A clear and concise description of what the bug is.
How to reproduce the bug
- Enable Feature DRILL_TO_DETAIL
- Connect to MSSQL db and create a table-chart with some group by or a big number chart.
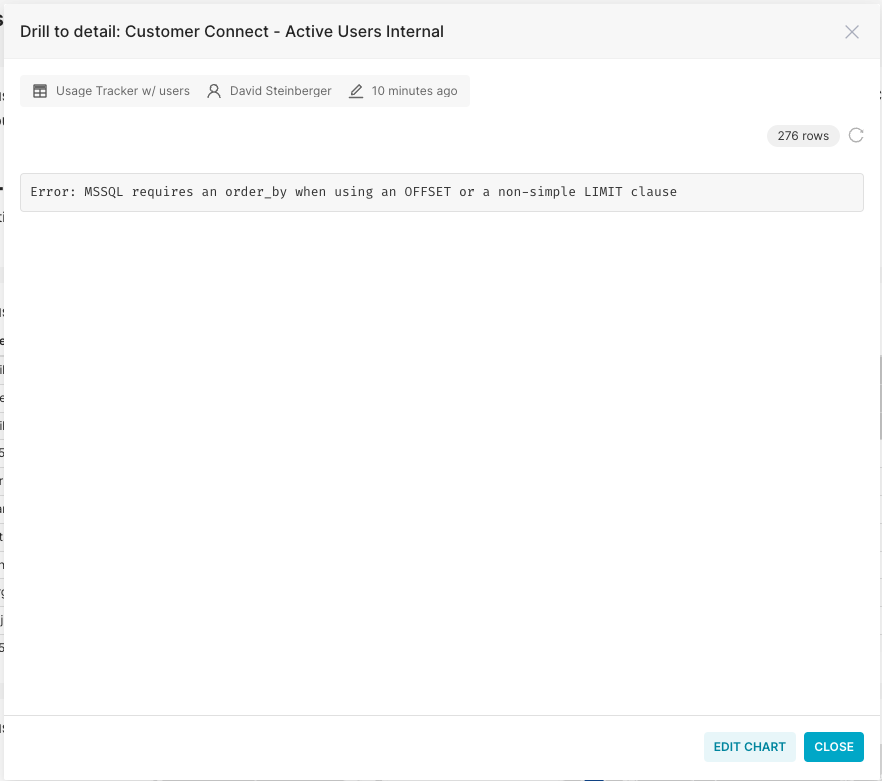
- Add the chart to some dashboard and click on 'Drill to Detail'
- Upon navigating to the second page see the error:
Error: MSSQL requires an order_by when using an OFFSET or a non-simple LIMIT clause
Expected results
Ideally there would be a way to utilize the drill to detail feature with ms sql and be able to browse through the data.
Actual results
Upon navigating to the second page see the error:
Error: MSSQL requires an order_by when using an OFFSET or a non-simple LIMIT clause
Screenshots
Environment
- browser type and version:
Version 0.103.0 - superset version: validated in 3.1.1, originally reported in 2.1.0
- python version:
Python 3.8.16 - node.js version: -
- any feature flags active:
DRILL_TO_DETAIL
Checklist
Make sure to follow these steps before submitting your issue - thank you!
- [x] I have checked the superset logs for python stacktraces and included it here as text if there are any.
- [x] I have reproduced the issue with at least the latest released version of superset.
- [x] I have checked the issue tracker for the same issue and I haven't found one similar.
Additional context
Add any other context about the problem here.
Comment From: rusackas
@sujiplr any insights here, perchance?
Comment From: sfirke
I ran into this today in 2.1.0. I ran SQL Server Profiler, there's no query being made against the DB -- the error message comes from SQL Alchemy.
Comment From: sfirke
This message originates from SQLAlchemy and has been patched in other projects. Resources for anyone who wants to tackle it: https://github.com/gramener/gramex/issues/626#issuecomment-1360878565 has a list of links https://github.com/mrjoes/flask-admin/issues/8 has a fix description, as does https://github.com/flask-admin/flask-admin/issues/582#issuecomment-47697196
Comment From: sfirke
pinging @villebro as you have fixed similar MS SQL Server quirks like this in the past - would this be a quick fix for you or is there another contributor you think would be well-suited to handle it?
Comment From: sujiplr
Hi Guys, Sorry for the delayed response. I was out for few weeks and missed the notification. @dastein1 whether you able to get the SQL for this case. So that can check how currently it's being built before digging more on code level.
Comment From: sfirke
@sujiplr I tried to get the SQL call from SQL Server Profiler but it seems like SQL Alchemy rejects the query from Superset and sends back that error message, nothing makes it to the DB as far as I can tell. So I'm not sure how to get the SQL.
Comment From: sujiplr
@sfirke , let me debug something here
Comment From: dastein1
Any news on that one?
Comment From: edxe
having this same issue. Any alternatives here?
Comment From: nbauneau
We have the same problem without any solution on "drill to detail" feature
Comment From: sfirke
This is still present in 3.0.0.
Comment From: sfirke
I can't figure out where in the codebase this order-by needs to happen. Maybe here: https://github.com/apache/superset/blob/master/superset/common/query_actions.py#L148 ? @zhaoyongjie as the last committer there, do you have an idea for how to fix this bug by ordering the drill-by results?
