There have been some discussions about this before, but as far as I know there is not a plan or any decision made.
My understanding is (feel free to disagree):
- If we were starting pandas today, we would only use Arrow as storage for DataFrame columns / Series
- After all the great work that has been done on building new pandas types based on PyArrow, we are not considering other Arrow implementations
- Based on 1 and 2, we are moving towards pandas based on PyArrow, and the main question is what's the transition path
@jbrockmendel commented this, and I think many others share this point of view, based on past interactions:
There's a path to making it feasible to use PyArrow types by default, but that path probably takes multiple major release cycles. Doing it for 3.0 would be, frankly, insane.
It would be interesting to know why exactly, I guess it's mainly because of two main reasons: - Finish PyArrow types and making operations with them as reliable and fast as the original pandas types - Giving users time to adapt
I don't know the exact state of the PyArrow types, and how often users will face problems if using them instead of the original ones. From my perception, there aren't any major efforts to make them better at this point. So, I'm unsure if the situation in that regard will be very different if we make the PyArrow types the default ones tomorrow, or if we make them the default ones in two years.
My understanding is that the only person who is paid consistently to work on pandas is Matt, and he's doing an amazing job at keeping the project going, reviewing most of the PRs, keeping the CI in good shape... But I don't think not him not anyone else if being able to put hours into developing new things as it used to be. For reference, this is the GitHub chart of pandas activity (commits) since pandas 2.0:
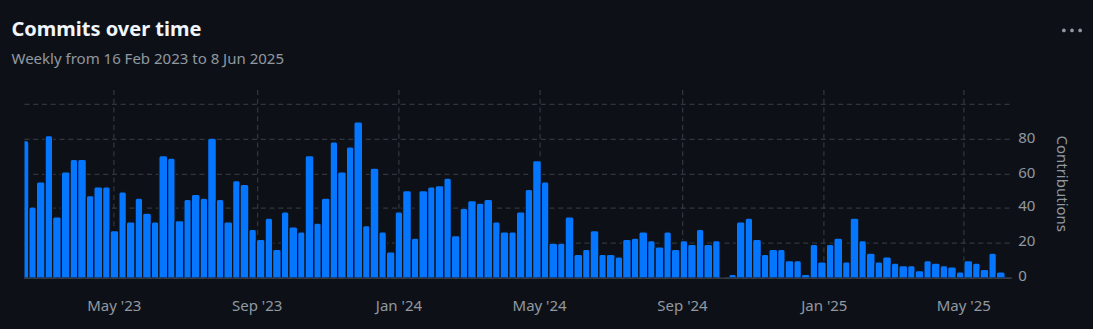
So, in my opinion, the existing problems with PyArrow will start to be addressed significantly, whenever they become the default ones.
So, in my opinion our two main options are:
- We move forward with the PyArrow transition. pandas 3.0 will surely not be the best pandas version ever if we start using PyArrow types, but pandas 3.1 will be much better, and pandas 3.2 may be as good as pandas 2 in reliability and speed, but much closer to what we would like pandas to be.
Of course not all users are ready for pandas 3.0 with Arrow types. They can surely pin to pandas=2 until pandas 3 is more mature and they made the required changes to their code. We can surely add a flag pandas.options.mode.use_arrow = False that reverts the new default to the old status quo. So users can actually move to pandas 3.0 but stay with the old types until we (pandas) and them are ready to get into the new default types. The transition from Python 2 to 3 (which is surely an example of what not to do) took more than 10 years. I don't think in our case we need as much. And if there is interest (aka money) we can also support the pandas 2 series while needed.
- The other option is to continue with the transition to the new nullable types, that my understanding is that we implemented because PyArrow didn't exist at that time. Continue to put our little resources on them. Making users adapt their code to a new temporary status quo, not the final one we envision, and stay in this transition period and delay the move to PyArrow I assume around 6 years (Brock mentioned
multiple major release cycles, so I assume something like 3 at a rate of one major release every 2 years).
It will be great to know what are other people's thoughts and ideal plans, and see what makes more sense. But to me personally, based on the above information, it doesn't sound more insane to move to PyArrow in pandas 3, than to move in pandas 6.
Comment From: jbrockmendel
Moving users to pyarrow types by default in 3.0 would be insane because #32265 has not been addressed. Getting that out of the way was the point of PDEP 16, which you and Simon are oddly hostile toward.
Comment From: mroeschke
Since I helped draft PDEP-10, I would like a world where the Arrow type system with NA semantics would be the only pandas type system.
Secondarily, I would like a world where pandas has the Arrow type system with NA semantics and the legacy (NaN) Numpy type system which is completely independent from the Arrow type system (e.g. a user cannot mix the two in any way)
I agree with Brock that null semantics (NA vs NaN) must inevitably be discussed with adopting a new type system.
I've also generally been concerned about the growing complexity of PDEP-14 with the configurability of "storage" and NA semantics (like having to define a comparison hierarchy https://github.com/pandas-dev/pandas/issues/60639). While I understand that we've been very cautious about compatibility with existing types, I don't think this is maintainable or clearer for users in the long run.
My ideal roadplan would be:
- In pandas 3.x
- Deprecate the NumPy nullable types
- Deprecate NaN as a missing value for Arrow types
- Deprecate mixing Arrow types and Numpy types in any operation
- Add some global configuration API,
set_option("type_system", "legacy" | "pyarrow"), that configures the "default" type system as either NaN semantics with NumPy or NA semantics with Arrow (with the default being"legacy")
- In pandas 4.x
- Enforce above deprecations
- Deprecate
"legacy"as the "default" type system
- In pandas 5.x
- Enforce
"pyarrow"as the new "default" type system
- Enforce
Comment From: jbrockmendel
Deprecate NaN as a missing value for Arrow types
So with this deprecation enforced, NaN in a constructor, setitem, or csv would be treated as distinct from pd.NA? If so, I’m on board but I expect that to be a painful deprecation.
Comment From: datapythonista
To be clear, I'm not hostile towards PDEP-16 at all. I think it's important for pandas to have clear and simple missing value handling, and while incomplete, I think the PDEP and the discussions have been very useful and insightful. Amd I really appreciate that work.
I just don't see PDEP-16 as a blocker for moving to pyarrow, even less if implemented at the same time. And also, I wouldn't spend time with our own nullable dtypes, I would implement PDEP-16 only for pyarrow types.
I couldn't agree more on the points Matt mentions for pandas 3.x. Personally I would change the default earlier. Sounds like pandas 4.x is mostly about showing a warning to users until they manually change the default, which I personally wouldn't do. But that's a minor point, I like the general idea.
Comment From: mroeschke
Deprecate NaN as a missing value for Arrow types
So with this deprecation enforced, NaN in a constructor, setitem, or csv would be treated as distinct from pd.NA?
Correct. Yeah I am optimistic that most of the deprecation would hopefully go into ArrowExtensionArray, but of course there are probably a lot of one-off places that need addressing.
I just don't see PDEP-16 as a blocker for moving to pyarrow
There is a lot of references about type systems in that PDEP that I think would warrant some re-imagining given which type systems are favored. As mentioned before (unfortunately) I think type systems and missing value semantics need to be discussed together
Comment From: datapythonista
I created a separate issue #61620 for the option mentioned in the description and in Matt's roadmap, since I think that's somehow independent, and no blocked by PDEP-15, by this issue, or by nothing else that I know.
There is a lot of references about type systems in that PDEP that I think would warrant some re-imagining given which type systems are favored. As mentioned before (unfortunately) I think type systems and missing value semantics need to be discussed together
I fully agree with this. But I'm not sure I fully understand why PDEP-16 must be a blocker for defaulting to PyArrow types.
For users already using PyArrow, they'll have to follow the deprecation transition if they are using NaN as missing. To me, this can be started in 3.0, 4.0 or whenever. And probably the earlier the better, so no more code is written with the undesired behavior.
For users not yet using PyArrow, I do understand that it's better to force the move when the PyArrow dtypes behave as we think they should behave. I'm not convinced this should be a blocker, and even less if the deprecation of the special treatment of NaN is also implemented in 3.0 or in the version when PyArrow types become the default. Maybe I'm wrong, but if you are getting data from parquet, csv... you are not immediately affected by this missing value semantics problems. You need to create data manually (rare for most professional use cases imho), or you need to be explicitly setting NaN in existing data (also rare in my personal experience). Am I missing something that makes this point important enough to be a blocker for moving to PyArrow and stop investing time in types that we plan to deprecate? If you have an example of code commonly used that is problematic for what I'm proposing, that can surely convince me, and help identify the optimal transition path.
Comment From: simonjayhawkins
Correct. Yeah I am optimistic that most of the deprecation would hopefully go into
ArrowExtensionArray, but of course there are probably a lot of one-off places that need addressing.
@mroeschke a couple of questions:
-
could the ArrowExtensionArray be described as a true extension array, i.e. using the extension array interface for 3rd party EAs.?
-
does the ArrowExtensionArray rely on any Cython code for the implementation to work?
Comment From: simonjayhawkins
Deprecate NaN as a missing value for Arrow types
So with this deprecation enforced, NaN in a constructor, setitem, or csv would be treated as distinct from pd.NA? If so, I’m on board but I expect that to be a painful deprecation.
I have always understood the ArrowExtensionArray and ArrowDtype to be experimental, no PDEP and no roadmap item, for the purpose of evaluating PyArrow types in pandas to potentially eventually use as a backend for pandas nullable dtypes.
So I can sort of understand why the ArrowDtypes are no longer pure and have allowed pandas semantics to creep into the API.
As experimental dtypes why do they need any deprecation at all? Where do we promote these types as pandas recommended types?
Comment From: simonjayhawkins
just to be clear about my previous statement, there is a roadmap item
Apache Arrow interoperability Apache Arrow is a cross-language development platform for in-memory data. The Arrow logical types are closely aligned with typical pandas use cases.
We'd like to provide better-integrated support for Arrow memory and data types within pandas. This will let us take advantage of its I/O capabilities and provide for better interoperability with other languages and libraries using Arrow.
but I've never interpreted this to cover adopting the current ArrowDtype system throughout pandas
Comment From: simonjayhawkins
My ideal roadplan would be:
@mroeschke given the current level of funding and interest for the development of the pandas nullable dtypes and the proportion of core devs that now appear to favor embracing the ArrowDtype instead, I fear that this may be, at this time, the most pragmatic approach in keeping pandas development moving forward as it does seem to have slowed of late. I'm not necessarily comfortable deprecating so much prior effort but then the same could have been said about Panel many years ago and I'm not sure anyone misses it today. If the community wants nullable dtypes by default, they may be less interested in the implementation details or even to some extent the performance. If the situation changes and there is more funding and contributions in the future and we have released a Windows 8 in the meantime then we could perhaps bring back the pandas nullable types.
Comment From: WillAyd
The goal of this and PDEP-13 were pretty aligned; prefer PyArrow to build out our default type system where applicable, and fill in the gaps using whatever we have as a fallback. That PDEP conversation stalled; not sure if its worth reviving or if this issue is going to tackle a smaller subset of the problem, but in any case I definitely support this
Comment From: mroeschke
But I'm not sure I fully understand why PDEP-16 must be a blocker for defaulting to PyArrow types.
@datapythonista I just would like some agreement that that defaulting to PyArrow types also matches PDEP-16's proposal to (only) NA semantics for this type as well when making the change for a consistent story, but I suppose they don't need to be done at the same time
could the ArrowExtensionArray be described as a true extension array, i.e. using the extension array interface for 3rd party EAs.?
@simonjayhawkins yes, it purely uses ExtensionArray and ExtensionDtype to implement functionality.
does the ArrowExtensionArray rely on any Cython code for the implementation to work?
It does not, and ideally it won't. When interacting with other parts of Cython in pandas, e.g. groupby, we've created hooks to convert to numpy first.
As experimental dtypes why do they need any deprecation at all? Where do we promote these types as pandas recommended types?
This is a valid point; technically it shouldn't require deprecation.
While our docs don't necessarily state a recommended type, anecdotally, it has felt like in past year or two there's been quite a number of conference talks, blogs posts, books that have "celebrated" the newer Arrow types in pandas. Although attention != usage, it may still warrant some care if changing behavior IMO.
