Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
data = {
'column_A_1': ['A', 'B', 'A', None, 'D', 'B', 'A'],
'column_A_2': ['G', 'F', 'J', 'J', 'J', 'F', 'G'],
'column_A_3': ['6602', '7059', '9805', '3080', '8625', '5741', '9685'],
'column_A_4': ['A', 'B', 'A', None, 'A', None, 'B'],
'column_A_4': ['X', None, 'Y', None, 'Z', 'X', 'Y'],
'column_B_1': ['1', '2', '3', '4', '5', '6', '7'],
'column_C_1': [0, 2, 5, 9, 8, 3, 7],
'column_C_2': [12, 75, None, 93, 89, 23, 97],
'column_C_3': [789, 102, 425, 895, None, 795, None],
'column_C_3': [15886, 49828, None, 9898, 8085, 9707, 8049]
}
df = pd.DataFrame(data)
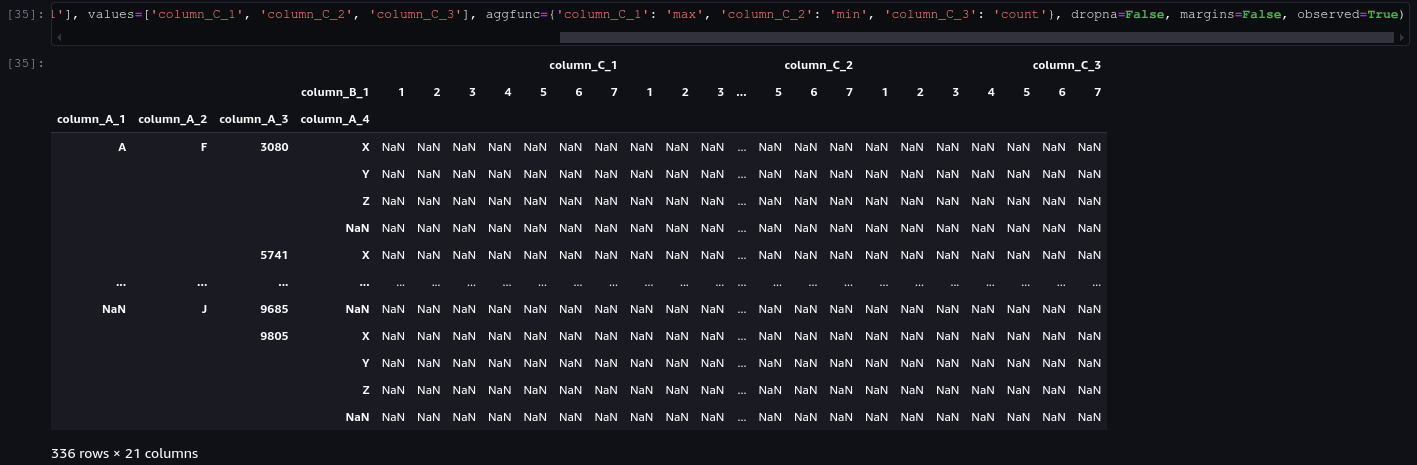
pd.pivot_table(df, index=['column_A_1', 'column_A_2', 'column_A_3', 'column_A_4'], columns=['column_B_1'], values=['column_C_1', 'column_C_2', 'column_C_3'], aggfunc={'column_C_1': 'max', 'column_C_2': 'min', 'column_C_3': 'count'}, dropna=False, margins=False, observed=True)
Issue Description
I have a huge dataset with similar structure to the example. I want to pivot the table grouping using the columns A as the index, the values of the columns B as the new columns and aggregate the values of the columns C. I want all columns B values to appear as columns, even if the entire column is NaN. This is because I want to coalesce values from multiple columns into one. Therefore, the parameter dropna should be equal to False. But the DataFrame I get has 336 rows with impossible combinations. For example, the first row A, F, 3080, X has the entire row filled with NaNs since this combination does not exist.