Comment From: umoers
I also have this bug in version 3.0.0. Is it fixed?
Comment From: zhaoyongjie
@sfirke the "order by" clause adds additional calculation in DB side, so to remove the "order by" was the default behavior when I designed this functionality.
IMO, this limitation should be fixed/implemented but should do it in DB spec.
Comment From: sfirke
@zhaoyongjie that makes sense, thanks for explaining. I would love to help fix this but don't know enough to do it on my own. With the current code, can this be addressed only in the DB spec or is a change to the overall functionality needed to accommodate that?
Comment From: zhaoyongjie
@sfirke The following SQL should be sent to the database when Drill-to-Detail is triggered. This means that it is unknown which column should be ordered.
SELECT *
FROM tbl
LIMIT X
OFFSET Y
I think we need to add logics to determine 1) which column is a sortable column a) primary key? b) custom column if preset ? 2) if or not to apply point 1 in different dataset or database
The above logic should be implemented in different database spec.
Comment From: umoers
I think it is just a issue for MSSQL . We can use order by 1 as default order for MSSQL.
Example for MSSQL: SELECT * FROM tbl ORDER BY 1 OFFSET x ROWS FETCH NEXT y ROWS ONLY
Comment From: nbauneau
@umoers , how to add 'ORDER BY 1' for MSSQL ? =>By adding it to the dataset it does not work.
Comment From: zhaoyongjie
It's a limitation for now, should change codebase.
On Mon, Dec 18, 2023 at 12:26 PM nicolasbauneauhubone ***@***.*** wrote:
@umoers https://github.com/umoers , how to add 'ORDER BY 1' for MSSQL ? =>By adding it to the dataset it does not work.
— Reply to this email directly, view it on GitHub https://github.com/apache/superset/issues/24072#issuecomment-1860213902, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAPMKUV3TTDFRU6FGQ3CPZDYKAR7NAVCNFSM6AAAAAAYDGYXG2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTQNRQGIYTGOJQGI . You are receiving this because you were mentioned.Message ID: @.***>
--
Best regards,
Yongjie
Comment From: umoers
order by 1 is sorting by the 1st column.
I have changed def _get_drill_detail in /opt/superset/lib/python3.11/site-packages/superset/common/query_actions.py as follows:
query_obj.columns = qry_obj_cols query_obj.orderby = [(query_obj.columns[0], True)] <---- insert return _get_full(query_context, query_obj, force_cached)
Comment From: nbauneau
@umoers, great ! it works thank you 👍
Comment From: Purush0th
@umoers @sfirke can be this merged?
order by 1 is sorting by the 1st column.
I have changed def _get_drill_detail in /opt/superset/lib/python3.11/site-packages/superset/common/query_actions.py as follows:
query_obj.columns = qry_obj_cols query_obj.orderby = [(query_obj.columns[0], True)] <---- insert return _get_full(query_context, query_obj, force_cached)
Comment From: sfirke
I believe Yongjie wrote most of that code, what do you think @zhaoyongjie ? We would delete the earlier line query_obj.orderby = [] and add the later line suggested above in bold. If you think this won't have negative effects elsewhere, I'd be happy to test the fix and submit a PR.
Comment From: sfirke
I tried creating this as a pull request #27442, but it's failing a test:
superset/common/query_actions.py:156: error: List item 0 has incompatible type "Tuple[Union[AdhocColumn, str], bool]"; expected "Tuple[Union[AdhocMetric, str], bool]" [list-item]
Did you not experience this when you tried it? Can you advise on a fix? @umoers @Purush0th @nbauneauho
Comment From: sfirke
Update: the above PR now just has a failing Cypress test, I don't understand why but will work on it in the next couple of weeks. Anyone should feel free to dive in.
Comment From: MikeDel001
is there an ETA for this being resolved/deployed as yet? Thanks.
Comment From: sfirke
@MikeDel001 I got stalled on my test environment not being well-suited to running Cypress tests. If anyone is able to tell me what the new test result should be on my PR, I will happily accept that contribution and then this can get merged.
Comment From: alexray92
Thought I was going crazy, this explains it
Comment From: MikeDel001
Are we any closer to a resolution for this?
Comment From: sfirke
No, I haven't worked on this, sorry. Anyone is welcome to help. You could either change the code so that it doesn't alter the result of the end-to-end test, or figure out what the correct result should be for my failing test that has re-ordered the dataframe and then send the update to my PR (or your own fork).
Comment From: rusackas
Anyone is welcome to adopt the PR... I would if I had access to MSSQL 😅
This may be closed due to inactivity at some point, since it's been silent for a few months.
I also can't help but wonder if the SQLGlot migration has made any difference here (probably not) if they want to test this on master
Comment From: sfirke
Agreed anyone is welcome to adopt this! I would ask that we keep it open but I won't get to it in the next month at least.
Comment From: sfirke
I saw Beto introduced a Superset SQL dialect for Firebolt and I wonder if that sort of dialect extension for MSSQL within Superset would be a way to handle this particularly for MSSQL, rather than modifying the main codebase.
Comment From: sfirke
I just submitted a PR that fixes this by editing the db_engine_spec for MSSQL: #34583
Comment From: sfirke
Finalllllllly fixed! Coming to a future release near you.