If the situation changes and there is more funding and contributions in the future and we have released a Windows 8 in the meantime then we could perhaps bring back the pandas nullable types.
An alternative to completely deprecating and removing the pandas NumPy nullable types is to spin them off into their own repository & package and treat them like any other 3rd party ExtensionArray library for users that still want to use them.
Comment From: simonjayhawkins
If the situation changes and there is more funding and contributions in the future and we have released a Windows 8 in the meantime then we could perhaps bring back the pandas nullable types.
An alternative to completely deprecating and removing the pandas NumPy nullable types is to spin them off into their own repository & package and treat them like any other 3rd party
ExtensionArraylibrary for users that still want to use them.
we have a roadmap item:
Extensibility Pandas extending.extension-types allow for extending NumPy types with custom data types and array storage. Pandas uses extension types internally, and provides an interface for 3rd-party libraries to define their own custom data types.
Many parts of pandas still unintentionally convert data to a NumPy array. These problems are especially pronounced for nested data.
We'd like to improve the handling of extension arrays throughout the library, making their behavior more consistent with the handling of NumPy arrays. We'll do this by cleaning up pandas' internals and adding new methods to the extension array interface.
the roadmap also states
pandas is in the process of moving roadmap points to PDEPs
so we could perhaps have a separate issue on this (perhaps culminating in a PDEP to clear this off that list) to address any points to make the spin off easier?
Comment From: simonjayhawkins
But I'm not sure I fully understand why PDEP-16 must be a blocker for defaulting to PyArrow types.
@datapythonista I just would like some agreement that that defaulting to PyArrow types also matches PDEP-16's proposal to (only) NA semantics for this type as well when making the change for a consistent story, but I suppose they don't need to be done at the same time
In the absence of a competing proposal, I think you should proceed assuming that PDEP-16 is going to be accepted someday. A stale PDEP cannot be allowed to hold up development in other areas, especially if you have the bandwidth and resources to move forward on this.
Comment From: simonjayhawkins
@mroeschke
- Deprecate the NumPy nullable types
just to be clear, Int, Float, Boolean and pd.NA variants of StringArray only?
Deprecate mixing Arrow types and Numpy types in any operation
does that include numpy object type?
Comment From: Dr-Irv
I'm going to throw out another (possibly crazy) idea based on these comments:
If we were starting pandas today, we would only use Arrow as storage for DataFrame columns / Series
An alternative to completely deprecating and removing the pandas NumPy nullable types is to spin them off into their own repository & package and treat them like any other 3rd party ExtensionArray library for users that still want to use them.
The idea is as follows:
1. We create a new repository corresponding to what is in pandas 2.3 - let's call it npandas ("n" indicating "numpy-based")
2. pandas 3.0 goes fully PyArrow - removes the numpy storage and removes the nullable extension types
We only do bug fixes to npandas - so if people want to use the numpy types or nullable types, they use that version.
If they want "modern" pandas, they fully buy into pandas 3.0 and PyArrow support - requiring pyarrow and start working with the future.
Then we don't have to worry about a transition path that WE maintain. The transition is up to the users. They can take working code with npandas 2.3 and try pandas 3.0, and report issues in converting from npandas 2.3 to pandas 3.0. But we don't have to keep all these code paths working - we have 2 separate projects.
Comment From: WillAyd
Generally curious but why do we feel the need to remove the extension types? If anything, couldn't we just update them to use PyArrow behind the scenes?
I realize we use the term "numpy_nullable" throughout, but conceptually there's nothing different between what they and their corresponding Arrow types do. The Arrow implementation is just going to be more lightweight, so why not update those in place and not require users to change their code?
Comment From: datapythonista
All proposals and discussion points so far seem very interesting. Personally I think it's great we are having this conversation.
Based on the feedback above, what makes most sense to me is:
- Require PyArrow in 3.0
- We deprecate the NaN behavior in Arrow types. Correct me if I'm wrong, but I think it's not a huge effort, Bodo will probably fund the development, and Brock and Simon have availability to do it
- We default to PyArrow dtypes starting in 3.0, but we provide a global flag (e.g.
pandas.options.mode.use_legacy_typing)for users who aren't ready to use the Arrow types.
This wouldn't take us to a perfect situation, but it makes the transition path very easy for both users and us, and we can start focussing on pandas backed by Arrow, while gathering feedback from users quite fast without creating them any inconvenient (other that adding a line of code setting the option). After getting the feedback we will be in a better position to decide on deprecating the legacy types, moving them to a separate repo, maintaining them forever...
Comment From: mroeschke
@simonjayhawkins
just to be clear, Int, Float, Boolean and pd.NA variants of StringArray only?
Yes and I'd say all variants of StringArray (ArrowExtensionArray supports all functionality of StringArray)
does that include numpy object type?
I would say yes.
Comment From: jbrockmendel
We default to PyArrow dtypes starting in 3.0, but we provide a global flag
3.0 is already huge (CoW, Strings) and way, way late. Let's not risk adding another year to that lateness.
Comment From: jbrockmendel
We deprecate the NaN behavior in Arrow types. Correct me if I'm wrong, but I think it's not a huge effort, Bodo will probably fund the development, and Brock and Simon have availability to do it
Deprecating that behavior is relatively easy (though I kind of expect @jorisvandenbossche to chime in that we're missing something important). The hard part is the step after that telling users they have to change all their existing ser[1] = np.nan to use pd.NA instead (and constructor calls, and csvs).
As to "huge effort", off the top of my head, some tasks that would be required in order to make pyarrow dtypes the default include:
a) making object, category, interval, period dtypes Just Work b) changing the non-numeric Index subclasses to use pyarrow dtypes c) updating all the tests to work with both/all backend global options. Even if all the non-test code is bug-free, this is months of work. d) (longer-term) try to ameliorate the performance hit for axis=1 operations, arithmetic, etc
Comment From: datapythonista
Thanks @jbrockmendel, this is great feedback.
Do you think implementing the global option (without defaulting to arrow or fixing the above points) is reasonable for 3.0 (releasing it soon)?
For numpy nullable types, does that same list apply? Or just the work on missing value semantics is needed to consider them ready to be the default?
Comment From: jbrockmendel
Everything except the performance would need to be done regardless of the default.
Comment From: jorisvandenbossche
Trying to catch up with all discussions .. but already two quick points of feedback:
1) Timing:
We default to PyArrow dtypes starting in 3.0
3.0 is already huge (CoW, Strings) and way, way late. Let's not risk adding another year to that lateness.
I agree with @jbrockmendel here. Personally I would certainly not consider any of this for 3.0. There is still lots of work to do before we can even consider making the pyarrow dtypes the default (right now users cannot even try to this out fully), which I think will easily take at least a year. (and saying that as the person who caused a year of delay for 3.0 thinking we could "quickly" include the string dtype feature in pandas 3.0 at a point where we were otherwise already ready to release ...)
2) General approach of the "PyArrow dtypes":
Personally, I would prefer that we go for the model chosen for the StringDtype, i.e. not necessarily the fact that there are multiple backends (or the na_value), but I mean the fact that we went for a pd.StringDtype() as the default dtype and not for pd.ArrowDtype(pa.large_string()).
We should make good use of the Arrow type system, but IMO we 1) should not necessarily expose all of its details to our users (e.g. string vs large_string vs string_view, but have a default "string" dtype (with potentially options for power users than want to customized it)), and so I think we should hide some implementation details of (Py)Arrow under a nice "pandas logical dtype" system (i.e. @WillAyd's PDEP), and 2) by having separate classes per "type" of dtype, we can also provide a better user experience (e.g. a datetime/timestamp dtype will have a timezone attribute, but numeric dtypes don't need this).
As another example of this, I think we should create a variant of pd.CategoricalDtype that is nullable and uses pyarrow under the hood, and not have people rely on the fact that this translates to pd.ArrowDtype(pa.dictionary(...))
(in the line of what Brock said above about "making object, category, interval, period dtypes Just Work")
Comment From: simonjayhawkins
Thanks @jorisvandenbossche
2. General approach of the "PyArrow dtypes":
This aligns with my expectation of the future direction of pandas. Do we have any umbrella discussion anywhere that could be used as the basis of a PDEP so this is on the roadmap. (note: I'm not in any way volunteering to take that on)
I don't think PDEP-16 covers the using of pyarrow as a backend only and hiding the functionality behind our pandas nullable types as it is focused on the missing value semantics. Now, I appreciate that is part of that plan, but is not the plan as a roadmap item.
But to be fair, ArrowDType was introduced without a PDEP or IMO a roadmap item that covered what was implemented. As said above, these types have been promoted at conferences etc and are potentially being actively used. This is now IMO pulling the development team in two different directions. For instance, I am very frustrated at the ArrowDType for string being available to users as it has caused so much confusion even within the team. IMO we don't need this as "experimental" since we have the pandas nullable dtype available. However, I also appreciate that for evaluating an experimental dtype system (not just individual dtypes) we should perhaps include it. So I am conflicted.
Now we are where we are. And we probably now have as many (or more) core-devs that appear to favor the ArrowDtype system. So managing that is now likely as difficult as the technical discussions themselves.
@mroeschke please don't take this as criticism as the work you have done is great (for the whole project, the maintenance and not just the Arrow work) and any issues that have arisen are systematic failures. As @WillAyd pointed out the PDEP process needs to be able to allow to make decisions without every minute detail ironed out before the PDEP is approved.
Comment From: datapythonista
Thanks all for the feedback. Personally feels like while opening so many discussions have been a bit chaotic (sorry about that as I started or reopened most), I think it's been very productive.
I'd like to know how do you feel about trying to unify all the type system topics into a single PDEP that broadly defines a roadmap for the next steps and final goal. Maybe I'm too optimistic, but I think there is agreement in most points, and it's just the details that need to be decided. Some of the things that I think could go into the PDEP and there is mostly agreement:
- "Final" pandas dtypes backed by arrow (probably also agreement on not exposing it to the user)
- Eventually making PyArrow a required dependency (unclear when)
- Implementing a global option to at least change between the status quo and the final dtype system (maybe other options)
- The PyArrow dtypes still need work before being the default/final:
- NA semantics
- Functionality not yet implemented
- Bugs / undesired behavior
- Performance
- We should be testing the final PyArrow type system via our test suite with the global option (this can lead the work on what needs to be fixed)
- There should be a transition path from the status quo to the final types system that needs to be defined
- We need to take into consideration that we have around 500 work hours of funding, and that if things don't change, it doesn't seem likely that anyone will put the huge amount of time this needs to finish the roadmap
Does people feel like it make sense to write a PDEP with the general picture of this roadmap (that should superseed this issue, PDEP-15 and probably others)? Does anyone want to lead the effort to get this PDEP done?
Comment From: mroeschke
please don't take this as criticism as the work you have done is great
None taken :) . Yes, the development of these types preceded our agreed-upon approval process for larger pandas enhancements.
Personally, I would prefer that we go for the model chosen for the StringDtype
FWIW, the early model of ArrowDtype almost followed a variant of the StringDtype model (https://github.com/pandas-dev/pandas/pull/46972). I have come to like the benefits of the current ArrowDtype (probably with some bias), but I'll argue my case in a different forum.
Comment From: simonjayhawkins
FWIW, the early model of
ArrowDtypealmost followed a variant of theStringDtypemodel (#46972). I have come to like the benefits of the currentArrowDtype(probably with some bias), but I'll argue my case in a different forum.
Surely, this is that forum? (From the title of the discussion)
I think that we should have another discussion for pandas nullable dtypes by default, which arguably is already opened #58243?
@mroeschke you have come up with a proposed (maybe seen as alternative) roadmap and I for one am more than happy to give it serious consideration. To do this IMO we must keep the discussion about pandas nullable types in a different thread. Discussion is good. With respect to bias, not a problem in this thread. To actively participate in this discussion I need to avoid any bias that I may have towards the pandas nullable types arising from my involvement in the pd.NA variant of the string array.
