that.
Comment From: Usiel
I had an hourly celery task running Superset's get_channels_with_search(...) running since yesterday. Runtimes are between 10-30 seconds, indicating this may have been just a temporary issue.
I'm OK to close this issue unless someone else encountered the same degradation.
I will see about contributing the Slack rate-limit handler improvement soon-ish.
Comment From: Usiel
I encountered the problem again and realized my test (hourly celery task) inadvertently only requested public channels. I can reliably reproduce the issue when requesting private and public channels. The bot is member of just a single private channel. Iterating the full list takes again around 5-7 minutes.
For further testing I ran the get_channels_with_search(...) code different parameters. When private channels are requested the full iteration becomes incredibly slow and needs to pause multiple times due to rate-limiting.
exclude_archived=False, types='None'
=> requests=<order of 10>, len(channels)=<order of 10k>
exclude_archived=True, types='None'
=> requests=<order of 10>, len(channels)=<order of 10k>
exclude_archived=False, types='public_channel,private_channel'
=> requests=<order of 100>, len(channels)=<order of 10k> + 1
exclude_archived=True, types='public_channel,private_channel'
=> requests=<order of 100>, len(channels)=<order of 10k> + 1
Imo, this is an issue, I just don't know whether this affects many other Superset users :) I doubt Slack will optimize their API.
Comment From: sadpandajoe
Potential fix for this might be: https://github.com/apache/superset/pull/32529
Comment From: Usiel
Potential fix for this might be: https://github.com/apache/superset/pull/32529
Thank you, yes that looks promising and fixes it pretty much (well, not for the first user - they have to wait a few minutes 😆). I think we'd be golden if we exposed the caching function as a celery task, so it can run be part of the beat schedule. What do you think?
Comment From: rusackas
Did the merged PR indeed solve this issue?
Comment From: Usiel
Yes, it's not an issue anymore with https://github.com/apache/superset/pull/32529 and https://github.com/apache/superset/pull/32585.