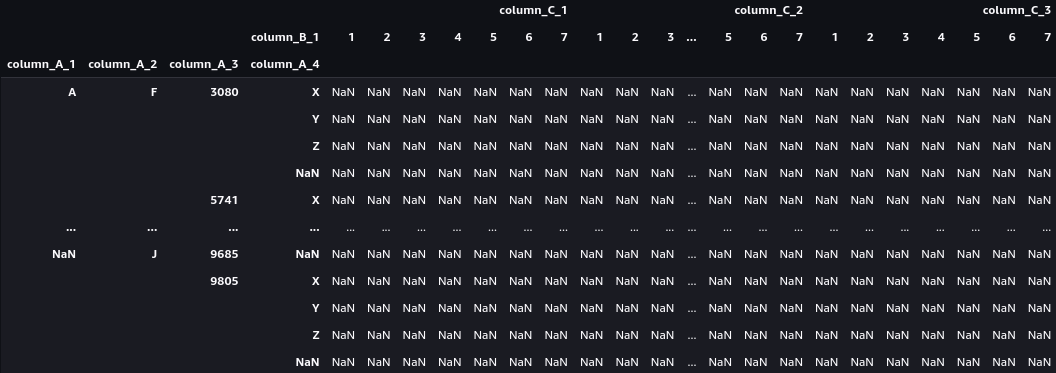
This is a problem because with a small dataset I wouldn't mind. But with a fairly large dataset, numpy returns an error because it has reached the maximum list size. While reading the documentation, I noticed the parameter:

I thought this parameter fixed this issue. Playing around with this parameter, it does not affect the result, it only adds a row. Here is a result of combining these two parameters.
dropna=False, margins=False (Too many rows)
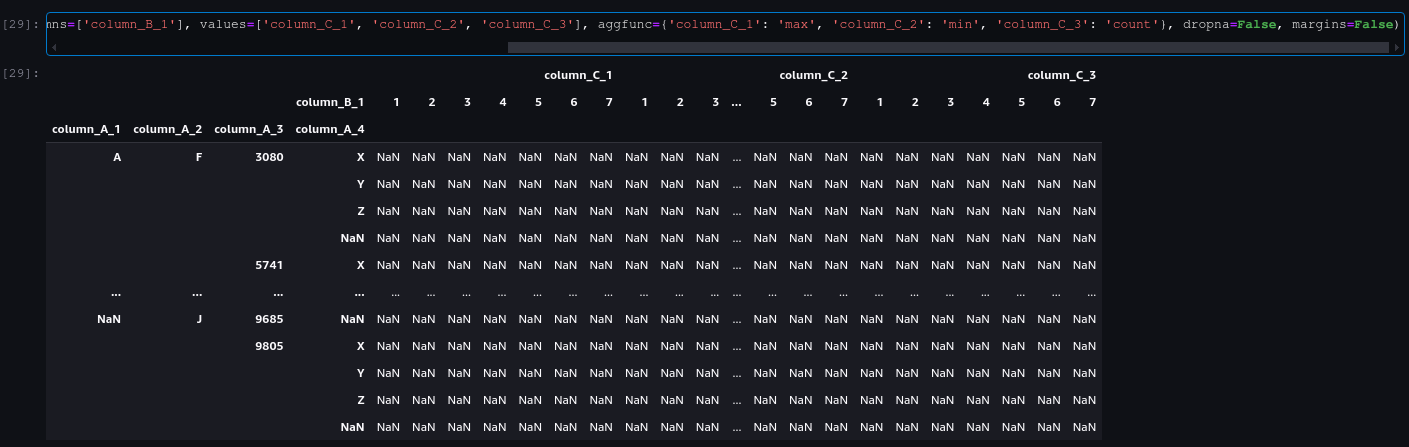
dropna=True, margins=False (Missing Column B values)

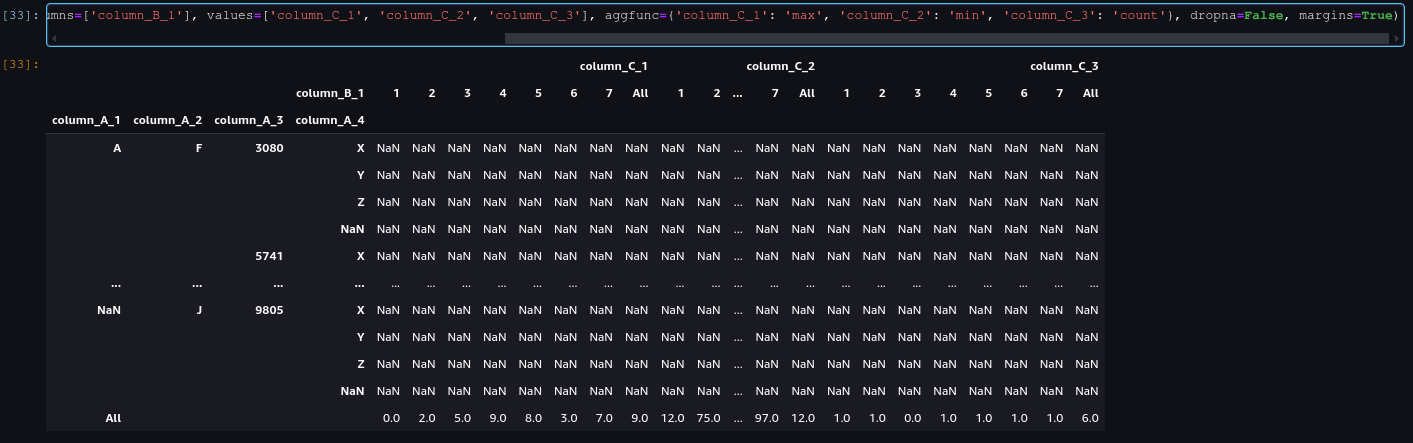