In my head, I can see a path that allows both to progress in parallel avoiding conflict. I'll elaborate later when I can present it as a coherent plan. (it involves separation of type systems as you have suggested, some deprecations as you have suggested but not removals, instead moving things behind flags as suggested) - A pure arrow approach and a cuddly wrapped one. Now that users have already been exposed to the more "raw" types, users may not needed to be shielded from this to the same extent and that could indeed be a path to the pandas nullable types. We may need to recognize the realities on the ground to come to a resolution with respect to the natural evolution and adoption of the ArrowDtype, the current level of funding and more importantly what we would have approval to use the funds for and lastly the decline in contributions of late and therefor the realistic speed of progress/interest on the nullable types.
Comment From: simonjayhawkins
does that include numpy object type?
I would say yes.
df = pd.DataFrame(
{
"int": pd.Series([1, 2, 3], dtype=pd.ArrowDtype(pa.int64())),
"str": pd.Series(["a", "b", pd.NA], dtype=pd.ArrowDtype(pa.string())),
}
)
print(df)
# int str
# 0 1 a
# 1 2 b
# 2 3 <NA>
res = df.iloc[2]
res
# int 3
# str <NA>
# Name: 2, dtype: object
res.dtype
# dtype('O')
res["int"]
# 3
type(res["int"])
print(df.T)
# 0 1 2
# int 1 2 3
# str a b <NA>
df.T.dtypes
# 0 object
# 1 object
# 2 object
# dtype: object
So loc/iloc and transpose, and along with other axis=1 operations, on a heterogeneous dataframe of arrow only types, currently return a numpy array of Python objects. Numpy object dtype with pd.NA doesn't really work so well IMO.
How would we avoid numpy object dtype in a arrow only dtype system? Breaking API changes to the return types of iloc/loc? A nullable object dtype? having pyarrow scalars in the numpy array instead? ....
Comment From: Dr-Irv
So
loc/ilocand transpose, and along with other axis=1 operations, on a heterogeneous dataframe of arrow only types, currently return a numpy array of Python objects. Numpyobjectdtype with pd.NA doesn't really work so well IMO.
That happens with the nullable types as well:
>>> sa = pd.Series([1,2,pd.NA], dtype="Int64")
>>> sb = pd.Series([1.1, pd.NA, 2.2], dtype="Float64")
>>> sc = pd.Series([pd.NA, "v2", "v3"], dtype="string")
>>> df = pd.DataFrame({"a":sa, "b":sb, "c": sc})
>>> df
a b c
0 1 1.1 <NA>
1 2 <NA> v2
2 <NA> 2.2 v3
>>> df.T
0 1 2
a 1 2 <NA>
b 1.1 <NA> 2.2
c <NA> v2 v3
>>> df.T.dtypes
0 object
1 object
2 object
dtype: object
And even with the numpy types:
>>> san = pd.Series([1,2,3], dtype="int")
>>> sbn = pd.Series([1.1, np.nan, 2.2], dtype="float")
>>> scn = pd.Series([np.nan, "v2", "v3"])
>>> dfn = pd.DataFrame({"a":san, "b":sbn, "c": scn})
>>> dfn.dtypes
a int64
b float64
c object
dtype: object
>>> dfn.T
0 1 2
a 1 2 3
b 1.1 NaN 2.2
c NaN v2 v3
>>> dfn.T.dtypes
0 object
1 object
2 object
dtype: object
>>> dfn.iloc[0]
a 1
b 1.1
c NaN
Name: 0, dtype: object
So here in dfn.iloc[0], we have an integer, a float and np.nan, and we infer the dtype as object
Comment From: jbrockmendel
in a pyarrow-mode world, what happens if i want to include a 3rd party EA column that isn't pyarrow-based?
Comment From: simonjayhawkins
Personally, I would prefer that we go for the model chosen for the
StringDtype, i.e. not necessarily the fact that there are multiple backends (or thena_value), but I mean the fact that we went for apd.StringDtype()as the default dtype and not forpd.ArrowDtype(pa.large_string()). We should make good use of the Arrow type system, but IMO we 1) should not necessarily expose all of its details to our users (e.g. string vs large_string vs string_view, but have a default "string" dtype (with potentially options for power users than want to customized it)), and so I think we should hide some implementation details of (Py)Arrow under a nice "pandas logical dtype" system (i.e. @WillAyd's PDEP), and 2) by having separate classes per "type" of dtype, we can also provide a better user experience (e.g. a datetime/timestamp dtype will have a timezone attribute, but numeric dtypes don't need this).
@jorisvandenbossche
can you elaborate on what work has actually been done on using PyArrow as a backend to the existing pandas nullable types.
Is it only the StringArray so far?
Comment From: simonjayhawkins
I'd like to know how do you feel about trying to unify all the type system topics into a single PDEP that broadly defines a roadmap for the next steps and final goal.
@datapythonista
I think this may be a big ask at this time. I think that we may need compare 2 alternative directions to find the most preferred approach rather than trying to unify the two at this time. (I think that ultimately we would need to unify the two to keep cohesion within the team)
@mroeschke wrote
I would like a world where the Arrow type system with NA semantics would be the only pandas type system.
and from this discussion about considering PyArrow as the default, it could be fair to say that the idea is that if pandas were designed today, it would use Arrow for column storage.
Where we are today is that significant work has already been done to build new pandas types based on PyArrow, perhaps suggesting a future where pandas is underpinned by Arrow instead of legacy NumPy types.
AFAICT this work is mainly the work on the ArrowDType and apart from the StringDtype there has been no/little progress/interest in using PyArrow for storage in the pandas nullable types.
@mroeschke also wrote
Secondarily, I would like a world where pandas has the Arrow type system with NA semantics and the legacy (NaN) Numpy type system which is completely independent from the Arrow type system (e.g. a user cannot mix the two in any way)
interpreting @jorisvandenbossche comment, mixing the two was arguably a goal of PDEP-13. This effort stalled and so arguably would need to be resurrected if we did not instead consider a roadmap where the type systems were perhaps instead considered as completely independent. So applying @mroeschke comment to pandas nullable types as well - i..e a pandas nullable type system which is completely independent from the Arrow type system (e.g. a user cannot mix the two in any way)
Comment From: simonjayhawkins
@mroeschke
My ideal roadplan would be:
In pandas 3.x
Deprecate the NumPy nullable types
We need to acknowledge that this would be contentious.
- Deprecate NaN as a missing value for Arrow types
This would perhaps make the transition to ArrowDtype less straightforward for existing users but after the initial pain, the resulting type system will be more maintainable? Can you perhaps elaborate on this point?
- Deprecate mixing Arrow types and Numpy types in any operation
I think this point is a good suggestion that we could definitely explore further as this is something that we would be more likely to get consensus on
- Add some global configuration API,
set_option("type_system", "legacy" | "pyarrow"), that configures the "default" type system as either NaN semantics with NumPy or NA semantics with Arrow (with the default being"legacy")
This suggestion would make sense to me, especially if we moved in the direction of better separation of the dtype systems. It would help potentially address the issues of complexity in transition paths and compatibility of types, the concerns you raised about PDEP-14 and the issues raised in PDEP-13
Comment From: datapythonista
Thanks Simon for the feedback
I think this may be a big ask at this time
I think we agree on many things, and it's the details, and that discussing too many related topics at once makes the discussion very complex. What I'm proposing is to start with a PDEP with all the topics we can agree on, and a general roadmap that doesn't go too much into details.
Our vision is to move to a pandas that doesn't expose the underlying data storage, but so far it should move to using PyArrow? I don't think there have been strong opinions against this (maybe I misunderstood). If we can agree on this, that's a huge step in my opinion.
Do we consider pd.NA based missing values the ideal, and NaN something we consider good for backward compatibility? Feels like this is what most people believe (again, maybe I just misunderstood).
Should we have a global flag to enable the typing system that we consider unstable but closer to the "final" one we'd like to have? I think everybody agrees on this.
Should we use funds so we have progress in making the PyArrow types more stable and feature complete? I assume there is agreement. Should we start by numeric types, strings, dates and categorical maybe? I guess we can find an agreement on this.
So, I don't think it's a big ask. We can leave for other PDEPs any topic that happens to be too controversial at this point, and still agree on plenty of things. And if we have a document with a good enough roadmap, I think there will be big advantages:
- You and Brock can start working with the funds we've already got in the top priorities
- We will be able to have focused discussions, that don't need to deal with total uncertainty and keep reopening discussions all the time
- Both pandas developers and users can manage their expectations and plan accordingly
- We can use the roadmap to request funding, which at present day is not possible because we can't tell what we want to do long term with any level of detail
@jbrockmendel @jorisvandenbossche if any of you (or both) want to work with me in putting together a document with the things we consider we can find agreement with everybody at this point, I'd be happy to do that. Or if anyone else wants to work on this, I'm surely more than happy with it. I just think that Brock and Joris have besides the technical expertise quite a different point of view from mine, so working together may produce something that considers most opinions.
Comment From: simonjayhawkins
@datapythonista writing a PDEP is potentially not so hard these days so long as the discussion has enough material and consensus to work with to produce a useable document for the initial draft.
Hence my reservation to delve into a PDEP "trying to unify all the type system topics into a single PDEP that broadly defines a roadmap for the next steps and final goal."
If you feel that there is enough agreement here to progress to a PDEP then my intention was not to hinder that.
To save you the effort of writing a PDEP we could instead perhaps at this stage get feedback on an AI generated one from the discussion so far in the first instance?
You will perhaps understand, after reading on, my comments regarding keeping discussions focused on the discussion title and that a future using nullable types should perhaps be in a different thread.
Below is a draft PDEP—Pandas Development Enhancement Proposal—that synthesizes the discussion from this GitHub thread into a coherent future direction for pandas. This draft aims to provide a roadmap for unifying pandas’ type system around a PyArrow-backed framework while offering an opt‑in transition path via a global configuration API.
PDEP‑XX: Unified Pandas Type System—Transitioning to PyArrow‑Backed Dtypes as Default
1. Abstract
This proposal outlines a phased roadmap to move pandas toward a unified type system that uses the PyArrow engine as its default backend. The primary goal is to modernize pandas by aligning column storage with a modern, cross‑language Arrow type system, thereby addressing longstanding challenges with missing value semantics and interoperability. In parallel, we will retain compatibility with the legacy NumPy‑based types during a multi‐release transition period via an explicit global configuration option. Ultimately, this migration will deliver a cleaner type system that supports both NA semantics and improved performance across operations.
2. Motivation
The current pandas architecture is rooted in NumPy‑centric types, which present several challenges:
- Inconsistent missing value semantics: There is confusion between np.nan (legacy NumPy behavior) and pd.NA (pandas’ native missing value indicator).
- Interoperability: With the rise of Apache Arrow as a cross‑language in‑memory format, it is natural to consider a backend that supports modern I/O and Arrow’s robust type system.
- Long‑term vision: If pandas were designed from scratch, a PyArrow‑backed system would be the natural choice. Significant work on experimental ArrowDtypes (e.g., for strings, numerics, and categories) has already set the stage for this evolution.
This proposal seeks to establish a clear, step‑by‑step strategy for adopting PyArrow as the default while managing the vast code base and diverse user expectations.
3. Goals and Principles
- Phased Transition: Allow current users to keep the legacy behavior while providing a controlled pathway for future migrations.
- Global Configuration: Introduce a global flag (e.g., via
pandas.options) that lets users toggle the “default” type system between the legacy (NumPy with NaN) and the new PyArrow‑backed system. - Unified Semantics: Eliminate ambiguities by standardizing on NA semantics (using
pd.NA) for the new Arrow‑backed types. - Interoperability and Extensibility: Maintain strict boundaries between the new Arrow‑based types and the legacy types so that they are not inadvertently mixed in operations.
- Backward Compatibility: Ensure that users who are not ready for the change can continue to use the legacy system by pinning to older pandas releases or explicitly setting the global option.
4. Proposal Details
4.1 Global Configuration Option
- New Option: Introduce a configuration parameter, for example:
python pandas.options.type_system = "legacy" # alternatives: "legacy", "pyarrow" - Default Behavior: Initially, the default will be set to
"legacy"to preserve current semantics. Users who wish to experiment or migrate early will set the option to"pyarrow". - Impact on Constructors and Functions: All constructors (e.g.,
pd.Series(),pd.DataFrame(), I/O functions) will consult this option. When"pyarrow"is selected, new columns are instantiated using Arrow-backed Extension Arrays based on the ArrowDtype.
4.2 Transition Roadmap
The migration path spans multiple major releases:
- Pandas 3.x – Introduction and Deprecation Phase:
- Implementation:
- Implement the new Arrow‑backed dtypes with complete adherence to the ExtensionArray/ExtensionDtype interface.
- Integrate PyArrow as an optional backend for core dtypes (e.g., numeric, string, categorical, interval, period).
- Deprecation Warnings:
- Begin deprecating legacy handling of missing values in the context of Arrow‑backed types (i.e., allow only
pd.NAfor missing values in this mode). - Warn users when mixing legacy and Arrow‑based types in operations, as mixing may lead to inconsistent results.
- Begin deprecating legacy handling of missing values in the context of Arrow‑backed types (i.e., allow only
-
Testing and Stability:
- Ensure that comprehensive test suites verify expected behavior under both settings.
- Identify and document any performance regressions (e.g., in axis‑1 operations) that need addressing.
-
Pandas 4.x – Warning and Migration Enforcement:
- More Aggressive Deprecations:
- Emit warnings for legacy behavior in Arrow‑mode operations.
- Gradually restrict mixing between the two type systems by raising warnings and, eventually, deprecation errors.
-
Enhanced Documentation and Migration Guides:
- Provide detailed guides on how to update code bases from using
np.nantopd.NAwhen operating with Arrow‑backed types. - Clarify behavior differences (e.g., transposition returning numpy object arrays) and propose workarounds.
- Provide detailed guides on how to update code bases from using
-
Pandas 5.x – Full Transition:
- Default Switch:
- Change the default global option value to
"pyarrow". - Continue warning about legacy type usage, with planned removal of legacy handling in a future release.
- Change the default global option value to
- Removal of Legacy Defaults:
- Eventually retire the legacy type system from core pandas (or spin it off into an external package for users who need it).
- Performance and Compatibility:
- Finalize optimization efforts for vectorized operations, ensuring that the new system performs equivalently (or better) than the legacy system.
4.3 Handling Platform and Operational Concerns
- Extension Array Consistency:
- Ensure that Arrow‑backed Extension Arrays (e.g.,
ArrowExtensionArray) implement all required operations without relying on Cython bridging for key operations. - Mixing Third‑Party Arrays:
- Define clear semantics for operations that involve a mix of PyArrow‑backed dtypes and third‑party extension types.
- Document these boundaries to avoid unexpected type coercions.
- API Changes:
- Minimize breaking changes by providing interim deprecation cycles and detailed migration guides.
- Consider the use of explicit type constructors to allow fine‑grained control when necessary.
5. Implementation Considerations
- Backward Compatibility:
- Users not yet ready for the migration can reliably use the legacy system by either pinning to an older release or explicitly setting
pandas.options.type_system = "legacy". - Testing and Benchmarking:
- Develop rigorous benchmarks comparing numeric performance (e.g., axis‑1 operations, arithmetic) and ensure that the Arrow‑backed types are tested under real‑world workloads.
- Collaboration with Funding and Community:
- Recognize that successful implementation depends on both core developer time and external contributions/funding.
- Establish a clear list of deliverables and milestones that can be revisited as new contributions are secured.
- Documentation and Communication:
- Engage with the wide pandas user community (via conferences, mailing lists, GitHub discussions) to gather continuous feedback throughout the transition.
6. Risks and Mitigation
- Potential for User Confusion:
- Mitigation: Clear documentation, comprehensive deprecation warnings, and migration guides.
- Performance Regressions:
- Mitigation: Optimize and test critical operators; provide opt‑in for early adapters to help surface issues before full adoption.
- Inadequate Funding or Development Resources:
- Mitigation: Maintain backwards compatibility through the global configuration option and consider spinning the legacy system as an independent package if necessary.
7. Final Remarks and Call for Community Involvement
This proposal represents a holistic vision for a more modern, consistent pandas type system—one that leverages PyArrow’s strengths for internal storage and interoperability while allowing a gradual transition from legacy practices. The outlined roadmap acknowledges the enormous efforts already invested, respects the need for backward compatibility, and offers a clear path for continuous evolution. We invite further feedback and encourage interested core developers and community members to help refine and eventually lead this transition.
Additional Considerations:
- Example Usage:
A simple demonstration of how the global configuration affects DataFrame construction:
```python import pandas as pd pd.options.type_system = "pyarrow" # switch to the new system
df = pd.DataFrame({
"integers": pd.Series([1, 2, pd.NA], dtype=pd.ArrowDtype("int64")),
"strings": pd.Series(["a", "b", pd.NA], dtype=pd.ArrowDtype("string"))
})
print(df)
```
- Community Roadmap Sessions:
Organizing virtual roadmap meetings or hackathons might catalyze development efforts, address outstanding technical challenges (such as object dtype behavior during transposition), and further synchronize community priorities.
- Future Research:
The proposal opens further inquiry into using Arrow’s capabilities (such as zero‑copy transformations and interoperability with other Arrow‑based libraries) within pandas. Investigating these avenues could maximize performance and broaden the library’s ecosystem reach.
This draft is intended as a starting point for discussion. Feedback—especially concrete examples from real‑world usage and performance benchmarks—will be vital to refine and ensure successful adoption of this new direction for pandas.
Comment From: jbrockmendel
Simon and Marc, please slow down. I woke up to at least ten screens of text from you two. Every bit of it means more to catch up on for the people who haven’t participated yet.
On Fri, Jun 13, 2025 at 5:19 AM Simon Hawkins @.***> wrote:
simonjayhawkins left a comment (pandas-dev/pandas#61618) https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2970218008
@datapythonista https://github.com/datapythonista writing a PDEP is potentially not so hard these days so long as the discussion has enough material and consensus to work with to produce a useable document for the initial draft.
Hence my reservation to delve into a PDEP "trying to unify all the type system topics into a single PDEP that broadly defines a roadmap for the next steps and final goal."
If you feel that there is enough agreement here to progress to a PDEP then my intention was not to hinder that.
To save you the effort of writing a PDEP we could instead perhaps at this stage get feedback on an AI generated one from the discussion so far in the first instance?
You will perhaps understand, after reading on, my comments regarding keeping discussions focused on the discussion title and that a future using nullable types should perhaps be in a different thread.
Below is a draft PDEP—Pandas Development Enhancement Proposal—that synthesizes the discussion from this GitHub thread into a coherent future direction for pandas. This draft aims to provide a roadmap for unifying pandas’ type system around a PyArrow-backed framework while offering an opt‑in transition path via a global configuration API.
PDEP‑XX: Unified Pandas Type System—Transitioning to PyArrow‑Backed Dtypes as Default 1. Abstract
This proposal outlines a phased roadmap to move pandas toward a unified type system that uses the PyArrow engine as its default backend. The primary goal is to modernize pandas by aligning column storage with a modern, cross‑language Arrow type system, thereby addressing longstanding challenges with missing value semantics and interoperability. In parallel, we will retain compatibility with the legacy NumPy‑based types during a multi‐release transition period via an explicit global configuration option. Ultimately, this migration will deliver a cleaner type system that supports both NA semantics and improved performance across operations. 2. Motivation
The current pandas architecture is rooted in NumPy‑centric types, which present several challenges:
- Inconsistent missing value semantics: There is confusion between np.nan (legacy NumPy behavior) and pd.NA (pandas’ native missing value indicator).
- Interoperability: With the rise of Apache Arrow as a cross‑language in‑memory format, it is natural to consider a backend that supports modern I/O and Arrow’s robust type system.
- Long‑term vision: If pandas were designed from scratch, a PyArrow‑backed system would be the natural choice. Significant work on experimental ArrowDtypes (e.g., for strings, numerics, and categories) has already set the stage for this evolution.
This proposal seeks to establish a clear, step‑by‑step strategy for adopting PyArrow as the default while managing the vast code base and diverse user expectations. 3. Goals and Principles
- Phased Transition: Allow current users to keep the legacy behavior while providing a controlled pathway for future migrations.
- Global Configuration: Introduce a global flag (e.g., via pandas.options) that lets users toggle the “default” type system between the legacy (NumPy with NaN) and the new PyArrow‑backed system.
- Unified Semantics: Eliminate ambiguities by standardizing on NA semantics (using pd.NA) for the new Arrow‑backed types.
- Interoperability and Extensibility: Maintain strict boundaries between the new Arrow‑based types and the legacy types so that they are not inadvertently mixed in operations.
Backward Compatibility: Ensure that users who are not ready for the change can continue to use the legacy system by pinning to older pandas releases or explicitly setting the global option.
Proposal Details 4.1 Global Configuration Option
New Option: Introduce a configuration parameter, for example:
pandas.options.type_system = "legacy" # alternatives: "legacy", "pyarrow"
- Default Behavior: Initially, the default will be set to "legacy" to preserve current semantics. Users who wish to experiment or migrate early will set the option to "pyarrow".
- Impact on Constructors and Functions: All constructors (e.g., pd.Series(), pd.DataFrame(), I/O functions) will consult this option. When "pyarrow" is selected, new columns are instantiated using Arrow-backed Extension Arrays based on the ArrowDtype.
4.2 Transition Roadmap
The migration path spans multiple major releases:
1.
Pandas 3.x – Introduction and Deprecation Phase: - Implementation: - Implement the new Arrow‑backed dtypes with complete adherence to the ExtensionArray/ExtensionDtype interface. - Integrate PyArrow as an optional backend for core dtypes (e.g., numeric, string, categorical, interval, period). - Deprecation Warnings: - Begin deprecating legacy handling of missing values in the context of Arrow‑backed types (i.e., allow only pd.NA for missing values in this mode). - Warn users when mixing legacy and Arrow‑based types in operations, as mixing may lead to inconsistent results. - Testing and Stability: - Ensure that comprehensive test suites verify expected behavior under both settings. - Identify and document any performance regressions (e.g., in axis‑1 operations) that need addressing. 2.
Pandas 4.x – Warning and Migration Enforcement: - More Aggressive Deprecations: - Emit warnings for legacy behavior in Arrow‑mode operations. - Gradually restrict mixing between the two type systems by raising warnings and, eventually, deprecation errors. - Enhanced Documentation and Migration Guides: - Provide detailed guides on how to update code bases from using np.nan to pd.NA when operating with Arrow‑backed types. - Clarify behavior differences (e.g., transposition returning numpy object arrays) and propose workarounds. 3.
Pandas 5.x – Full Transition: - Default Switch: - Change the default global option value to "pyarrow". - Continue warning about legacy type usage, with planned removal of legacy handling in a future release. - Removal of Legacy Defaults: - Eventually retire the legacy type system from core pandas (or spin it off into an external package for users who need it). - Performance and Compatibility: - Finalize optimization efforts for vectorized operations, ensuring that the new system performs equivalently (or better) than the legacy system.
4.3 Handling Platform and Operational Concerns
- Extension Array Consistency:
- Ensure that Arrow‑backed Extension Arrays (e.g., ArrowExtensionArray) implement all required operations without relying on Cython bridging for key operations.
- Mixing Third‑Party Arrays:
- Define clear semantics for operations that involve a mix of PyArrow‑backed dtypes and third‑party extension types.
- Document these boundaries to avoid unexpected type coercions.
API Changes:
- Minimize breaking changes by providing interim deprecation cycles and detailed migration guides.
- Consider the use of explicit type constructors to allow fine‑grained control when necessary.
Implementation Considerations
Backward Compatibility:
- Users not yet ready for the migration can reliably use the legacy system by either pinning to an older release or explicitly setting pandas.options.type_system = "legacy".
- Testing and Benchmarking:
- Develop rigorous benchmarks comparing numeric performance (e.g., axis‑1 operations, arithmetic) and ensure that the Arrow‑backed types are tested under real‑world workloads.
- Collaboration with Funding and Community:
- Recognize that successful implementation depends on both core developer time and external contributions/funding.
- Establish a clear list of deliverables and milestones that can be revisited as new contributions are secured.
Documentation and Communication:
- Engage with the wide pandas user community (via conferences, mailing lists, GitHub discussions) to gather continuous feedback throughout the transition.