dropna=False, margins=True (Same as dropna=False, margins=False?)
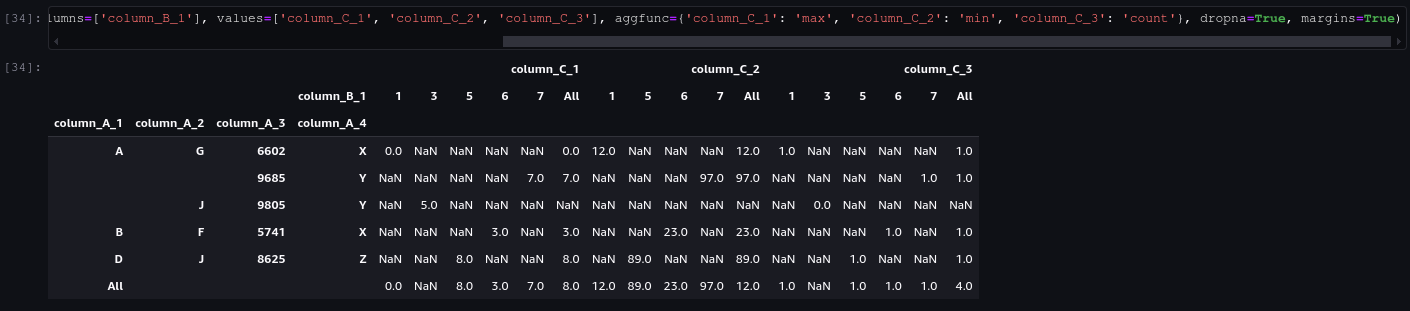
dropna=True, margins=True (Same as dropna=True, margins=False?)
I also noticed this parameter:
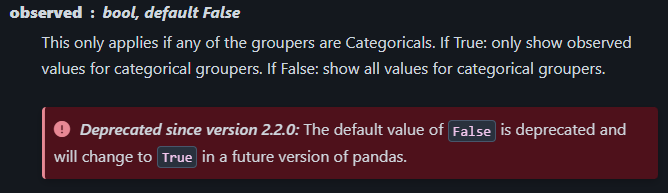
But it is deprecated, and the default value of True seems to be the value that I need. Forcing this parameter to True does not change the result.
Expected Behavior
I expect with the parameter's combination dropna=False, margins=False and observed=True to get all the rows with plausible combinations (like if I was grouping by) and all the columns with column B values and columns C values.