Risks and Mitigation
Potential for User Confusion:
- Mitigation: Clear documentation, comprehensive deprecation warnings, and migration guides.
- Performance Regressions:
- Mitigation: Optimize and test critical operators; provide opt‑in for early adapters to help surface issues before full adoption.
Inadequate Funding or Development Resources:
- Mitigation: Maintain backwards compatibility through the global configuration option and consider spinning the legacy system as an independent package if necessary.
Final Remarks and Call for Community Involvement
This proposal represents a holistic vision for a more modern, consistent pandas type system—one that leverages PyArrow’s strengths for internal storage and interoperability while allowing a gradual transition from legacy practices. The outlined roadmap acknowledges the enormous efforts already invested, respects the need for backward compatibility, and offers a clear path for continuous evolution. We invite further feedback and encourage interested core developers and community members to help refine and eventually lead this transition.
Additional Considerations:
- Example Usage: A simple demonstration of how the global configuration affects DataFrame construction:
import pandas as pdpd.options.type_system = "pyarrow" # switch to the new system df = pd.DataFrame({ "integers": pd.Series([1, 2, pd.NA], dtype=pd.ArrowDtype("int64")), "strings": pd.Series(["a", "b", pd.NA], dtype=pd.ArrowDtype("string")) })print(df)
- Community Roadmap Sessions: Organizing virtual roadmap meetings or hackathons might catalyze development efforts, address outstanding technical challenges (such as object dtype behavior during transposition), and further synchronize community priorities.
- Future Research: The proposal opens further inquiry into using Arrow’s capabilities (such as zero‑copy transformations and interoperability with other Arrow‑based libraries) within pandas. Investigating these avenues could maximize performance and broaden the library’s ecosystem reach.
This draft is intended as a starting point for discussion. Feedback—especially concrete examples from real‑world usage and performance benchmarks—will be vital to refine and ensure successful adoption of this new direction for pandas.
— Reply to this email directly, view it on GitHub https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2970218008, or unsubscribe https://github.com/notifications/unsubscribe-auth/AB5UM6BPTAWEKZQLQRZ5VD33DK6VRAVCNFSM6AAAAAB66AB4EKVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDSNZQGIYTQMBQHA . You are receiving this because you were mentioned.Message ID: @.***>
Comment From: Dr-Irv
Below is a draft PDEP—Pandas Development Enhancement Proposal—that synthesizes the discussion from this GitHub thread into a coherent future direction for pandas. This draft aims to provide a roadmap for unifying pandas’ type system around a PyArrow-backed framework while offering an opt‑in transition path via a global configuration API.
Have to admit that this draft looks pretty good as a starting point. Nice application of AI generated content
Comment From: simonjayhawkins
Have to admit that this draft looks pretty good as a starting point. Nice application of AI generated content
yeah, it's not necessarily technically correct so I don't think the community can dispense with the core team just yet!
However, it gives people a chance to challenge the Abstract, Motivation and Goals and Principles, because we need to get this right before we spend too much time on the other sections.
Comment From: jbrockmendel
Shower thought: should we make the ArrowDtype arrays immutable? The __setitem__ implementation is already a bit of a non-performant hack, and in a free-threading world working with immutable arrays may offer optimization options?
Comment From: jbrockmendel
Instead of One PDEP To Rule Them All, I think we can whittle down a few decisions (and actual implementation) that can be made independently:
1) If/when pyarrow is required (xref #58623), deprecate all the non-pyarrow nullable dtypes/arrays. 2) Revive the pd.FooDtype part of PDEP-13 (xref #58455) 3) Deprecate NaN treatment in constructor/setitem/csv for pyarrow dtypes. 4) Implement pyarrow object dtype (xref #61599 but i dont think this needs a PDEP) 5) Implement pyarrow support for non-numeric Index subclasses (discussed in PDEP-13 xref #58455) 6) Agree that if we change the defaults it will be with a deprecation cycle via a global option like #61620
I think these can all be decided on independently and significantly narrow down the scope of the remaining decision(s). In some cases they would allow for some implementation work to go forward.
Comment From: simonjayhawkins
@jbrockmendel
we have a roadmap item for the EA interface that ends with ...
We'll do this by cleaning up pandas' internals and adding new methods to the extension array interface.
I'm not sure off the top of my head what was planned, but also having a discussion on this front could perhaps address the questions such as "what happens if i want to include a 3rd party EA column that isn't pyarrow-based?" and "should we make the ArrowDtype arrays immutable?"
Would this need the other decisions to be fleshed out more first or could this be done in parallel, i.e. a 7th decision?
I think it could also be a benefit on the path to converting those roadmap items to PDEPs.
Comment From: jorisvandenbossche
Replying to some older comments/questions. First, on the question about non-pyarrow dtypes in a "pyarrow-mode world":
[Simon] How would we avoid numpy object dtype in a arrow only dtype system? ... [Brock] in a pyarrow-mode world, what happens if i want to include a 3rd party EA column that isn't pyarrow-based?
Personally, I think we will never be strictly-speaking (py)arrow-only, because we indeed want to keep an object dtype (for which it currenty does not make much sense to use pyarrow instead of numpy object dtype, I think?), and because we want to keep 3rd party EAs use whatever array under the hood they want. This is for me another reason I would like us to stop about talking about "pyarrow dtypes". It are "pandas dtypes", which at some point might happen to use pyarrow under the hood for most of our default dtypes.
And whether we eventually want to use pyarrow, IMO we should decide that on a case by case basis. For string dtype, there is a very clear benefit (and we are already going to use it by default for 3.0). For some other (potentially new) dtypes like decimal as well. Others can probably stay numpy-based, with object dtype being the obvious (only?) built-in example (geopandas is another example as third-party EA). And then for other dtypes, I think the trade-off might be less clear (numeric, maybe also datetime), and we should probably do some tests comparing feature coverage and performance for some common workflows. Quite likely we might end up using pyarrow for almost all dtypes, I just don't think being "strict" about this should be our goal.
@jorisvandenbossche can you elaborate on what work has actually been done on using PyArrow as a backend to the existing pandas nullable types. Is it only the StringArray so far?
As far a I know, it is indeed only done for StringArray. For other dtypes, all improvements have been focused on the ArrowDtype variant.
[Matt] Secondarily, I would like a world where pandas has the Arrow type system with NA semantics and the legacy (NaN) Numpy type system which is completely independent from the Arrow type system (e.g. a user cannot mix the two in any way) ... Deprecate mixing Arrow types and Numpy types in any operation
(and some follow-up comments of Simon about that)
Personally (which is probably clear from supporting the PDEP-13 logical dtypes idea), I would not like pandas to have independent sets of dtypes which are essentially separate worlds (long term). I do think we should deprecate the numpy dtypes at some point (which would follow from my PDEP-16 about using NA consistently for all dtypes, which I should revive), and then when we have deprecated/removed those dtypes, we essentially also have removed mixing of arrow/nullable and numpy dtypes. But so I would like us (long term) to avoid this mixing by only having one set of interoperable dtypes, instead of just deprecating the mixing but keeping the numpy dtypes separate.
(also note that we would still have to keep some mixing working, because I am assume that we would keep something like ser + arr working?)
If it is about mixing a numpy-based nullable dtype with a arrow-based nullable dtype, I personally would keep supporting that if we decide to support both variants (like we have now for the string dtype, but we might not need that for all dtypes)
[Matt] Deprecate NaN as a missing value for Arrow types ... [Brock] Deprecate NaN treatment in constructor/setitem/csv for pyarrow dtypes.
I also would like to do that eventually, but I think the order is important here: I would first work towards making those dtypes the default (with compatibility for using NaN), and only afterwards deprecate using NaN. As Simon also mentioned, already deprecating NaN in the pyarrow-based dtypes might make it less straightforward for users to switch. Assume we would make a pyarrow-float based dtype using NA that becomes the default in pandas 4.0, while the default float dtype right now is numpy dtype with NaN. To have people make the switch (and opt in to the new dtype to test their code), I think it would be easier at that point that whenever they explicitly use NaN (eg in constructor, or setitem, ..) to mean a missing value, that this keeps working for a while. Doing that switch of default dtypes will already have lots of breaking changes and require updates. One argument could be to then just do it all together if it are a lot of changes anyway, but I would personally try to minimize the disruption as much as possible by deprecating certain aspects only later (because that can then actually go through a deprecation cycle, while with the global option opt-in, that is more difficult to do).
(but this are the details of how to deal with a NaN to NA change that I wanted to (and still should) add to PDEP-16)
Comment From: jbrockmendel
Joris makes a good point-- hopefully this is a reasonable paraphrase-- that we should focus less on backends and more on semantics.
but I think the order is important here [...] try to minimize the disruption as much as possible
Completely agree that "how to handle the migration" is the crux of the issue, since I think we're all on the same page about preferred end-state behavior. I don't have a strong opinion on whether the single-step vs multi-step deprecation is more disruptive. I'm going to put together a POC for allowing users to do it either way.
Comment From: datapythonista
Instead of One PDEP To Rule Them All,
To be clear, I didn't propose a PDEP to decide all the details of the open discussions. What I proposed is a minimal PDEP with everything that can be agreed easily. Leaving any topic that requires discussion to existing and new PDEPs.
To the best of my knowledge, things like adding a flag to use pyarrow types, or fix existing bugs in pyarrow numeric, categorical or string types is something everything is happy with. And if such agreement existed in the form of a PDEP you (Brock) and Simon could do work on those things with the available funding, and we could request additional funding for it.
After two years of open discussions and almost no actual work on the typing transition, I personally think the project will benefit from any decision that allows people to move forward. Even if that decision is not yet the exact transition to the desired missing values semantics.
But well, it's you and Simon who are blocked. So just sharing my opinion. I'll let you or anyone else lead this effort and decide if you want to make decisions asap, or continue discussing everything for months.
Comment From: simonjayhawkins
But well, it's you and Simon who are blocked. So just sharing my opinion. I'll let you or anyone else lead this effort and decide if you want to make decisions asap, or continue discussing everything for months.
Anything that requires a PDEP has an initial draft period (duration undetermined), a 60 day official discussion period and a 15 day voting period. So any work that requires an approved PDEP has at least a 3 month lead time?
Comment From: WillAyd
I think its worth reconsidering our stance that funds cannot be used to work on drafting a PDEP. The drafting, researching, and responding to feedback on a PDEP is extremely time consuming and doing that all unfunded is challenging.
I think it would be a good use of funds if the core team internally decided on general topics and created small grants to fund PDEP proposals, even if they ultimately end up not accepted
Comment From: Dr-Irv
I think it would be a good use of funds if the core team internally decided on general topics and created small grants to fund PDEP proposals, even if they ultimately end up not accepted
Good idea, but I think we want the finance team to be involved in these decisions as well.
Comment From: mroeschke
FWIW, the early model of ArrowDtype almost followed a variant of the StringDtype model (https://github.com/pandas-dev/pandas/pull/46972). I have come to like the benefits of the current ArrowDtype (probably with some bias), but I'll argue my case in a different forum.
Surely, this is that forum? (From the title of the discussion)
@simonjayhawkins @jbrockmendel I assumed that we would have a separate issue discussing the technical implementation details of how to move to PyArrow types by default, but might as well do it here too.
Thinking back, I suppose I wouldn't mind having a class-per-type, e.g. pandas.DatetimeType, model that points to the implementation of 1 type system, e.g. pandas.ArrowDtype, as long as we're moving to a world where all pandas types can only point to 1 type system (at a time).
Additionally, my initial hesitation of having a class-per-type is locking pandas into a fixed set of types; whereas, pyarrow (or other type system) may continue to expand supported types such as uuid or json_. With just using pandas.ArrowDtype, these newer types are represented automatically in pandas. In the class-per-type model, how would we imagine supporting/representing these types?
Overall, I'm glad we're all generally in agreement in the path forward.
Reflecting on the journey to change the default string implementation and the limited engineering time the team has these days, whatever plan we craft should hopefully avoid saying "X change will happen in Y version" (despite me doing that in my ideal timeline). Moving forward, I think there's value in making more frequent releases, and I would not like to block a release due to work that hasn't been completed yet.
Comment From: simonjayhawkins
Reflecting on the journey to change the default string implementation and the limited engineering time the team has these days, whatever plan we craft should hopefully avoid saying "X change will happen in Y version" (despite me doing that in my ideal timeline). Moving forward, I think there's value in making more frequent releases, and I would not like to block a release due to work that hasn't been completed yet.
Yes, we need to learn from the experiences of PDEP-10 and PDEP-14 that comiting to specific releases is perhaps not helpful and that implementation plans should be expressed in terms of phases, approval gates and readiness reviews.
Comment From: simonjayhawkins
4. Implement pyarrow object dtype (xref PDEP-18: Nullable Object Dtype #61599 but i dont think this needs a PDEP)
@jbrockmendel
I'm keeping it open for now for two reasons. PDEP-1 states
- Adding a new data type has impact on a variety of places that need to handle the data type. Such wide-ranging impact would require a PDEP.
- Once a PDEP is accepted, any contributions can be made toward the implementation of the PDEP, with an open-ended completion timeline.
I've started the PDEP not with the intention of implementing this straightaway but because the PDEP process necessitates a long lead time before implementation can begin. I assume that 3.0 will be released long before PDEP-18 is accepted.
Maybe the outcome of other ongoing discussions will in fact mean that the PDEP is not necessary.
Comment From: simonjayhawkins
@jorisvandenbossche
Personally, I think we will never be strictly-speaking (py)arrow-only, because we indeed want to keep an object dtype (for which it currenty does not make much sense to use pyarrow instead of numpy object dtype, I think?),
PDEP-18 was opened with the intent of describing a pandas nullable dtype only, however, that discussion moved to a PyArrow backed one and then this issue proposing a PyArrow only world. I'll move forward with PDEP-18 once there is a bit more clarity and consensus here. That may mean starting with the AI generated PDEP to get clarity on the rough direction of pandas. (I'm not a proponent of either at this time as this discussion is very useful) and "Rejected PDEPs are as useful as accepted PDEPs, since there are discussions that are worth having, and decisions about changes to pandas being made."
Comment From: simonjayhawkins
@jorisvandenbossche
This is for me another reason I would like us to stop about talking about "pyarrow dtypes". It are "pandas dtypes", which at some point might happen to use pyarrow under the hood for most of our default dtypes.
@jbrockmendel
Joris makes a good point-- hopefully this is a reasonable paraphrase-- that we should focus less on backends and more on semantics.
we have a dtype_backend argument in read_*, convert_dtypes and to_numeric.
valid parameters are numpy_nullable and pyarrow
along with the traditional numpy dtypes this gives us, de facto, 3 type systems.
do you find this api helpful in clarifying the future of pandas as a pandas dtype system?
Comment From: simonjayhawkins
@mroeschke
Thinking back, I suppose I wouldn't mind having a class-per-type, e.g.
pandas.DatetimeType, model that points to the implementation of 1 type system, e.g.pandas.ArrowDtype, as long as we're moving to a world where all pandas types can only point to 1 type system (at a time).
Yes, we effectively have 3 at this time. We allow mixing through the constructors and dtype_backend argument of some functions. I suppose a global flag would be a good solution to this problem and disallow creating mixed dtypes. This would need api changes to remove dtype_backend and api changes to constructors to disallow explicit dtype construction and all construction through a string alias and not allow backend in that also. so string[pyarrow] would not be allowed. we would have just one string alias, "string" and the flag would control the "backend". Of course, context managers could be used to circumvent this.
Additionally, my initial hesitation of having a class-per-type is locking pandas into a fixed set of types; whereas, pyarrow (or other type system) may continue to expand supported types such as
uuidorjson_. With just usingpandas.ArrowDtype, these newer types are represented automatically in pandas. In the class-per-type model, how would we imagine supporting/representing these types?
It does appear that "having a class-per-type" is less flexible and more maintenance. I wonder whether the arrow style approach would actually be more helpful to the community that are already using arrow. Creating pandas types that wrap that could be an extra learning curve for these users? Presenting a PDEP to the community proposing the Arrow dtypes would surely get a clearer picture.
Comment From: jbrockmendel
do you find [the dtype_backend parameter] helpful in clarifying the future of pandas as a pandas dtype system?
No. The main benefit to an all-pyarrow (or pyarrow-whenever-feasible) world would be that we could get rid of these parameters along with code and docs and tests etc.
I don't care-- and users shouldn't have to care/know-- about how the data is stored. We care about the behavior and performance. This was a big part of PDEP13.
As it is, the backends have non-trivially distinct behaviors, which makes the term "backend" a misnomer that I think is liable to cause confusion for users. My attempt to change that name didn't gain traction #58214.
Side note, I don't understand why a parameter would exist to "clarify the future" of anything.
Comment From: simonjayhawkins
I'm leaning towards proposing the removal, instead of renaming, of this functionality and moving the "pyarrow dtype" behind a flag to totally isolate it from the rest of pandas. I would propose we doing the same for the pandas nullable types but I think this is a bigger ask since these types have been available for so long.
I think the "pyarrow types" would actually evolve faster if behind a flag as there would be less issues with maintaining backwards compatibility. Behind a flag, with a all singing all dancing warning that their use is experimental and likely to change at any time, would actually allow breaking api changes when using these dtypes such as the return type of loc with duplicates in the index.
Comment From: mroeschke
We care about the behavior and performance As it is, the backends have non-trivially distinct behaviors
My only cautionary comment here is that I hope we don't end up having to greatly augment a behavior that a type system doesn't natively support, e.g. NaN as a missing value for PyArrow types, in the name of behavior alignment. Of course maybe this is a non issue if we move towards just 1 type system.
Comment From: simonjayhawkins
@mroeschke @datapythonista
In https://github.com/pandas-dev/pandas/pull/58623#issuecomment-2954040181 @rhshadrach wrote
I too am concerned about making PyArrow a hard dependency. Some of that is based on not understanding how many users we will leave without an upgrade path, and some of it is based on what maintenance PyArrow itself will receive (I've heard the situation there is not great, but don't have a good understanding).
Now rather than seek clarification in that thread now that that issue has moved to a vote, i've reposted here if PyArrow maintenance and future is something that needs to be considered.
Comment From: simonjayhawkins
@jorisvandenbossche
Quite likely we might end up using pyarrow for almost all dtypes, I just don't think being "strict" about this should be our goal.
yes, we have funding that can be used for a strict outcome, but that doesn't mean we have to go that route if the team in not in agreement. However, taking the scenic route is currently not funded. If the pyarrow world is not approved by the team, IIUC the sponsors are happy with a global flag that allows existing pandas code to just work with the "pyarrow dtypes". This is currently a separate issue #61620 to discuss that and we would probably end up with some dtype mapping (like PDEP-13, but not blocked by it) and some other breaking changes that apply to that dtype system only, like ignoring dtype_backend and always using "pyarrow". Comparing performance etc is not relevant on this more direct journey since the jit compilers have already been optimized for Arrow types and the 1d nature of the arrays is not relevant.
Comment From: jbrockmendel
Comparing performance etc is not relevant on this more direct journey since the jit compilers
IIUC that would only be relevant for users who use bodo? i.e. a tiny fraction of users? I'd love to be wrong about this.
IIUC the sponsors are happy with a global flag
The sponsors don't get a vote. Besides the funding bodo has offered is an order of magnitude less than it would take to implement what they're asking for.
Comment From: simonjayhawkins
IIUC that would only be relevant for users who use bodo? i.e. a tiny fraction of users? I'd love to be wrong about this.
The performance would be the same for the current users of the "arrow dtypes" and improved for the bodo users. There is no downside here?
The sponsors don't get a vote. Besides the funding bodo has offered is an order of magnitude less than it would take to implement what they're asking for.
of course. That's why we want to offer them something that both the team and sponsors agree on.
Comment From: jbrockmendel
The performance would be the same for the current users of the "arrow dtypes" and improved for the bodo users. There is no downside here?
I think you're forgetting the 99% of users who are neither.
Comment From: simonjayhawkins
I think you're forgetting the 99% of users who are neither.
Isolating the type systems as @mroeschke suggests does not affect the 99% of users.
The "arrow dtypes" do not need to support NaN as a missing value indicator and be compatible with the existing dtypes if they are only used by 1% of the userbase.
We have been considering implementing a complex logical dtype system and considering augmenting behaviors that a type system doesn't natively support in the name of behavior alignment. Seems like a waste of developer resource.
Maybe there is no value having the "pyarrow types" in core pandas and made available to users at all.
Comment From: Liam3851
If I may, as a user and not a core dev:
If the community wants nullable dtypes by default, they may be less interested in the implementation details or even to some extent the performance.
Does the community want nullable dtypes by default? I can certainly say that I and those I work with care more about the performance, particularly keeping block 2-D operations and numpy compatibility without loss of performance. I don't use any current nullable dtypes other than the datetime dtypes and have no particular interest in doing so, though faster strings will be very nice when our firm gets to do our 2.3 upgrades. I do see where having nullability in ints is nice for some use cases but wouldn't break the world for it (and have it, we don't use it at all). We're going through the 2.x upgrade cycle at last at my workplace and the excitement I'm hearing is primarily about performance benefits from the numpy 2 series.
In the end as a user, as jbrockmendel suggested above, I care about behavior and performance. I could sell the cost of a behavior change from np.nan to pd.NA (or equivalent) globally including for floats in all our systems' codebases, given sufficient deprecation warnings, if it provides value in ease of use or performance. What I wouldn't be able to sell internally (or accept myself) is the cost of doing a global code change AND a performance loss, including on numpy or scipy functions on DataFrames, including 2-D operations. In that case I'd be stuck on 2.3 indefinitely, and I would genuinely fear 2.3 could effectively be the final version of pandas.
I realize there are many constraints on those of you who have given so much of your time, and to the extent something simplifies your lives all the better. I just wanted to raise my concern with the above comment and some of the comments above that "3.0 may not be the best version ever" or "we create a new repository... call it npandas"-- like, some of this sounds like exactly a recipe for python-3 style non-adoption, it would be exceedingly hard to do any upgrade in the face of such a change.
Comment From: jbrockmendel
Isolating the type systems as @mroeschke suggests does not affect the 99% of users.
OK. I thought you were referring to the OP idea of switching users over by default.
Comment From: jbrockmendel
@Liam3851 thanks for your comment. The PDEP16 approach
a) Lets users put a missing sentinel in int/bool dtypes without an upcast b) is the maximally backwards-compatible way to achieve a) c) retains 2D blocks for performance
Comment From: simonjayhawkins
Thanks @Liam3851 for the comments.
Don't take anything in this thread too seriously at this point, we are "green light thinking" and trying to get consensus within the team on the general roadmap direction to reduce conflict further down the road. Any changes will be proposed through a PDEP and the community will have plenty of opportunity to participate.
However, your comments will also be useful in this process. Thanks.
Comment From: Liam3851
@jbrockmendel @simonjayhawkins Thanks very much for your responses, I greatly appreciate your consideration and all your (and everyone's) efforts on pandas!
Comment From: simonjayhawkins
Isolating the type systems as @mroeschke suggests does not affect the 99% of users.
OK. I thought you were referring to the OP idea of switching users over by default.
sorry Brock, yes I had digressed into the other issue.
Comment From: simonjayhawkins
I've posted a few questions today in support of this proposal however in the meantime here are the major concerns so far (AI generated) that need further discussion to mitigate the risks to this proposal if we are to make a serious PDEP proposal.