I don't know if this is a bug or if it is the intended way for the pivot table to work and this is an enhancement.
Installed Versions
Comment From: rhshadrach
Thanks for the report! While the default value of observed is deprecated, that option is not planned for removal. It wasn't to clear to me if this was part of your concern.
I expect with the parameter's combination dropna=False, margins=False and observed=True to get all the rows with plausible combinations (like if I was grouping by) and all the columns with column B values and columns C values.
Running your example with these values, I get a result with columns involving
'column_B_1', 'column_C_1', 'column_C_2', 'column_C_3'
and 336 rows. This appears to have all columns and rows that are expected, can you detail how this differs from your desired result?
One thing I'll mention is that you have duplicate keys in the data dictionary provided. I assume that wasn't intentional.
Comment From: hugotomasf
Thank you for your response.
The problem I have is that I don't want to remove the null values from the columns by which I group. That's why I have to keep the parameter dropna=False. The problem is that when this parameter is set to False, all combinations are returned, even if they are not possible. In the example shown, the NaN are taken into account for grouping, but non-existent combinations are added as the first one. There is no row with A in column_A_1 nor F in column_A_2, yet it appears (obviously with all null values). For a small dataset, this is not a problem, but for a massive dataset it is easy to get some memory or size error.
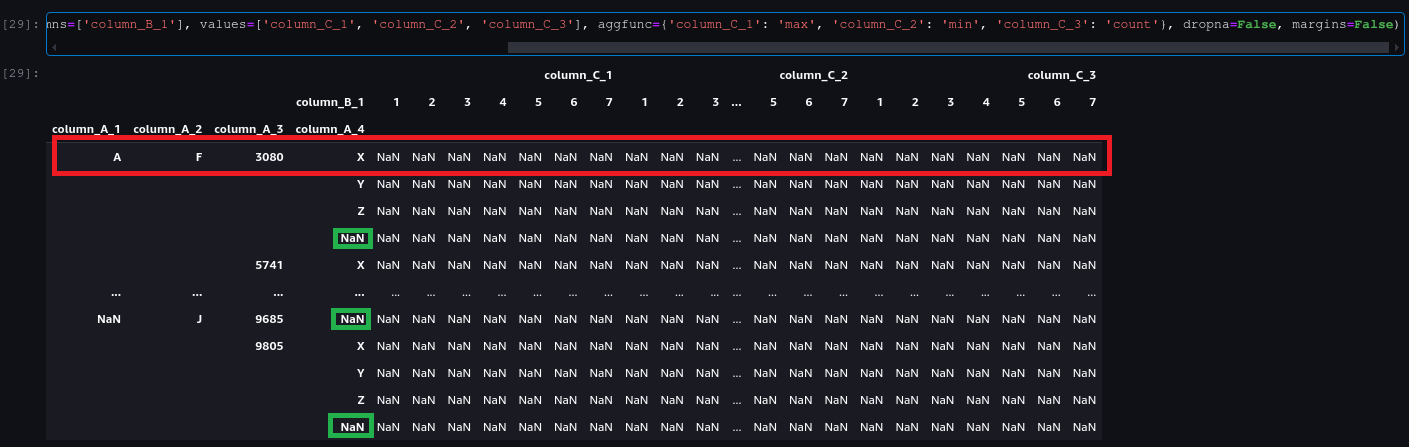
The solution I have found is to replace the null values of 'column_A_1', 'column_A_2', 'column_A_3', 'column_A_4', reset the index and replace again with null. It is a workaround, but it seems like unnecessary steps to me. I don't see the point of returning all combinations when 90% of the rows will have all values set to null.
Comment From: rhshadrach
I see - thanks. In the future, it would be appreciated to make the example minimal, e.g.
data = {
'column_A_1': ['A', 'B'],
'column_A_2': ['C', 'D'],
'column_B_1': ['1', '2'],
'column_C_1': [3, 4],
}
df = pd.DataFrame(data)
This is bullet 1 in https://github.com/pandas-dev/pandas/issues/53521; closing as a duplicated.