-
Maturity & reliability gaps
• Many core pandas operations (groupby, joins, setitem, rolling/window, etc.) still work against NumPy-backed arrays with dedicated Cython paths. ArrowExtensionArray often falls back to slower conversions or has subtle behavioral differences, risking silent bugs in real-world pipelines. Finishing out full feature parity and hardening all edge cases will take multiple release cycles. -
Performance trade-offs
• Benchmarks show that even simple arithmetic onint32[pyarrow]can be several times slower than NumPy’sint32(or pandas’ own nullableInt32) and memory overhead can be higher too. Until PyArrow’s compute kernels are on par with NumPy+vectorized C code, users of numeric-heavy workloads will see regressions. -
Feature-coverage holes
• Specialized ufuncs, window functions, date/time methods, and custom C extension hooks in pandas currently assume NumPy-based buffers. Arrow arrays either need custom bindings or must round-trip through NumPy, adding complexity and maintenance burden for every new pandas feature (see #32265 blocking PDEP-16). -
Backward-compatibility & migration complexity
• Switching the default dtype system is a breaking change: any code that relies onnp.nansemantics, mixed NumPy/nullable silos, or CSV/Parquet readers will need unpicking. Aligning on missing-value semantics (pd.NA vs np.nan) via PDEP-16, rolling out deprecation warnings, offering ause_arrow=Falseflag, and giving users time to adapt demands a measured, multi-release deprecation cycle—rushing it risks churn and confusion. -
Added dependency/install friction
• Making PyArrow a hard requirement complicates installs in constrained environments (embedded systems, minimal Docker images) and raises the maintenance surface for pandas’ CI/matrix. An alternative (PDEP-10) is to raise the minimum NumPy to 2.x and leverage NumPy’s ownStringDtypewithout forcing PyArrow everywhere. -
Mixed-type ecosystem & third-party EAs
• pandas will always need an object dtype (for arbitrary Python objects) and must interoperate with other third-party ExtensionArrays (e.g. GeoPandas, custom EAs). Locking into a strict Arrow-only narrative makes the type system rigid and undermines future extensibility. It’s cleaner to treat “pyarrow” as one backend among several, chosen on a per-dtype basis. -
Limited core resources
• There’s only a handful of maintainers actively paid to work on pandas. Jumping the default without dedicated bandwidth to flesh out, test, document, and support all the new Arrow-backed behaviors will leave half-baked dtypes in production—counter to pandas’ reliability guarantees.
Comment From: Dr-Irv
I've posted a few questions today in support of this proposal however in the meantime here are the major concerns so far (AI generated) that need further discussion to mitigate the risks to this proposal if we are to make a serious PDEP proposal.
Wow. I read the above 7 lines and don't see that making pyarrow a default is something we should consider for quite a while. We need better performance, and more development resources. And the comment about moving to numpy 2.0 and using numpy strings instead, makes me wonder if we just do that, not require pyarrow, and keep limping along with pyarrow support for now.
Comment From: simonjayhawkins
Wow. I read the above 7 lines and don't see that making
pyarrowa default is something we should consider for quite a while.
Not my intention to kill the proposal, it is AI generated so not fully correct and requested to be negative to purposely extract the points that need adequate consideration if we are presenting a PDEP to the community. It's the gist of the comments not the explicit detail that we need to address.
Comment From: jorisvandenbossche
(sidenote: if it is not entirely correct, I am not sure how useful it is to leave the post up like that without editing/correcting, or at least I would add a big disclaimer at the top of your post. For example, in the second point about performance, the "several times slower" for simple arithmetic seems quite unlikely to me without providing benchmarks)
Comment From: simonjayhawkins
For example, in the second point about performance, the "several times slower" for simple arithmetic seems quite unlikely to me without providing benchmarks)
https://stackoverflow.com/questions/75820285/questions-on-arrow-support-in-pandas
The best part of the exchange is
Is there (a written) plan or roadmap to improve the performance of native extended dtype and arrow dtypes in pandas?
There is active work to improve this going on, but there is no specific or detailed roadmap at the moment, no (but it is something we as pandas developers should do).
So good that we are now doing that.
Comment From: simonjayhawkins
@Dr-Irv
We need better performance, and more development resources. And the comment about moving to numpy 2.0 and using numpy strings instead, makes me wonder if we just do that, not require pyarrow, and keep limping along with pyarrow support for now.
That is indeed a credible solution. IIRC we had this discussion in PDEP-10 and if PDEP-10 is rejected or deferred, we could indeed review this discussion again.
Comment From: simonjayhawkins
@jorisvandenbossche
(sidenote: if it is not entirely correct, I am not sure how useful it is to leave the post up like that without editing/correcting, or at least I would add a big disclaimer at the top of your post.
I'm not prepared to edit/correct AI generated content in this context to avoid introducing bias.
Obviously if we produce a PDEP following this discussion then if we use AI generated content then fact checking will need to be thorough. When I created PDEP-18, I had the framework in seconds and then spent the best part of the day re-working it.
I do not think that fact checking is strictly necessary here as we throw ideas around.
I'm extremely cautious about introducing too much AI generated content into the discussion but in this case after much engagement from the core team I wanted to create a status update and perhaps a natural break to allow others following the discussion to catch up https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2970608082
Comment From: WillAyd
For example, in the second point about performance, the "several times slower" for simple arithmetic seems quite unlikely to me without providing benchmarks)
https://stackoverflow.com/questions/75820285/questions-on-arrow-support-in-pandas
I caution us against playing the benchmark game like this, because arguments can be cherry picked from both sides. It also misses the larger point that we are talking here mostly about PyArrow storage; in terms of computation, we would have the flexibility to pick whatever we choose.
For the example you cited, if we don't like the pyarrow.compute implementation of power or if its missing an optimization for say the power of 2, there's no reason why you couldn't zero copy from pyarrow to numpy (as long as missing data is not a concern, which it isn't in that benchmark)
In [25]: pa_arr = pa.array(range(1_000_000), type=pa.int32())
In [26]: np_arr = np.array(range(1_000_000), dtype="int32"))
In [29]: %timeit pc.power(pa_arr, 2)
2 ms ± 110 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
In [30]: %timeit np_arr ** 2
152 μs ± 3.45 μs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
In [31]: %timeit pa_arr.to_numpy() ** 2
153 μs ± 4.55 μs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
3. Feature-coverage holes • Specialized ufuncs, window functions, date/time methods, and custom C extension hooks in pandas currently assume NumPy-based buffers. Arrow arrays either need custom bindings or must round-trip through NumPy, adding complexity and maintenance burden for every new pandas feature (see
This point continues to be exaggerated because you can zero copy these types from pyarrow to numpy to maintain the same performance we have in all of our custom code. There is of course, more that can be developed with PyArrow types, but that's just an opportunity for future enhancement
5. • Making PyArrow a hard requirement complicates installs in constrained environments (embedded systems, minimal Docker images) and raises the maintenance surface for pandas’ CI/matrix.
I still really struggle with this comment - at what point in our history have embedded systems been a target platform for pandas?
5. An alternative (PDEP-10) is to raise the minimum NumPy to 2.x and leverage NumPy’s own
StringDtypewithout forcing PyArrow everywhere.
This is an extreme amount of work and at odds with the point of limited resources. It would also limit our zero copy potential with the ecosystem
Comment From: simonjayhawkins
Thanks @WillAyd for the feedback, really useful.
With respect to the goal, in my mind, of this discussion is to find a path that unites the team behind a common vision. https://github.com/pandas-dev/pandas/pull/61599#issuecomment-2957091486
A vision without a plan is just a dream.
So I expect that some form of path would be documented in a PDEP when we have agreement. The funding and resources is a big issue but so the plan would provide clarity to the community and be used to solicit funding.
So I think, be sure to correct me if I wrong, @jbrockmendel and @jorisvandenbossche would like a path that would need significant effort whereas others are happy with perhaps a simpler, less costly, path. You could argue for both approaches as the first gives the impetus to find significant financial backing which would be easier with a well document plan.
With regard to, say, the Numpy string dtype, I believe that there has been in the past significant interest from the community. So in that case a PDEP would perhaps be useful since "Once a PDEP is accepted, any contributions can be made toward the implementation of the PDEP, with an open-ended completion timeline."
Comment From: jbrockmendel
So I think, be sure to correct me if I wrong, @jbrockmendel and @jorisvandenbossche would like a path that would need significant effort whereas others are happy with perhaps a simpler, less costly, path
Matt has suggested a path. Is that what you're referring to? Pretty much everything else I've seen is pie-in-the-sky.
Comment From: simonjayhawkins
Pretty much everything else I've seen is pie-in-the-sky.
because of lack of funding? or technically?
Comment From: jbrockmendel
Pretty much everything else I've seen is pie-in-the-sky.
because of lack of funding? or technically?
I'm thinking of plans to the effect of either "everything will default to pyarrow in 3.0" or "have a flag to go to all-pyarrow in 3.0", either of which are months of work (which, let's face it, are being asked of me and Joris). If there are other plans I'm missing that constitute "perhaps a simpler, less costly, path" please point them out.
Comment From: simonjayhawkins
in https://github.com/pandas-dev/pandas/issues/61618#issuecomment-3005988338 @mroeschke said
Reflecting on the journey to change the default string implementation and the limited engineering time the team has these days, whatever plan we craft should hopefully avoid saying "X change will happen in Y version"
I'm in agreement with this when it comes to "the plan" and happy for it to be presented "with an open-ended completion timeline."
Comment From: mroeschke
I'm in agreement with this when it comes to "the plan" and happy for it to be presented "with an open-ended completion timeline."
Definitely agreed.
I would hope development and functionality could continue to exist in a parallel track to pandas default behaviors today, and decisions if/when to switch default behaviors comes when the team feels ready not necessarily by a certain date/version.
Comment From: simonjayhawkins
For the example you cited, if we don't like the pyarrow.compute implementation of power or if its missing an optimization for say the power of 2, there's no reason why you couldn't zero copy from pyarrow to numpy (as long as missing data is not a concern, which it isn't in that benchmark)
As I understood it, part of the justification for requiring PyArrow is for the zero-copy benefits as mentioned in "Immediate User Benefit 3: Interoperability" of PDEP-10.
Now, I've probably misunderstood, but if it is straightforward to zero-copy back and forth between NumPy and PyArrow, the benefits of zero-copy are only for a subset of use cases?
Comment From: simonjayhawkins
Matt has suggested a path. Is that what you're referring to? Pretty much everything else I've seen is pie-in-the-sky.
@jbrockmendel would you be happy if Matt's plan was used as the basis of a PDEP (perhaps using https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2970218008) or are there significant points that you feel need further discussion before proceeding.
"Our workflow was created to support and enable a consensus seeking process" as stated in PDEP-1, but I had pushed against @datapythonista creating a PDEP until we had had more discussion here in the first instance.
Now, it maybe just my interpretation of PDEP-1, but a PDEP is opened in draft status in the first instance. I assume that this is to get a temperature check from the team that there is general consensus on the concept and then moved to the official discussion to more involve the community at large.
A PDEP is likely to fail if any/many core team members disagree with the concept.
As you've said, "Pretty much everything else I've seen is pie-in-the-sky", so at this point we have Matt's plan and plenty of discussion following to enhance that plan and PDEP-16 which is orthogonal?
Comment From: simonjayhawkins
Wow. I read the above 7 lines and don't see that making
pyarrowa default is something we should consider for quite a while.
@Dr-Irv
Following @WillAyd comments https://github.com/pandas-dev/pandas/issues/61618#issuecomment-3012788054, it looks like we should be able to somewhat mitigate some of those concerns/risks so that they are not considered blockers.
Comment From: jorisvandenbossche
Now, I've probably misunderstood, but if it is straightforward to zero-copy back and forth between NumPy and PyArrow, the benefits of zero-copy are only for a subset of use cases?
Indeed, this depends on the data type and the values. For numeric data types without missing values, conversion between numpy and pyarrow is zero-copy (and for Will's example of using a numpy ufunc, it is sufficient to zero-copy convert the actual data, if if there are missing values present). But for other data types, strings being the typical example, the conversion is not zero-copy. And using Arrow memory under the hood in pandas for all data types would improve the (zero-copy) interoperability with other dataframe libraries.
Comment From: simonjayhawkins
So my take from those comments is that the performance argument in favor of NumPy and against PyArrow are only for heavy numeric (potential 2D) workloads without missing values and as @WillAyd said, "I caution us against playing the benchmark game like this"
@WillAyd has suggested using NumPy compute after zero-copy to maybe emolliate those concerns. So, by definition, I think that effectively supports the idea of pandas nullable types and being PyArrow backed, which I interpret differently from Matt's plan.
Comment From: WillAyd
@WillAyd has suggested using NumPy compute after zero-copy to maybe emolliate those concerns.
Just to be clear I am also not suggesting we do this universally. There may also be cases where PyArrow has a faster implementation.
I don't think its worth iterating every single computation and its possibilities in advance, but I hope we more generally recognize that we have a ton of flexibility with zero copy types (int, float, datetime values without missing values) in the computation layer.
So, by definition, I think that effectively supports the idea of pandas nullable types and being PyArrow backed, which I interpret differently from Matt's plan.
Yes I am strongly in favor of this approach. My expectation is that users that have been using the pandas nullable types have done so because they need missing value support, not because they care about the inner implementation. Most of these can be very easily retrofitted to use PyArrow behind the scenes. In that case, users wouldn't have to change a line of code and we still accomplish the goal of this issue.
Comment From: jbrockmendel
would you be happy if Matt's plan was used as the basis of a PDEP (perhaps using https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2970218008) or are there significant points that you feel need further discussion before proceeding.
Side-note: I should mention I didn't read the PDEP text- I skip over most AI-generated stuff since I don't think it provides content. (AKA I'm an old grouch)
I could live with The Matt Plan as-is, but it wouldn't be my first choice. My plan would look more like
1) Change/deprecate the arrow float to consistently distinguish NaN from NA (xref #61732) (this is part of Matt's plan too)
2) Change/deprecate the numpy-nullable float to consistently not distinguish (xref #61708) (this is part of PDEP16)
3) Deprecate the numpy dtypes. (Just noticed this isn't in the Matt plan which surprised me. @mroeschke is that intentional?)
3a) This will require weaning users off of e.g. =np.int64 specification and == np.int64 checks in favor of something like pd.int64(...) like in PDEP13. This is non-trivial!
4) When deprecating the numpy dtypes, the future behavior is to give the not-distinguish dtypes (xref #61716), as this is maximally backward-compatible. (part of PDEP16)
4a) That deprecation will include a flag to opt-in to the future behavior.
4b) That flag can also allow for opting in to the further-future behavior with the yes-distinguish dtypes.
5) Acknowledge that if we actually get this far, a good deal of time has passed and we'll have a lot of user feedback.
6) Deprecate the not-distinguish dtypes, moving everyone over to the yes-distinguish (which happen to be pyarrow)
This is similar to the Matt plan but in a different order and with a PDEP16 step in between (but with an option to skip it). The only part of the Matt plan that I actively disagree with is
Deprecate mixing Arrow types and Numpy types in any operation
As Joris said, we will presumably keep series+some_numpy_array working, which means continuing to support operations between backends. I would be OK with deprecating support for operations between different semantics. I just don't care at all about different backends with the same semantics.
Contra @WillAyd, we should do some serious benchmarking to see where the pyarrow dtypes perform better/worse than the numpy-based ones. If we need to convert-compute-convert here and there it is no big deal, but if we need to do that in a ton of places then implementing that is basically the same as keeping the numpy backend. And for use cases like https://github.com/pandas-dev/pandas/issues/61618#issuecomment-3009225525, zero-copy conversion may be non-trivial.
Comment From: WillAyd
And for use cases like #61618 (comment), zero-copy conversion may be non-trivial.
FWIW a use case like that is probably a good test of the tensor canonical extension type that pyarrow offers. See https://arrow.apache.org/docs/format/CanonicalExtensions.html#fixed-shape-tensor
I have no experience with the type so can't offer much guidance beyond what is documented there, but assuming we use that type, it would be a shift from our current state for axis=1 operations
Comment From: mroeschke
Regarding @jbrockmendel's plan
Deprecate the numpy dtypes. (Just noticed this isn't in the Matt plan which surprised me. @mroeschke is that intentional?)
Does this mean purely being able to specify dtype=np.int64 and replacing it with dtype=pd.int64(type=np.int64) or similar to get the existing behavior (e.g. np.nan as the missing value), or also removing all the old semantics of the legacy numpy dtype system?
I didn't include this in my original plan because I imagined a pandas steady state to have 2 independent type systems
- The existing, default numpy type system with all it's current semantics (e.g.
np.nanas the missing value) - An Arrow backed type system with NA as the missing value
(The above type systems can have a common public API but a way to specify which one you want)
And with this paradigm is why I stated (and you probably disagree with)
Deprecate mixing Arrow types and Numpy types in any operation
because I would not be fond of defining the interoperability rules between an Arrow backed type system with NA and the existing numpy type system with np.nan/pd.NaT as the missing values.
My backing belief from my original plan is that the existing numpy type system is flexible and works for a lot of users, but more advance users like the standardization of the Arrow type system and are used to the pandas API, so why not allow either option? And given their differences is why I am also OK with both having different semantics.
I agree that it would be nicer for users to only interact with high level pandas type system that is implemented by our choosing for consistent semantics, towards PyArrow by default in this thread, but I just get nervous of the augmentations for a type that isn't well-defined by Arrow (e.g. object)
Comment From: jbrockmendel
Does this mean purely being able to specify dtype=np.int64 and replacing it with dtype=pd.int64(type=np.int64) or similar to get the existing behavior (e.g. np.nan as the missing value), or also removing all the old semantics of the legacy numpy dtype system?
That could be allowed, yes. The main thing is to disambiguate between "I very specifically want a numpy dtype" vs "i want some int64 dtype and this is what the old docs said to do". Then once the new usage is in place we can deprecate the default for type in this example. In the plan I specified we would later deprecate the numpy option entirely, but I could be convinced to leave it and just make it non-default.
because I imagined a pandas steady state to have 2 independent type systems
I get where you're coming from here, but I think @jorisvandenbossche is going to push for all-nullable dtypes until the end of time. Also 2 independent type systems is at least 1 more than the median user is going to understand.
because I would not be fond of defining the interoperability rules between an Arrow backed type system with NA and the existing numpy type system with np.nan/pd.NaT as the missing values.
Need to give this some thought. To the extent that we can reasonably say we're doing it because they have different semantics I'd be fine with that.
Comment From: mroeschke
Also 2 independent type systems is at least 1 more than the median user is going to understand.
Yeah I understand the additional mental burden that world would put on users. Also, I wouldn't be entirely disappointed if we go with a single, all-nullable dtype system backed by however we chose instead since it would probably be an easier mental model for users.
I'm just nervous about the PyArrow + NumPy object + augmentations it will take to define a "consistent" experience since the exercise feels similar to how pandas originally forced np.nan to be a missing value even though it wasn't intended to be a missing value. (I don't think it will nearly be as bad though since Arrow behavior and types satisfies a majority of pandas use cases that we want to move towards)
Comment From: WillAyd
because I would not be fond of defining the interoperability rules between an Arrow backed type system with NA and the existing numpy type system with np.nan/pd.NaT as the missing values.
Can you clarify the concern on this? What complicated rules do you foresee?
Comment From: mroeschke
Can you clarify the concern on this? What complicated rules do you foresee?
Even today when doing some an op between two Series with and pd.ArrowDtype and a np.dtype that returns a single array-like result, e.g. binary op or merge, defining and enforcing consistent result type rule account for null representation on each side, possible left or right side operand preference permuted across available types in that domain is quite onerous, all which is hopefully evident to users too.
It's not impossible and maybe (hopefully) behaves in some consistent way today, but I feel like its simpler and more predictable if one was required to stay in a particular type system.
Comment From: WillAyd
Is that problem specific to the Arrow types or does it show itself in the pandas extension types as well? My (assumedly wrong) interpretation of your comment is that an op between an array like:
[1, <MISSING>, 3]
and
[4, 5, 6]
is problematic today, but I'm still not clear why
Comment From: mroeschke
Is that problem specific to the Arrow types or does it show itself in the pandas extension types as well?
I wouldn't really classify this as a problem, just a lack of enthusiasm to make and maintain rules to make [value, <MISSING>] and [value, <MISSING>], where one is Arrow and one is NumPy, work "predictably"
A similar example to what I'm describing is what we did for the NA vs nan, pyarrow vs python heirarchy with the new string dtype for comparisons https://github.com/pandas-dev/pandas/pull/61138. It's great to have a rule to describe what missing value and type backend you get in the end, but we would need to do this type of exercise again in many more cases if the Arrow types with NA semantics were to interact with the existing numpy types with NaN/NaT semantics
Comment From: WillAyd
Ah OK - cool thanks that helps clarify, and I agree that the fact we had to do that type of ruleset with the string type is unfortunate. However, I think the string types were really unique given their development history, and I don't know that other types would have that same degree of complication:
- INTEGRAL/BOOLEAN types; NumPy doesn't support a missing indicator here, so there is nothing to do
- FLOAT types; this one is complicated but I think was already discussed in PDEP-16 (https://github.com/pandas-dev/pandas/pull/58988#discussion_r1638298747)
- DATETIME64 type; would need to decide between NaT and NA, although I think PDEP-16 should determine that
Comment From: jorisvandenbossche
[Simon] So I think, be sure to correct me if I wrong, @jbrockmendel and @jorisvandenbossche would like a path that would need significant effort whereas others are happy with perhaps a simpler, less costly, path.
Echoing what Brock said above, everything being discussed here (AFAIU) would take significant effort. The only option that would be considerably simpler is essentially the status quo: keep the existing numpy dtypes as the default, and continue to develop the pyarrow dtypes as fully opt-in dtypes.
And I assumed that scenario wasn't really being discussed. However:
[Matt] I didn't include this in my original plan because I imagined a pandas steady state to have 2 independent type systems
- The existing, default numpy type system with all it's current semantics (e.g.
np.nanas the missing value)- An Arrow backed type system with NA as the missing value
I hadn't interpreted your previous comments in that way, so thanks for the clarification. I assumed this discussion was about eventually migrating to have the nullable (pyarrow-based) dtypes as the default (also see the title of this issue), and at that point I assumed the end goal would indeed be to have one system with one set of semantics (around missing values etc).
@mroeschke in your idea of keeping 2 independent type systems, are you then OK with keeping pyarrow optional? Because in the referenced "plan" comment (which I assume is https://github.com/pandas-dev/pandas/issues/61618#issuecomment-2957293486), you listed eventually making pyarrow the default. But if we switch to nullable/pyarrow as the default at some point, I am not sure if it is worth keeping the numpy dtypes long term.
(Brock guessed correctly that I will try to push back on the idea of keeping two independent type systems with different missing value semantics long term. I will write up some more arguments for that tomorrow, but mostly what I care about in this regard is that newcomers to pandas don't have to think about "different type systems" but also get consistent missing value semantics by default. If we make the nullable dtypes the default at some point but still keep numpy as then opt-in, that would be true for most users. So in that sense I could certainly live with that. But, repeating from the previous paragraph, not sure it is then worth keeping the numpy dtypes long term)
Comment From: mroeschke
@WillAyd just to be clear, my concern is in a world where
I imagined a pandas steady state to have 2 independent type systems [Arrow and NumPy]
AND we allowed them to co-mingle. But if move towards single, all-nullable dtype system with our choice of PyArrow/NumPy and NA semantics (which I think you're describing in https://github.com/pandas-dev/pandas/issues/61618#issuecomment-3025654072) this is not a concern.
Comment From: Dr-Irv
However, I think the string types were really unique given their development history, and I don't know that other types would have that same degree of complication:
- INTEGRAL/BOOLEAN types; NumPy doesn't support a missing indicator here, so there is nothing to do
- FLOAT types; this one is complicated but I think was already discussed in PDEP-16 (PDEP-16: Consistent missing value handling #58988 (comment))
The other complication occurs when you might be mixing an INTEGRAL/BOOLEAN type using pyarrow with a FLOAT type using numpy. You have the same mixture of different NA interpretations when doing operations. Doing operations with INTEGRAL And FLOAT is quite common, and, today, if you want reasonable and predictable NA behavior, you have to use the nullable types for both.
Comment From: mroeschke
in your idea of keeping 2 independent type systems, are you then OK with keeping pyarrow optional?
@jorisvandenbossche I would be OK keeping pyarrow optional, but I would still support making the pyarrow backed types the default and users having to opt-out to go back to the existing, default numpy type system in the future. And to reiterate, this would mean both type systems having different semantics, namely missing value semantics.
As described in https://github.com/pandas-dev/pandas/issues/61618#issuecomment-3025218625, I would also support your vision @jorisvandenbossche of a high level type system with consistent NA semantics, as I think my ideal seems to be a minority idea.